 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Architectural Modifications on Deep Learning Adversarial Robustness
May 03, 2024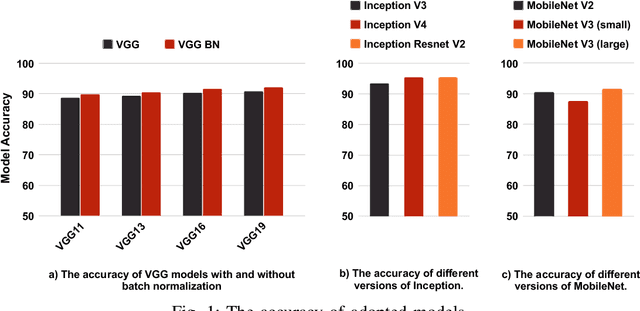
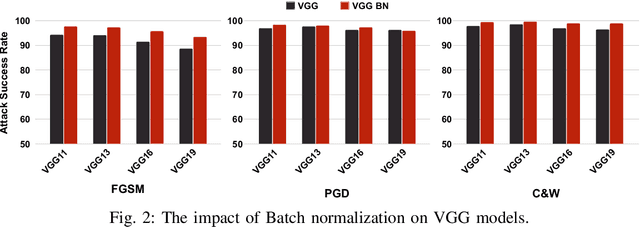
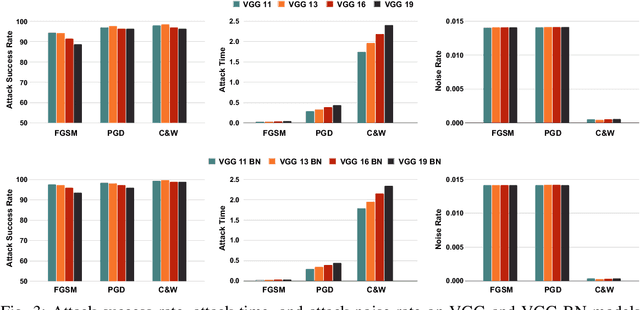
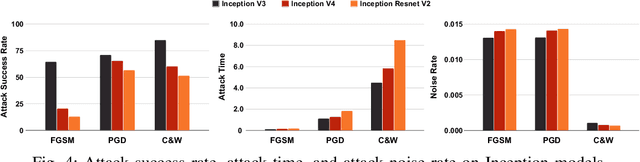
Rapid advancements of deep learning are accelerating adoption in a wide variety of applications, including safety-critical applications such as self-driving vehicles, drones, robots, and surveillance systems. These advancements include applying variations of sophisticated techniques that improve the performance of models. However, such models are not immune to adversarial manipulations, which can cause the system to misbehave and remain unnoticed by experts. The frequency of modifications to existing deep learning models necessitates thorough analysis to determine the impact on models' robustness. In this work, we present an experimental evaluation of the effects of model modifications on deep learning model robustness using adversarial attacks. Our methodology involves examining the robustness of variations of models against various adversarial attacks. By conducting our experiments, we aim to shed light on the critical issue of maintaining the reliability and safety of deep learning models in safety- and security-critical applications. Our results indicate the pressing demand for an in-depth assessment of the effects of model changes on the robustness of models.
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
May 03, 2024



Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.