 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Dive into Function Inlining and its Security Implications for ML-based Binary Analysis
Dec 16, 2025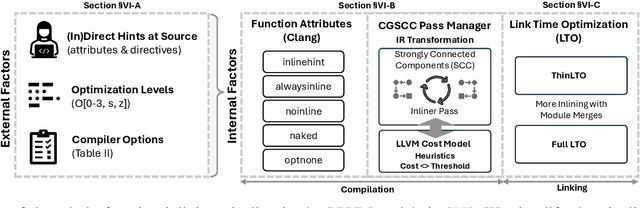



A function inlining optimization is a widely used transformation in modern compilers, which replaces a call site with the callee's body in need. While this transformation improves performance, it significantly impacts static features such as machine instructions and control flow graphs, which are crucial to binary analysis. Yet, despite its broad impact, the security impact of function inlining remains underexplored to date. In this paper, we present the first comprehensive study of function inlining through the lens of machine learning-based binary analysis. To this end, we dissect the inlining decision pipeline within the LLVM's cost model and explore the combinations of the compiler options that aggressively promote the function inlining ratio beyond standard optimization levels, which we term extreme inlining. We focus on five ML-assisted binary analysis tasks for security, using 20 unique models to systematically evaluate their robustness under extreme inlining scenarios. Our extensive experiments reveal several significant findings: i) function inlining, though a benign transformation in intent, can (in)directly affect ML model behaviors, being potentially exploited by evading discriminative or generative ML models; ii) ML models relying on static features can be highly sensitive to inlining; iii) subtle compiler settings can be leveraged to deliberately craft evasive binary variants; and iv) inlining ratios vary substantially across applications and build configurations, undermining assumptions of consistency in training and evaluation of ML models.
Impact of Architectural Modifications on Deep Learning Adversarial Robustness
May 03, 2024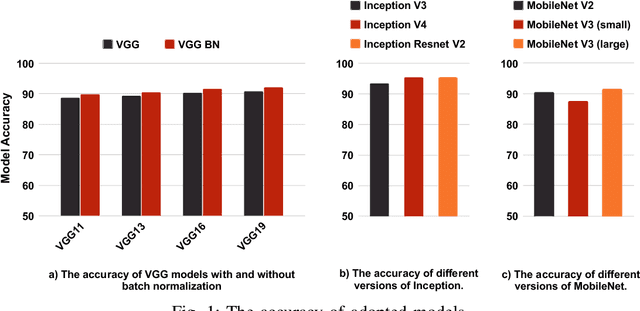
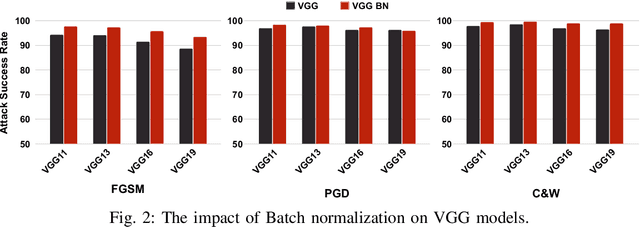
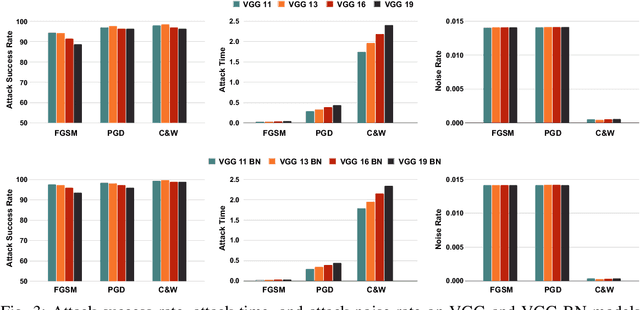
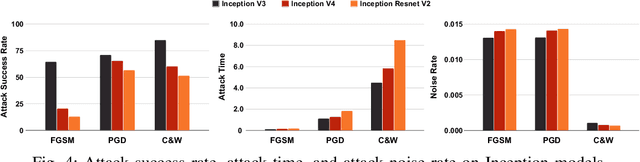
Rapid advancements of deep learning are accelerating adoption in a wide variety of applications, including safety-critical applications such as self-driving vehicles, drones, robots, and surveillance systems. These advancements include applying variations of sophisticated techniques that improve the performance of models. However, such models are not immune to adversarial manipulations, which can cause the system to misbehave and remain unnoticed by experts. The frequency of modifications to existing deep learning models necessitates thorough analysis to determine the impact on models' robustness. In this work, we present an experimental evaluation of the effects of model modifications on deep learning model robustness using adversarial attacks. Our methodology involves examining the robustness of variations of models against various adversarial attacks. By conducting our experiments, we aim to shed light on the critical issue of maintaining the reliability and safety of deep learning models in safety- and security-critical applications. Our results indicate the pressing demand for an in-depth assessment of the effects of model changes on the robustness of models.
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
May 03, 2024



Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
Unveiling Vulnerabilities in Interpretable Deep Learning Systems with Query-Efficient Black-box Attacks
Jul 21, 2023Deep learning has been rapidly employed in many applications revolutionizing many industries, but it is known to be vulnerable to adversarial attacks. Such attacks pose a serious threat to deep learning-based systems compromising their integrity, reliability, and trust. Interpretable Deep Learning Systems (IDLSes) are designed to make the system more transparent and explainable, but they are also shown to be susceptible to attacks. In this work, we propose a novel microbial genetic algorithm-based black-box attack against IDLSes that requires no prior knowledge of the target model and its interpretation model. The proposed attack is a query-efficient approach that combines transfer-based and score-based methods, making it a powerful tool to unveil IDLS vulnerabilities. Our experiments of the attack show high attack success rates using adversarial examples with attribution maps that are highly similar to those of benign samples which makes it difficult to detect even by human analysts. Our results highlight the need for improved IDLS security to ensure their practical reliability.
Microbial Genetic Algorithm-based Black-box Attack against Interpretable Deep Learning Systems
Jul 13, 2023



Deep learning models are susceptible to adversarial samples in white and black-box environments. Although previous studies have shown high attack success rates, coupling DNN models with interpretation models could offer a sense of security when a human expert is involved, who can identify whether a given sample is benign or malicious. However, in white-box environments, interpretable deep learning systems (IDLSes) have been shown to be vulnerable to malicious manipulations. In black-box settings, as access to the components of IDLSes is limited, it becomes more challenging for the adversary to fool the system. In this work, we propose a Query-efficient Score-based black-box attack against IDLSes, QuScore, which requires no knowledge of the target model and its coupled interpretation model. QuScore is based on transfer-based and score-based methods by employing an effective microbial genetic algorithm. Our method is designed to reduce the number of queries necessary to carry out successful attacks, resulting in a more efficient process. By continuously refining the adversarial samples created based on feedback scores from the IDLS, our approach effectively navigates the search space to identify perturbations that can fool the system. We evaluate the attack's effectiveness on four CNN models (Inception, ResNet, VGG, DenseNet) and two interpretation models (CAM, Grad), using both ImageNet and CIFAR datasets. Our results show that the proposed approach is query-efficient with a high attack success rate that can reach between 95% and 100% and transferability with an average success rate of 69% in the ImageNet and CIFAR datasets. Our attack method generates adversarial examples with attribution maps that resemble benign samples. We have also demonstrated that our attack is resilient against various preprocessing defense techniques and can easily be transferred to different DNN models.
Single-Class Target-Specific Attack against Interpretable Deep Learning Systems
Jul 12, 2023



In this paper, we present a novel Single-class target-specific Adversarial attack called SingleADV. The goal of SingleADV is to generate a universal perturbation that deceives the target model into confusing a specific category of objects with a target category while ensuring highly relevant and accurate interpretations. The universal perturbation is stochastically and iteratively optimized by minimizing the adversarial loss that is designed to consider both the classifier and interpreter costs in targeted and non-targeted categories. In this optimization framework, ruled by the first- and second-moment estimations, the desired loss surface promotes high confidence and interpretation score of adversarial samples. By avoiding unintended misclassification of samples from other categories, SingleADV enables more effective targeted attacks on interpretable deep learning systems in both white-box and black-box scenarios. To evaluate the effectiveness of SingleADV, we conduct experiments using four different model architectures (ResNet-50, VGG-16, DenseNet-169, and Inception-V3) coupled with three interpretation models (CAM, Grad, and MASK). Through extensive empirical evaluation, we demonstrate that SingleADV effectively deceives the target deep learning models and their associated interpreters under various conditions and settings. Our experimental results show that the performance of SingleADV is effective, with an average fooling ratio of 0.74 and an adversarial confidence level of 0.78 in generating deceptive adversarial samples. Furthermore, we discuss several countermeasures against SingleADV, including a transfer-based learning approach and existing preprocessing defenses.
Interpretations Cannot Be Trusted: Stealthy and Effective Adversarial Perturbations against Interpretable Deep Learning
Nov 29, 2022



Deep learning methods have gained increased attention in various applications due to their outstanding performance. For exploring how this high performance relates to the proper use of data artifacts and the accurate problem formulation of a given task, interpretation models have become a crucial component in developing deep learning-based systems. Interpretation models enable the understanding of the inner workings of deep learning models and offer a sense of security in detecting the misuse of artifacts in the input data. Similar to prediction models, interpretation models are also susceptible to adversarial inputs. This work introduces two attacks, AdvEdge and AdvEdge$^{+}$, that deceive both the target deep learning model and the coupled interpretation model. We assess the effectiveness of proposed attacks against two deep learning model architectures coupled with four interpretation models that represent different categories of interpretation models. Our experiments include the attack implementation using various attack frameworks. We also explore the potential countermeasures against such attacks. Our analysis shows the effectiveness of our attacks in terms of deceiving the deep learning models and their interpreters, and highlights insights to improve and circumvent the attacks.