 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Local Code Optimization: Multi-Agent Reasoning for Software System Optimization
Mar 16, 2026Large language models and AI agents have recently shown promise in automating software performance optimization, but existing approaches predominantly rely on local, syntax-driven code transformations. This limits their ability to reason about program behavior and capture whole system performance interactions. As modern software increasingly comprises interacting components - such as microservices, databases, and shared infrastructure - effective code optimization requires reasoning about program structure and system architecture beyond individual functions or files. This paper explores the feasibility of whole system optimization for microservices. We introduce a multi-agent framework that integrates control-flow and data-flow representations with architectural and cross-component dependency signals to support system-level performance reasoning. The proposed system is decomposed into coordinated agent roles - summarization, analysis, optimization, and verification - that collaboratively identify cross-cutting bottlenecks and construct multi-step optimization strategies spanning the software stack. We present a proof-of-concept on a microservice-based system that illustrates the effectiveness of our proposed framework, achieving a 36.58% improvement in throughput and a 27.81% reduction in average response time.
Improving the Reproducibility of Deep Learning Software: An Initial Investigation through a Case Study Analysis
May 06, 2025The field of deep learning has witnessed significant breakthroughs, spanning various applications, and fundamentally transforming current software capabilities. However, alongside these advancements, there have been increasing concerns about reproducing the results of these deep learning methods. This is significant because reproducibility is the foundation of reliability and validity in software development, particularly in the rapidly evolving domain of deep learning. The difficulty of reproducibility may arise due to several reasons, including having differences from the original execution environment, incompatible software libraries, proprietary data and source code, lack of transparency, and the stochastic nature in some software. A study conducted by the Nature journal reveals that more than 70% of researchers failed to reproduce other researchers experiments and over 50% failed to reproduce their own experiments. Irreproducibility of deep learning poses significant challenges for researchers and practitioners. To address these concerns, this paper presents a systematic approach at analyzing and improving the reproducibility of deep learning models by demonstrating these guidelines using a case study. We illustrate the patterns and anti-patterns involved with these guidelines for improving the reproducibility of deep learning models. These guidelines encompass establishing a methodology to replicate the original software environment, implementing end-to-end training and testing algorithms, disclosing architectural designs, and enhancing transparency in data processing and training pipelines. We also conduct a sensitivity analysis to understand the model performance across diverse conditions. By implementing these strategies, we aim to bridge the gap between research and practice, so that innovations in deep learning can be effectively reproduced and deployed within software.
What do we know about Hugging Face? A systematic literature review and quantitative validation of qualitative claims
Jun 12, 2024



Background: Collaborative Software Package Registries (SPRs) are an integral part of the software supply chain. Much engineering work synthesizes SPR package into applications. Prior research has examined SPRs for traditional software, such as NPM (JavaScript) and PyPI (Python). Pre-Trained Model (PTM) Registries are an emerging class of SPR of increasing importance, because they support the deep learning supply chain. Aims: Recent empirical research has examined PTM registries in ways such as vulnerabilities, reuse processes, and evolution. However, no existing research synthesizes them to provide a systematic understanding of the current knowledge. Some of the existing research includes qualitative claims lacking quantitative analysis. Our research fills these gaps by providing a knowledge synthesis and quantitative analyses. Methods: We first conduct a systematic literature review (SLR). We then observe that some of the claims are qualitative. We identify quantifiable metrics associated with those claims, and measure in order to substantiate these claims. Results: From our SLR, we identify 12 claims about PTM reuse on the HuggingFace platform, 4 of which lack quantitative validation. We successfully test 3 of these claims through a quantitative analysis, and directly compare one with traditional software. Our findings corroborate qualitative claims with quantitative measurements. Our findings are: (1) PTMs have a much higher turnover rate than traditional software, indicating a dynamic and rapidly evolving reuse environment within the PTM ecosystem; and (2) There is a strong correlation between documentation quality and PTM popularity. Conclusions: We confirm qualitative research claims with concrete metrics, supporting prior qualitative and case study research. Our measures show further dynamics of PTM reuse, inspiring research infrastructure and new measures.
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
May 03, 2024



Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024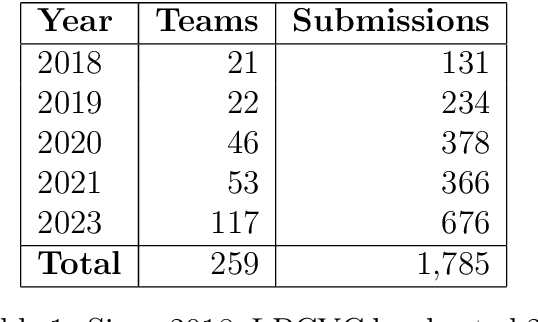
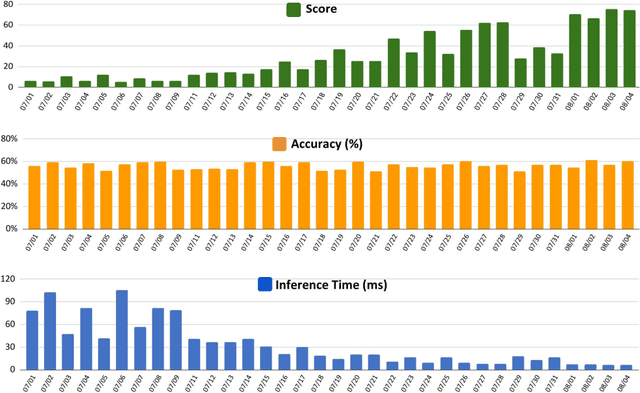

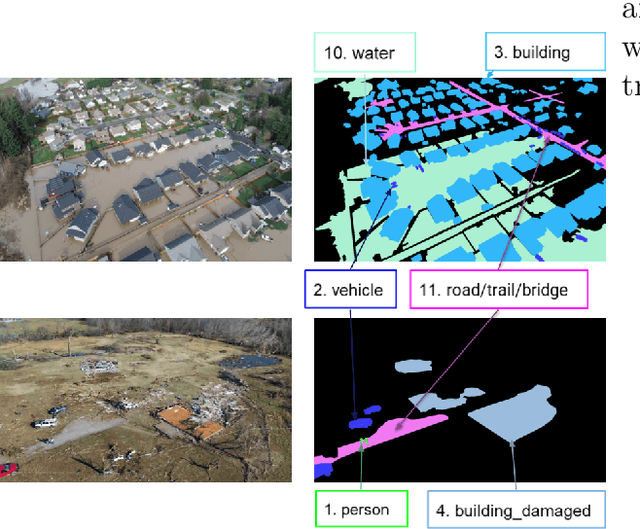
This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
PeaTMOSS: A Dataset and Initial Analysis of Pre-Trained Models in Open-Source Software
Feb 01, 2024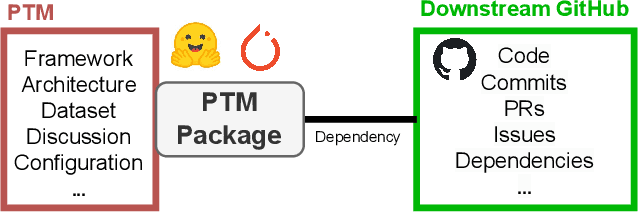
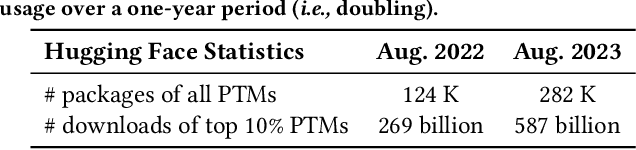
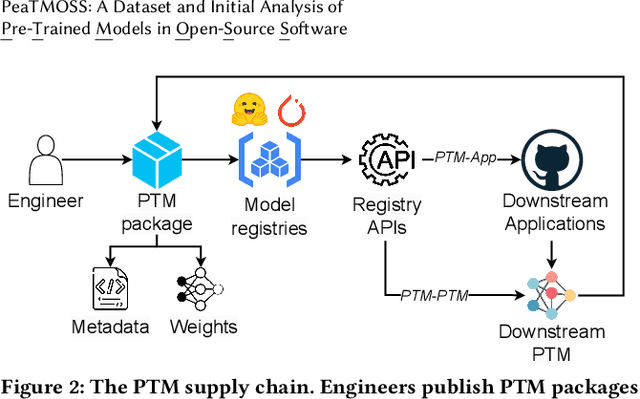

The development and training of deep learning models have become increasingly costly and complex. Consequently, software engineers are adopting pre-trained models (PTMs) for their downstream applications. The dynamics of the PTM supply chain remain largely unexplored, signaling a clear need for structured datasets that document not only the metadata but also the subsequent applications of these models. Without such data, the MSR community cannot comprehensively understand the impact of PTM adoption and reuse. This paper presents the PeaTMOSS dataset, which comprises metadata for 281,638 PTMs and detailed snapshots for all PTMs with over 50 monthly downloads (14,296 PTMs), along with 28,575 open-source software repositories from GitHub that utilize these models. Additionally, the dataset includes 44,337 mappings from 15,129 downstream GitHub repositories to the 2,530 PTMs they use. To enhance the dataset's comprehensiveness, we developed prompts for a large language model to automatically extract model metadata, including the model's training datasets, parameters, and evaluation metrics. Our analysis of this dataset provides the first summary statistics for the PTM supply chain, showing the trend of PTM development and common shortcomings of PTM package documentation. Our example application reveals inconsistencies in software licenses across PTMs and their dependent projects. PeaTMOSS lays the foundation for future research, offering rich opportunities to investigate the PTM supply chain. We outline mining opportunities on PTMs, their downstream usage, and cross-cutting questions.
An automated approach for improving the inference latency and energy efficiency of pretrained CNNs by removing irrelevant pixels with focused convolutions
Oct 11, 2023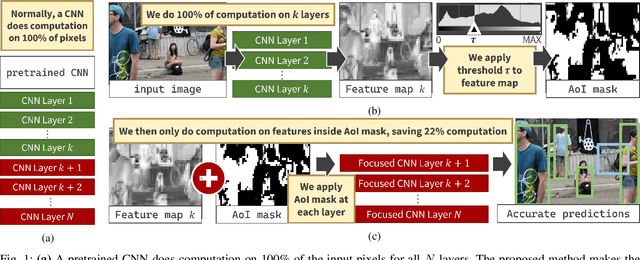
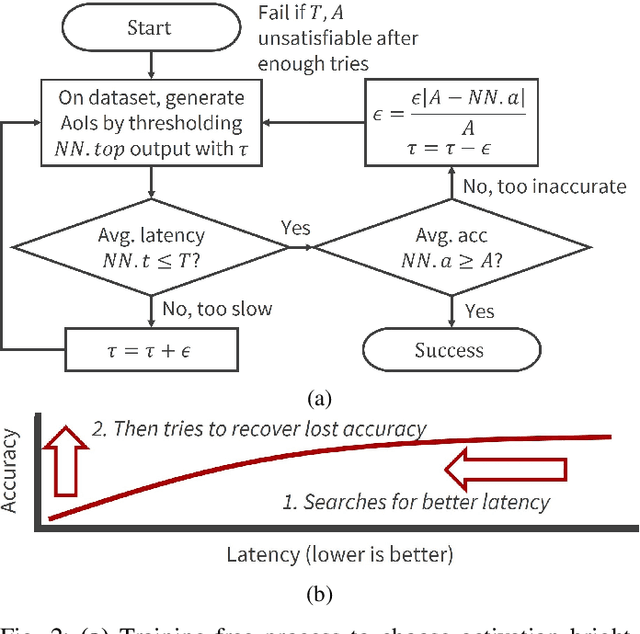

Computer vision often uses highly accurate Convolutional Neural Networks (CNNs), but these deep learning models are associated with ever-increasing energy and computation requirements. Producing more energy-efficient CNNs often requires model training which can be cost-prohibitive. We propose a novel, automated method to make a pretrained CNN more energy-efficient without re-training. Given a pretrained CNN, we insert a threshold layer that filters activations from the preceding layers to identify regions of the image that are irrelevant, i.e. can be ignored by the following layers while maintaining accuracy. Our modified focused convolution operation saves inference latency (by up to 25%) and energy costs (by up to 22%) on various popular pretrained CNNs, with little to no loss in accuracy.
PeaTMOSS: Mining Pre-Trained Models in Open-Source Software
Oct 05, 2023



Developing and training deep learning models is expensive, so software engineers have begun to reuse pre-trained deep learning models (PTMs) and fine-tune them for downstream tasks. Despite the wide-spread use of PTMs, we know little about the corresponding software engineering behaviors and challenges. To enable the study of software engineering with PTMs, we present the PeaTMOSS dataset: Pre-Trained Models in Open-Source Software. PeaTMOSS has three parts: a snapshot of (1) 281,638 PTMs, (2) 27,270 open-source software repositories that use PTMs, and (3) a mapping between PTMs and the projects that use them. We challenge PeaTMOSS miners to discover software engineering practices around PTMs. A demo and link to the full dataset are available at: https://github.com/PurdueDualityLab/PeaTMOSS-Demos.
Exploring Naming Conventions (and Defects) of Pre-trained Deep Learning Models in Hugging Face and Other Model Hubs
Oct 02, 2023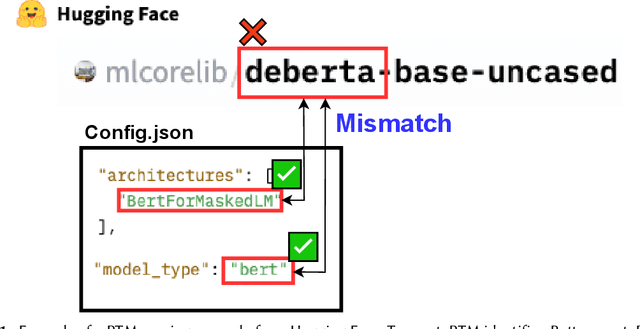
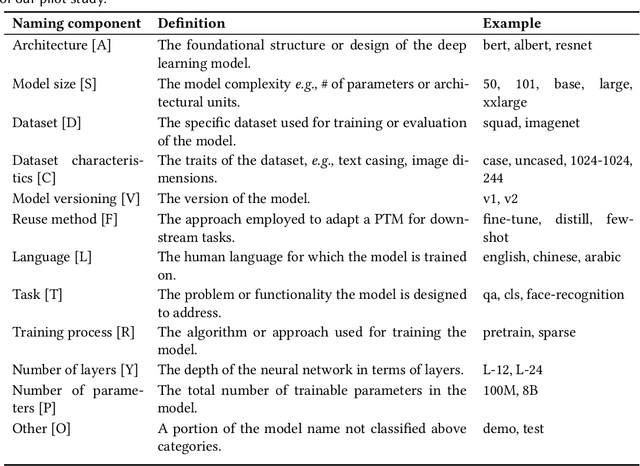
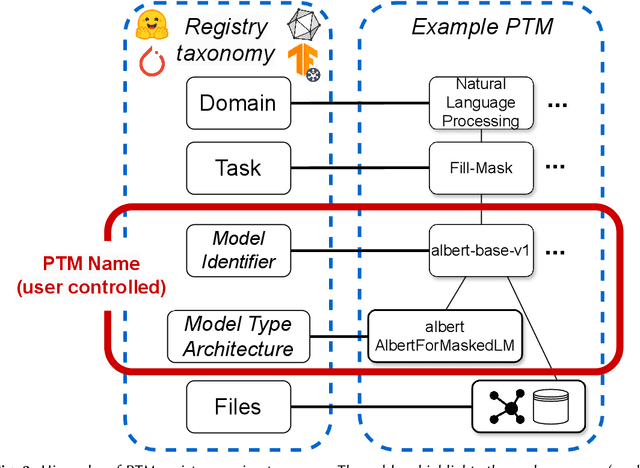

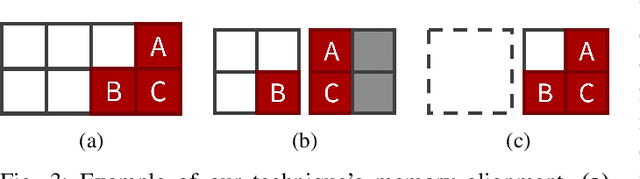
As innovation in deep learning continues, many engineers want to adopt Pre-Trained deep learning Models (PTMs) as components in computer systems. PTMs are part of a research-to-practice pipeline: researchers publish PTMs, which engineers adapt for quality or performance and then deploy. If PTM authors choose appropriate names for their PTMs, it could facilitate model discovery and reuse. However, prior research has reported that model names are not always well chosen, and are sometimes erroneous. The naming conventions and naming defects for PTM packages have not been systematically studied - understanding them will add to our knowledge of how the research-to-practice process works for PTM packages In this paper, we report the first study of PTM naming conventions and the associated PTM naming defects. We define the components of a PTM package name, comprising the package name and claimed architecture from the metadata. We present the first study focused on characterizing the nature of naming in PTM ecosystem. To this end, we developed a novel automated naming assessment technique that can automatically extract the semantic and syntactic patterns. To identify potential naming defects, we developed a novel algorithm, automated DNN ARchitecture Assessment pipeline (DARA), to cluster PTMs based on architectural differences. Our study suggests the naming conventions for PTMs, and frames the naming conventions as signal of the research-to-practice relationships in the PTM ecosystem. We envision future works on further empirical study on leveraging meta-features of PTMs to support model search and reuse.
Single-Class Target-Specific Attack against Interpretable Deep Learning Systems
Jul 12, 2023



In this paper, we present a novel Single-class target-specific Adversarial attack called SingleADV. The goal of SingleADV is to generate a universal perturbation that deceives the target model into confusing a specific category of objects with a target category while ensuring highly relevant and accurate interpretations. The universal perturbation is stochastically and iteratively optimized by minimizing the adversarial loss that is designed to consider both the classifier and interpreter costs in targeted and non-targeted categories. In this optimization framework, ruled by the first- and second-moment estimations, the desired loss surface promotes high confidence and interpretation score of adversarial samples. By avoiding unintended misclassification of samples from other categories, SingleADV enables more effective targeted attacks on interpretable deep learning systems in both white-box and black-box scenarios. To evaluate the effectiveness of SingleADV, we conduct experiments using four different model architectures (ResNet-50, VGG-16, DenseNet-169, and Inception-V3) coupled with three interpretation models (CAM, Grad, and MASK). Through extensive empirical evaluation, we demonstrate that SingleADV effectively deceives the target deep learning models and their associated interpreters under various conditions and settings. Our experimental results show that the performance of SingleADV is effective, with an average fooling ratio of 0.74 and an adversarial confidence level of 0.78 in generating deceptive adversarial samples. Furthermore, we discuss several countermeasures against SingleADV, including a transfer-based learning approach and existing preprocessing defenses.