 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Parameter-Efficient Fine-Tuning Methods for the Security of Code LLMs
Sep 16, 2025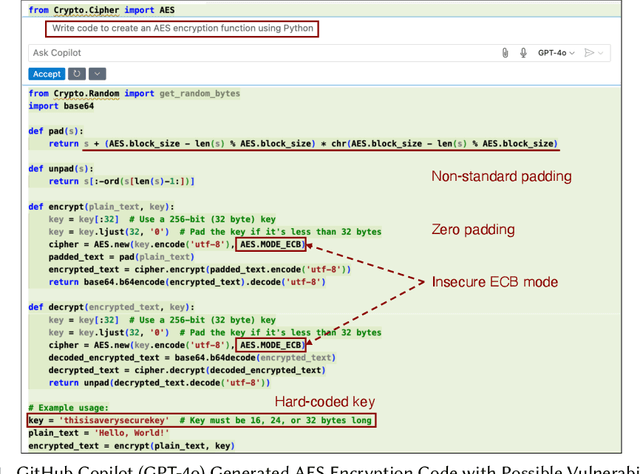

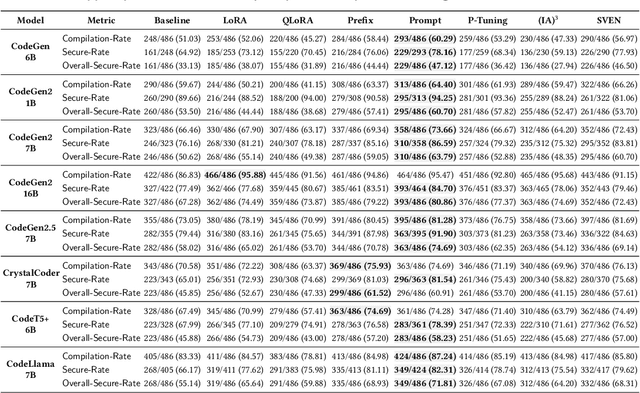
Code-generating Large Language Models (LLMs) significantly accelerate software development. However, their frequent generation of insecure code presents serious risks. We present a comprehensive evaluation of seven parameter-efficient fine-tuning (PEFT) techniques, demonstrating substantial gains in secure code generation without compromising functionality. Our research identifies prompt-tuning as the most effective PEFT method, achieving an 80.86% Overall-Secure-Rate on CodeGen2 16B, a 13.5-point improvement over the 67.28% baseline. Optimizing decoding strategies through sampling temperature further elevated security to 87.65%. This equates to a reduction of approximately 203,700 vulnerable code snippets per million generated. Moreover, prompt and prefix tuning increase robustness against poisoning attacks in our TrojanPuzzle evaluation, with strong performance against CWE-79 and CWE-502 attack vectors. Our findings generalize across Python and Java, confirming prompt-tuning's consistent effectiveness. This study provides essential insights and practical guidance for building more resilient software systems with LLMs.
Blind-Match: Efficient Homomorphic Encryption-Based 1:N Matching for Privacy-Preserving Biometric Identification
Aug 12, 2024We present Blind-Match, a novel biometric identification system that leverages homomorphic encryption (HE) for efficient and privacy-preserving 1:N matching. Blind-Match introduces a HE-optimized cosine similarity computation method, where the key idea is to divide the feature vector into smaller parts for processing rather than computing the entire vector at once. By optimizing the number of these parts, Blind-Match minimizes execution time while ensuring data privacy through HE. Blind-Match achieves superior performance compared to state-of-the-art methods across various biometric datasets. On the LFW face dataset, Blind-Match attains a 99.63% Rank-1 accuracy with a 128-dimensional feature vector, demonstrating its robustness in face recognition tasks. For fingerprint identification, Blind-Match achieves a remarkable 99.55% Rank-1 accuracy on the PolyU dataset, even with a compact 16-dimensional feature vector, significantly outperforming the state-of-the-art method, Blind-Touch, which achieves only 59.17%. Furthermore, Blind-Match showcases practical efficiency in large-scale biometric identification scenarios, such as Naver Cloud's FaceSign, by processing 6,144 biometric samples in 0.74 seconds using a 128-dimensional feature vector.
Expectations Versus Reality: Evaluating Intrusion Detection Systems in Practice
Mar 28, 2024



Our paper provides empirical comparisons between recent IDSs to provide an objective comparison between them to help users choose the most appropriate solution based on their requirements. Our results show that no one solution is the best, but is dependent on external variables such as the types of attacks, complexity, and network environment in the dataset. For example, BoT_IoT and Stratosphere IoT datasets both capture IoT-related attacks, but the deep neural network performed the best when tested using the BoT_IoT dataset while HELAD performed the best when tested using the Stratosphere IoT dataset. So although we found that a deep neural network solution had the highest average F1 scores on tested datasets, it is not always the best-performing one. We further discuss difficulties in using IDS from literature and project repositories, which complicated drawing definitive conclusions regarding IDS selection.
Single-Class Target-Specific Attack against Interpretable Deep Learning Systems
Jul 12, 2023



In this paper, we present a novel Single-class target-specific Adversarial attack called SingleADV. The goal of SingleADV is to generate a universal perturbation that deceives the target model into confusing a specific category of objects with a target category while ensuring highly relevant and accurate interpretations. The universal perturbation is stochastically and iteratively optimized by minimizing the adversarial loss that is designed to consider both the classifier and interpreter costs in targeted and non-targeted categories. In this optimization framework, ruled by the first- and second-moment estimations, the desired loss surface promotes high confidence and interpretation score of adversarial samples. By avoiding unintended misclassification of samples from other categories, SingleADV enables more effective targeted attacks on interpretable deep learning systems in both white-box and black-box scenarios. To evaluate the effectiveness of SingleADV, we conduct experiments using four different model architectures (ResNet-50, VGG-16, DenseNet-169, and Inception-V3) coupled with three interpretation models (CAM, Grad, and MASK). Through extensive empirical evaluation, we demonstrate that SingleADV effectively deceives the target deep learning models and their associated interpreters under various conditions and settings. Our experimental results show that the performance of SingleADV is effective, with an average fooling ratio of 0.74 and an adversarial confidence level of 0.78 in generating deceptive adversarial samples. Furthermore, we discuss several countermeasures against SingleADV, including a transfer-based learning approach and existing preprocessing defenses.
Tracking Dataset IP Use in Deep Neural Networks
Nov 24, 2022



Training highly performant deep neural networks (DNNs) typically requires the collection of a massive dataset and the use of powerful computing resources. Therefore, unauthorized redistribution of private pre-trained DNNs may cause severe economic loss for model owners. For protecting the ownership of DNN models, DNN watermarking schemes have been proposed by embedding secret information in a DNN model and verifying its presence for model ownership. However, existing DNN watermarking schemes compromise the model utility and are vulnerable to watermark removal attacks because a model is modified with a watermark. Alternatively, a new approach dubbed DEEPJUDGE was introduced to measure the similarity between a suspect model and a victim model without modifying the victim model. However, DEEPJUDGE would only be designed to detect the case where a suspect model's architecture is the same as a victim model's. In this work, we propose a novel DNN fingerprinting technique dubbed DEEPTASTER to prevent a new attack scenario in which a victim's data is stolen to build a suspect model. DEEPTASTER can effectively detect such data theft attacks even when a suspect model's architecture differs from a victim model's. To achieve this goal, DEEPTASTER generates a few adversarial images with perturbations, transforms them into the Fourier frequency domain, and uses the transformed images to identify the dataset used in a suspect model. The intuition is that those adversarial images can be used to capture the characteristics of DNNs built on a specific dataset. We evaluated the detection accuracy of DEEPTASTER on three datasets with three model architectures under various attack scenarios, including transfer learning, pruning, fine-tuning, and data augmentation. Overall, DEEPTASTER achieves a balanced accuracy of 94.95%, which is significantly better than 61.11% achieved by DEEPJUDGE in the same settings.
Dangerous Cloaking: Natural Trigger based Backdoor Attacks on Object Detectors in the Physical World
Jan 21, 2022
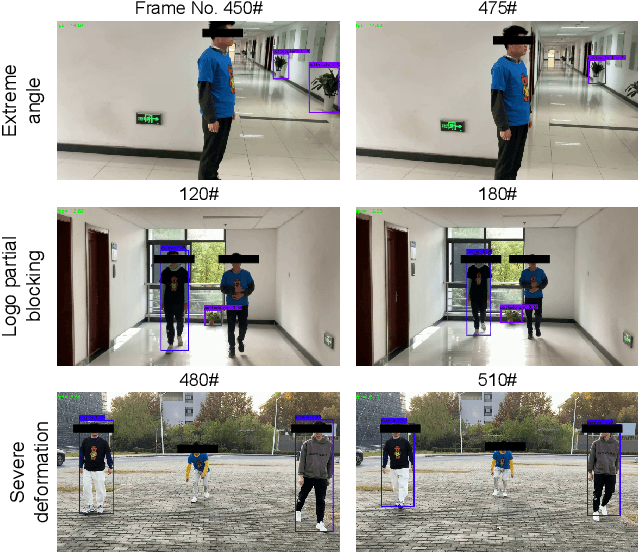
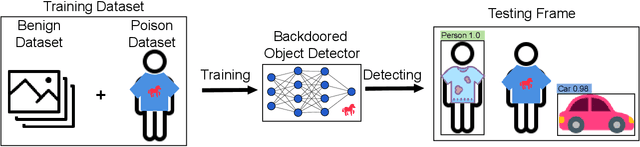

Deep learning models have been shown to be vulnerable to recent backdoor attacks. A backdoored model behaves normally for inputs containing no attacker-secretly-chosen trigger and maliciously for inputs with the trigger. To date, backdoor attacks and countermeasures mainly focus on image classification tasks. And most of them are implemented in the digital world with digital triggers. Besides the classification tasks, object detection systems are also considered as one of the basic foundations of computer vision tasks. However, there is no investigation and understanding of the backdoor vulnerability of the object detector, even in the digital world with digital triggers. For the first time, this work demonstrates that existing object detectors are inherently susceptible to physical backdoor attacks. We use a natural T-shirt bought from a market as a trigger to enable the cloaking effect--the person bounding-box disappears in front of the object detector. We show that such a backdoor can be implanted from two exploitable attack scenarios into the object detector, which is outsourced or fine-tuned through a pretrained model. We have extensively evaluated three popular object detection algorithms: anchor-based Yolo-V3, Yolo-V4, and anchor-free CenterNet. Building upon 19 videos shot in real-world scenes, we confirm that the backdoor attack is robust against various factors: movement, distance, angle, non-rigid deformation, and lighting. Specifically, the attack success rate (ASR) in most videos is 100% or close to it, while the clean data accuracy of the backdoored model is the same as its clean counterpart. The latter implies that it is infeasible to detect the backdoor behavior merely through a validation set. The averaged ASR still remains sufficiently high to be 78% in the transfer learning attack scenarios evaluated on CenterNet. See the demo video on https://youtu.be/Q3HOF4OobbY.
Evaluation and Optimization of Distributed Machine Learning Techniques for Internet of Things
Mar 03, 2021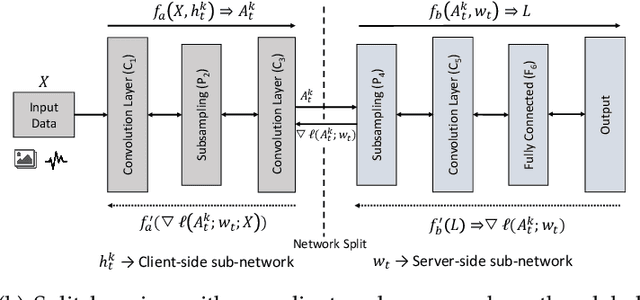
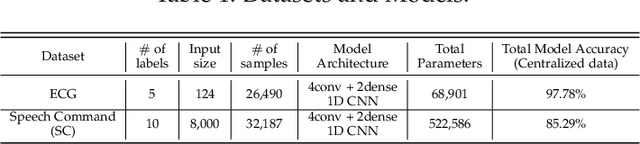
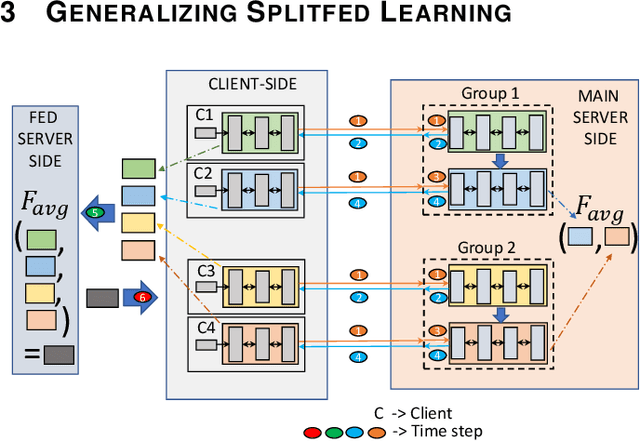
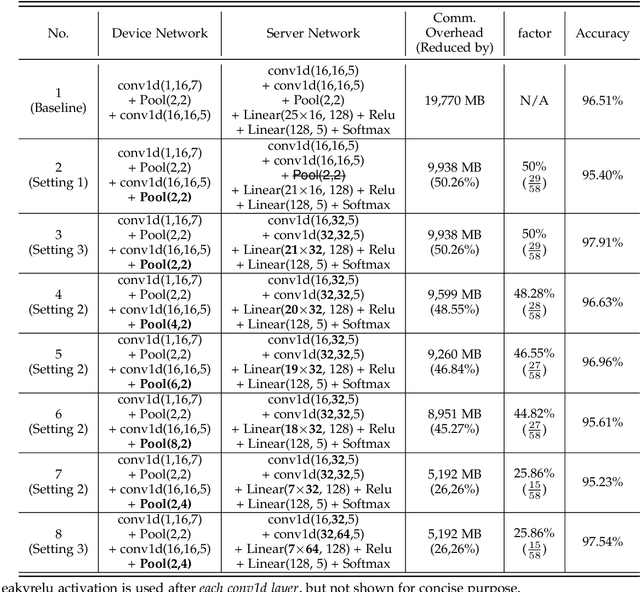
Federated learning (FL) and split learning (SL) are state-of-the-art distributed machine learning techniques to enable machine learning training without accessing raw data on clients or end devices. However, their \emph{comparative training performance} under real-world resource-restricted Internet of Things (IoT) device settings, e.g., Raspberry Pi, remains barely studied, which, to our knowledge, have not yet been evaluated and compared, rendering inconvenient reference for practitioners. This work firstly provides empirical comparisons of FL and SL in real-world IoT settings regarding (i) learning performance with heterogeneous data distributions and (ii) on-device execution overhead. Our analyses in this work demonstrate that the learning performance of SL is better than FL under an imbalanced data distribution but worse than FL under an extreme non-IID data distribution. Recently, FL and SL are combined to form splitfed learning (SFL) to leverage each of their benefits (e.g., parallel training of FL and lightweight on-device computation requirement of SL). This work then considers FL, SL, and SFL, and mount them on Raspberry Pi devices to evaluate their performance, including training time, communication overhead, power consumption, and memory usage. Besides evaluations, we apply two optimizations. Firstly, we generalize SFL by carefully examining the possibility of a hybrid type of model training at the server-side. The generalized SFL merges sequential (dependent) and parallel (independent) processes of model training and is thus beneficial for a system with large-scaled IoT devices, specifically at the server-side operations. Secondly, we propose pragmatic techniques to substantially reduce the communication overhead by up to four times for the SL and (generalized) SFL.
DeepiSign: Invisible Fragile Watermark to Protect the Integrityand Authenticity of CNN
Jan 12, 2021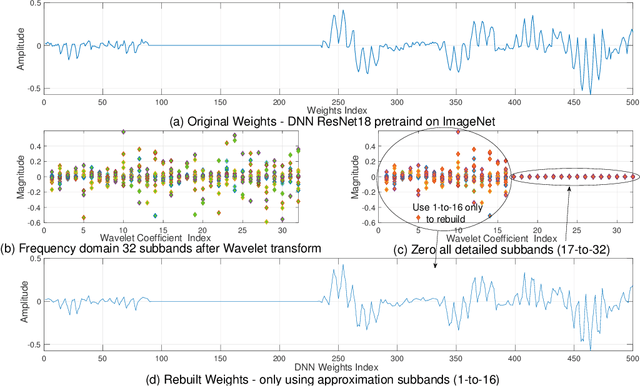
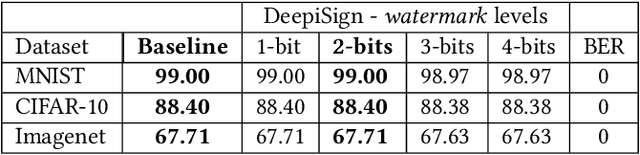
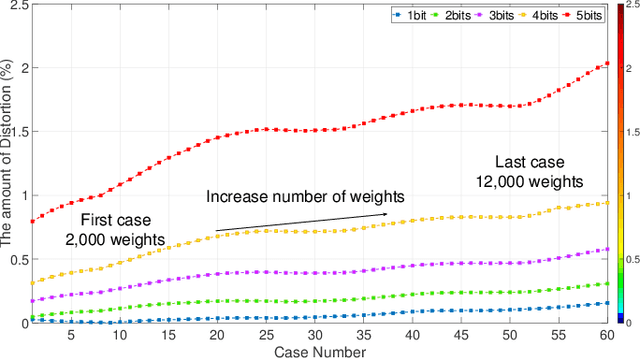

Convolutional Neural Networks (CNNs) deployed in real-life applications such as autonomous vehicles have shown to be vulnerable to manipulation attacks, such as poisoning attacks and fine-tuning. Hence, it is essential to ensure the integrity and authenticity of CNNs because compromised models can produce incorrect outputs and behave maliciously. In this paper, we propose a self-contained tamper-proofing method, called DeepiSign, to ensure the integrity and authenticity of CNN models against such manipulation attacks. DeepiSign applies the idea of fragile invisible watermarking to securely embed a secret and its hash value into a CNN model. To verify the integrity and authenticity of the model, we retrieve the secret from the model, compute the hash value of the secret, and compare it with the embedded hash value. To minimize the effects of the embedded secret on the CNN model, we use a wavelet-based technique to transform weights into the frequency domain and embed the secret into less significant coefficients. Our theoretical analysis shows that DeepiSign can hide up to 1KB secret in each layer with minimal loss of the model's accuracy. To evaluate the security and performance of DeepiSign, we performed experiments on four pre-trained models (ResNet18, VGG16, AlexNet, and MobileNet) using three datasets (MNIST, CIFAR-10, and Imagenet) against three types of manipulation attacks (targeted input poisoning, output poisoning, and fine-tuning). The results demonstrate that DeepiSign is verifiable without degrading the classification accuracy, and robust against representative CNN manipulation attacks.
Decamouflage: A Framework to Detect Image-Scaling Attacks on Convolutional Neural Networks
Oct 08, 2020

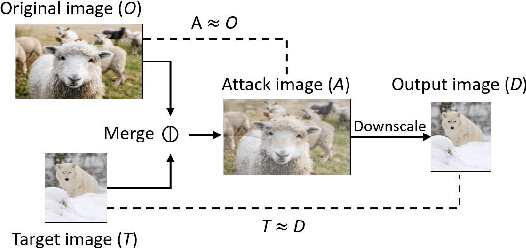
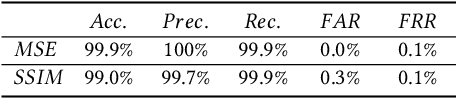
As an essential processing step in computer vision applications, image resizing or scaling, more specifically downsampling, has to be applied before feeding a normally large image into a convolutional neural network (CNN) model because CNN models typically take small fixed-size images as inputs. However, image scaling functions could be adversarially abused to perform a newly revealed attack called image-scaling attack, which can affect a wide range of computer vision applications building upon image-scaling functions. This work presents an image-scaling attack detection framework, termed as Decamouflage. Decamouflage consists of three independent detection methods: (1) rescaling, (2) filtering/pooling, and (3) steganalysis. While each of these three methods is efficient standalone, they can work in an ensemble manner not only to improve the detection accuracy but also to harden potential adaptive attacks. Decamouflage has a pre-determined detection threshold that is generic. More precisely, as we have validated, the threshold determined from one dataset is also applicable to other different datasets. Extensive experiments show that Decamouflage achieves detection accuracy of 99.9\% and 99.8\% in the white-box (with the knowledge of attack algorithms) and the black-box (without the knowledge of attack algorithms) settings, respectively. To corroborate the efficiency of Decamouflage, we have also measured its run-time overhead on a personal PC with an i5 CPU and found that Decamouflage can detect image-scaling attacks in milliseconds. Overall, Decamouflage can accurately detect image scaling attacks in both white-box and black-box settings with acceptable run-time overhead.
Backdoor Attacks and Countermeasures on Deep Learning: A Comprehensive Review
Aug 02, 2020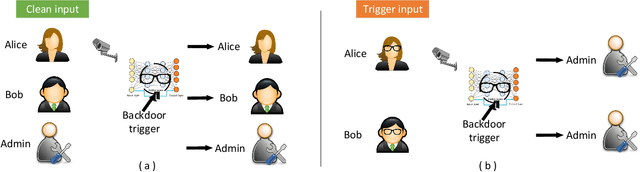
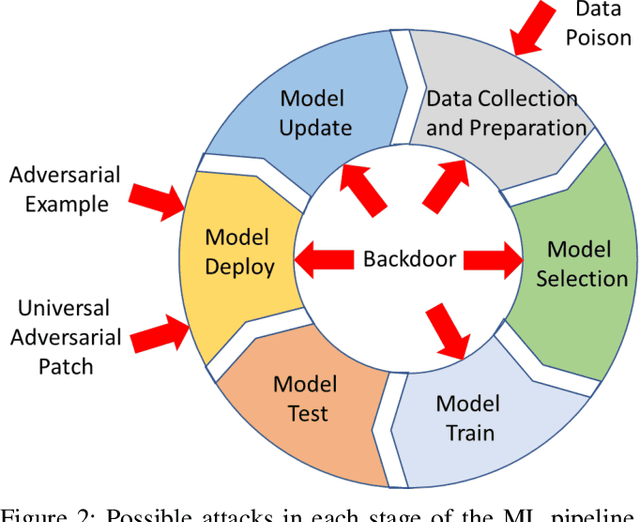
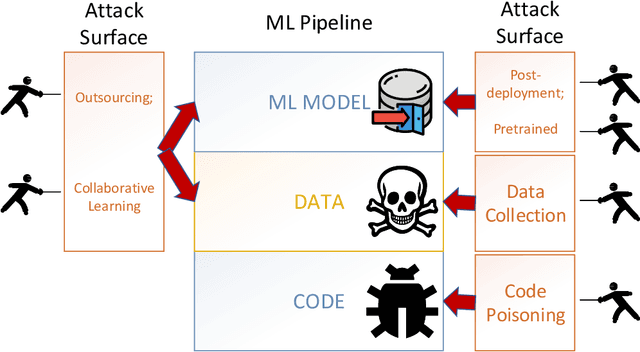

This work provides the community with a timely comprehensive review of backdoor attacks and countermeasures on deep learning. According to the attacker's capability and affected stage of the machine learning pipeline, the attack surfaces are recognized to be wide and then formalized into six categorizations: code poisoning, outsourcing, pretrained, data collection, collaborative learning and post-deployment. Accordingly, attacks under each categorization are combed. The countermeasures are categorized into four general classes: blind backdoor removal, offline backdoor inspection, online backdoor inspection, and post backdoor removal. Accordingly, we review countermeasures, and compare and analyze their advantages and disadvantages. We have also reviewed the flip side of backdoor attacks, which are explored for i) protecting intellectual property of deep learning models, ii) acting as a honeypot to catch adversarial example attacks, and iii) verifying data deletion requested by the data contributor.Overall, the research on defense is far behind the attack, and there is no single defense that can prevent all types of backdoor attacks. In some cases, an attacker can intelligently bypass existing defenses with an adaptive attack. Drawing the insights from the systematic review, we also present key areas for future research on the backdoor, such as empirical security evaluations from physical trigger attacks, and in particular, more efficient and practical countermeasures are solicited.