 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartEval: A Benchmark for Evaluating LLM-Generated Smart Contracts from Natural Language Specifications
May 10, 2026We introduce SmartEval, a benchmark for systematically evaluating the quality of Solidity smart contracts generated by large language models (LLMs) from natural language specifications. SmartEval provides a corpus of 9,000 generated contracts paired with expert-written ground-truth implementations drawn from the FSMSCG dataset, a five-dimensional evaluation rubric covering functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality, and a reproducible generation-and-evaluation pipeline. To validate the benchmark's reliability, we conduct three independent empirical studies: a five-condition ablation study (N=300 per condition) isolating the contribution of each pipeline component, a human expert evaluation by three Columbia University PhD researchers confirming automated scores align with expert judgment to within 0.34 points, and external security analysis via the Slither static analyzer confirming 79.4% agreement between the LLM auditor and a non-LLM rule-based tool. Systematic analysis of 9,000 generated contracts reveals characteristic failure modes (logic omissions at 35.3%, state transition errors at 23.4%, and complexity-driven degradation) and quantifies a +8.29 composite-score advantage of generated contracts over ground-truth implementations, attributable to LLMs' literal specification-following behavior. SmartEval establishes a reproducible, validated foundation for empirical research on LLM smart contract synthesis quality, with all data, evaluation code, and generated contracts publicly released.
Any-Subgroup Equivariant Networks via Symmetry Breaking
Mar 19, 2026The inclusion of symmetries as an inductive bias, known as equivariance, often improves generalization on geometric data (e.g. grids, sets, and graphs). However, equivariant architectures are usually highly constrained, designed for symmetries chosen a priori, and not applicable to datasets with other symmetries. This precludes the development of flexible, multi-modal foundation models capable of processing diverse data equivariantly. In this work, we build a single model -- the Any-Subgroup Equivariant Network (ASEN) -- that can be simultaneously equivariant to several groups, simply by modulating a certain auxiliary input feature. In particular, we start with a fully permutation-equivariant base model, and then obtain subgroup equivariance by using a symmetry-breaking input whose automorphism group is that subgroup. However, finding an input with the desired automorphism group is computationally hard. We overcome this by relaxing from exact to approximate symmetry breaking, leveraging the notion of 2-closure to derive fast algorithms. Theoretically, we show that our subgroup-equivariant networks can simulate equivariant MLPs, and their universality can be guaranteed if the base model is universal. Empirically, we validate our method on symmetry selection for graph and image tasks, as well as multitask and transfer learning for sequence tasks, showing that a single network equivariant to multiple permutation subgroups outperforms both separate equivariant models and a single non-equivariant model.
An end-to-end agentic pipeline for smart contract translation and quality evaluation
Feb 14, 2026We present an end-to-end framework for systematic evaluation of LLM-generated smart contracts from natural-language specifications. The system parses contractual text into structured schemas, generates Solidity code, and performs automated quality assessment through compilation and security checks. Using CrewAI-style agent teams with iterative refinement, the pipeline produces structured artifacts with full provenance metadata. Quality is measured across five dimensions, including functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality aggregated into composite scores. The framework supports paired evaluation against ground-truth implementations, quantifying alignment and identifying systematic error modes such as logic omissions and state transition inconsistencies. This provides a reproducible benchmark for empirical research on smart contract synthesis quality and supports extensions to formal verification and compliance checking.
Improving the Reproducibility of Deep Learning Software: An Initial Investigation through a Case Study Analysis
May 06, 2025The field of deep learning has witnessed significant breakthroughs, spanning various applications, and fundamentally transforming current software capabilities. However, alongside these advancements, there have been increasing concerns about reproducing the results of these deep learning methods. This is significant because reproducibility is the foundation of reliability and validity in software development, particularly in the rapidly evolving domain of deep learning. The difficulty of reproducibility may arise due to several reasons, including having differences from the original execution environment, incompatible software libraries, proprietary data and source code, lack of transparency, and the stochastic nature in some software. A study conducted by the Nature journal reveals that more than 70% of researchers failed to reproduce other researchers experiments and over 50% failed to reproduce their own experiments. Irreproducibility of deep learning poses significant challenges for researchers and practitioners. To address these concerns, this paper presents a systematic approach at analyzing and improving the reproducibility of deep learning models by demonstrating these guidelines using a case study. We illustrate the patterns and anti-patterns involved with these guidelines for improving the reproducibility of deep learning models. These guidelines encompass establishing a methodology to replicate the original software environment, implementing end-to-end training and testing algorithms, disclosing architectural designs, and enhancing transparency in data processing and training pipelines. We also conduct a sensitivity analysis to understand the model performance across diverse conditions. By implementing these strategies, we aim to bridge the gap between research and practice, so that innovations in deep learning can be effectively reproduced and deployed within software.
Challenges and Practices of Deep Learning Model Reengineering: A Case Study on Computer Vision
Mar 13, 2023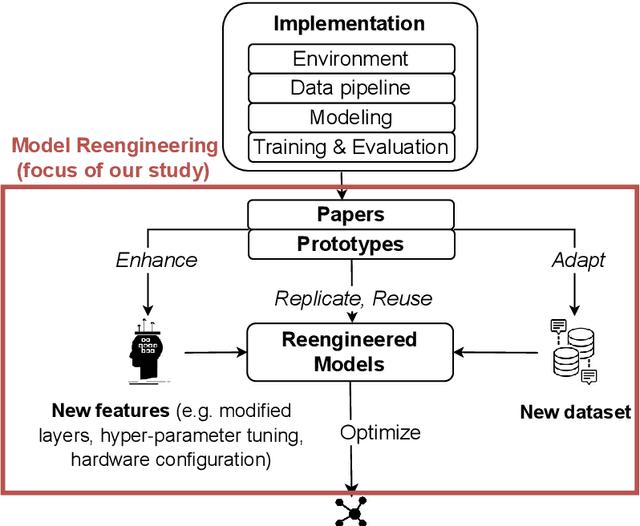


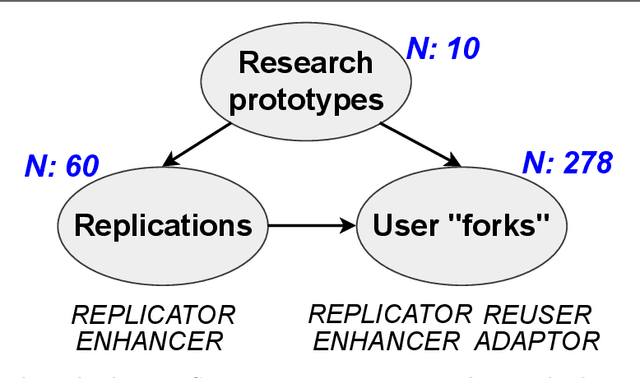
Many engineering organizations are reimplementing and extending deep neural networks from the research community. We describe this process as deep learning model reengineering. Deep learning model reengineering - reusing, reproducing, adapting, and enhancing state-of-the-art deep learning approaches - is challenging for reasons including under-documented reference models, changing requirements, and the cost of implementation and testing. In addition, individual engineers may lack expertise in software engineering, yet teams must apply knowledge of software engineering and deep learning to succeed. Prior work has examined on DL systems from a "product" view, examining defects from projects regardless of the engineers' purpose. Our study is focused on reengineering activities from a "process" view, and focuses on engineers specifically engaged in the reengineering process. Our goal is to understand the characteristics and challenges of deep learning model reengineering. We conducted a case study of this phenomenon, focusing on the context of computer vision. Our results draw from two data sources: defects reported in open-source reeengineering projects, and interviews conducted with open-source project contributors and the leaders of a reengineering team. Our results describe how deep learning-based computer vision techniques are reengineered, analyze the distribution of defects in this process, and discuss challenges and practices. Integrating our quantitative and qualitative data, we proposed a novel reengineering workflow. Our findings inform several future directions, including: measuring additional unknown aspects of model reengineering; standardizing engineering practices to facilitate reengineering; and developing tools to support model reengineering and model reuse.
Why Accuracy Is Not Enough: The Need for Consistency in Object Detection
Jul 28, 2022

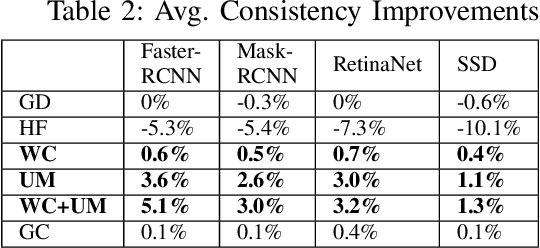
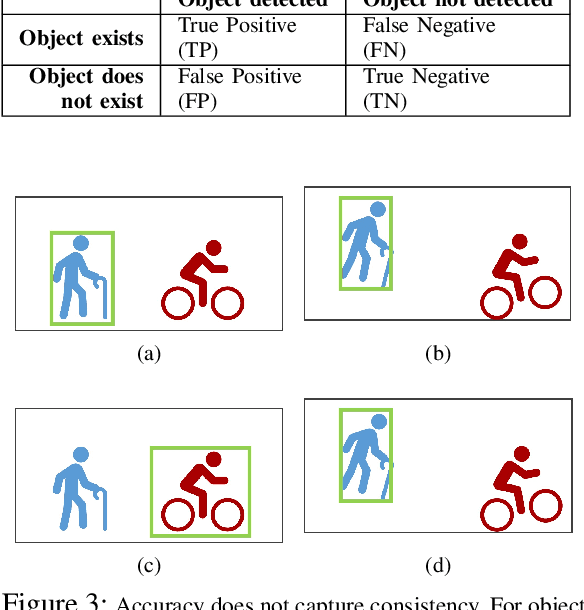
Object detectors are vital to many modern computer vision applications. However, even state-of-the-art object detectors are not perfect. On two images that look similar to human eyes, the same detector can make different predictions because of small image distortions like camera sensor noise and lighting changes. This problem is called inconsistency. Existing accuracy metrics do not properly account for inconsistency, and similar work in this area only targets improvements on artificial image distortions. Therefore, we propose a method to use non-artificial video frames to measure object detection consistency over time, across frames. Using this method, we show that the consistency of modern object detectors ranges from 83.2% to 97.1% on different video datasets from the Multiple Object Tracking Challenge. We conclude by showing that applying image distortion corrections like .WEBP Image Compression and Unsharp Masking can improve consistency by as much as 5.1%, with no loss in accuracy.
Irrelevant Pixels are Everywhere: Find and Exclude Them for More Efficient Computer Vision
Jul 21, 2022

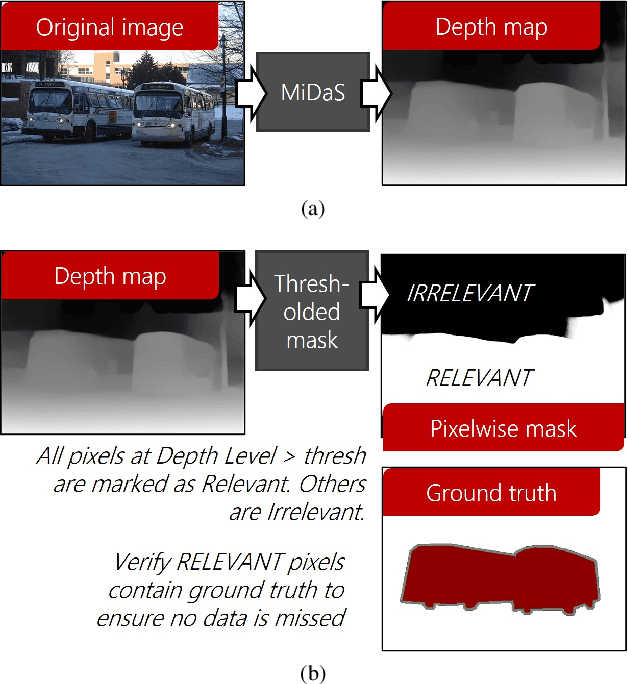
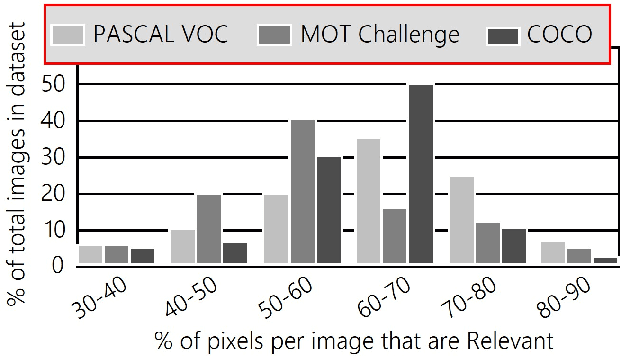
Computer vision is often performed using Convolutional Neural Networks (CNNs). CNNs are compute-intensive and challenging to deploy on power-contrained systems such as mobile and Internet-of-Things (IoT) devices. CNNs are compute-intensive because they indiscriminately compute many features on all pixels of the input image. We observe that, given a computer vision task, images often contain pixels that are irrelevant to the task. For example, if the task is looking for cars, pixels in the sky are not very useful. Therefore, we propose that a CNN be modified to only operate on relevant pixels to save computation and energy. We propose a method to study three popular computer vision datasets, finding that 48% of pixels are irrelevant. We also propose the focused convolution to modify a CNN's convolutional layers to reject the pixels that are marked irrelevant. On an embedded device, we observe no loss in accuracy, while inference latency, energy consumption, and multiply-add count are all reduced by about 45%.
Efficient Computer Vision on Edge Devices with Pipeline-Parallel Hierarchical Neural Networks
Sep 27, 2021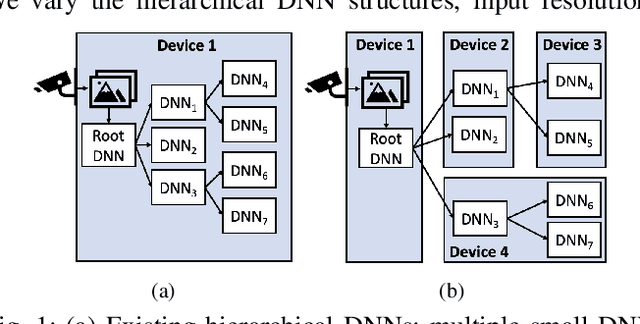
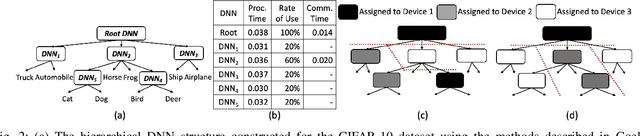
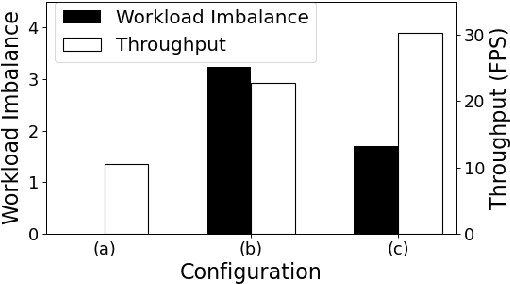
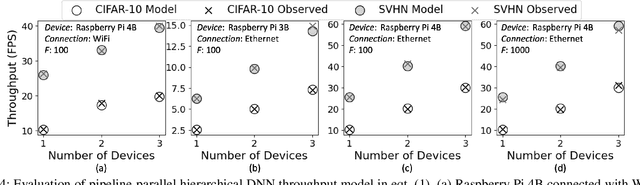
Computer vision on low-power edge devices enables applications including search-and-rescue and security. State-of-the-art computer vision algorithms, such as Deep Neural Networks (DNNs), are too large for inference on low-power edge devices. To improve efficiency, some existing approaches parallelize DNN inference across multiple edge devices. However, these techniques introduce significant communication and synchronization overheads or are unable to balance workloads across devices. This paper demonstrates that the hierarchical DNN architecture is well suited for parallel processing on multiple edge devices. We design a novel method that creates a parallel inference pipeline for computer vision problems that use hierarchical DNNs. The method balances loads across the collaborating devices and reduces communication costs to facilitate the processing of multiple video frames simultaneously with higher throughput. Our experiments consider a representative computer vision problem where image recognition is performed on each video frame, running on multiple Raspberry Pi 4Bs. With four collaborating low-power edge devices, our approach achieves 3.21X higher throughput, 68% less energy consumption per device per frame, and 58% decrease in memory when compared with existing single-device hierarchical DNNs.
Low-Power Multi-Camera Object Re-Identification using Hierarchical Neural Networks
Jun 19, 2021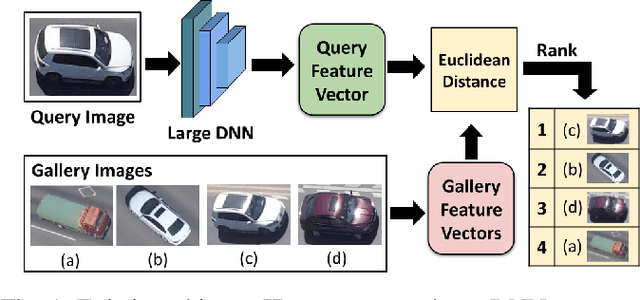
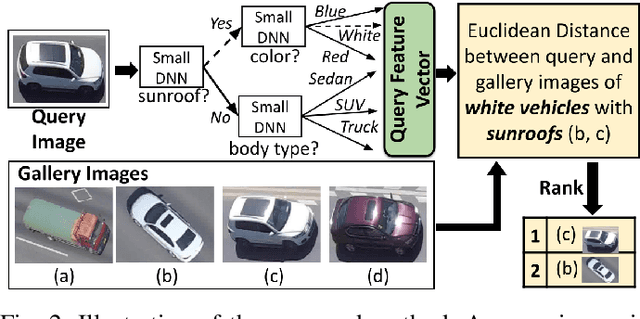

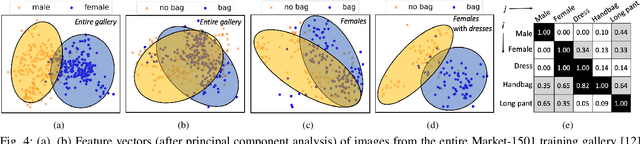
Low-power computer vision on embedded devices has many applications. This paper describes a low-power technique for the object re-identification (reID) problem: matching a query image against a gallery of previously seen images. State-of-the-art techniques rely on large, computationally-intensive Deep Neural Networks (DNNs). We propose a novel hierarchical DNN architecture that uses attribute labels in the training dataset to perform efficient object reID. At each node in the hierarchy, a small DNN identifies a different attribute of the query image. The small DNN at each leaf node is specialized to re-identify a subset of the gallery: only the images with the attributes identified along the path from the root to a leaf. Thus, a query image is re-identified accurately after processing with a few small DNNs. We compare our method with state-of-the-art object reID techniques. With a 4% loss in accuracy, our approach realizes significant resource savings: 74% less memory, 72% fewer operations, and 67% lower query latency, yielding 65% less energy consumption.
Analyzing Worldwide Social Distancing through Large-Scale Computer Vision
Aug 27, 2020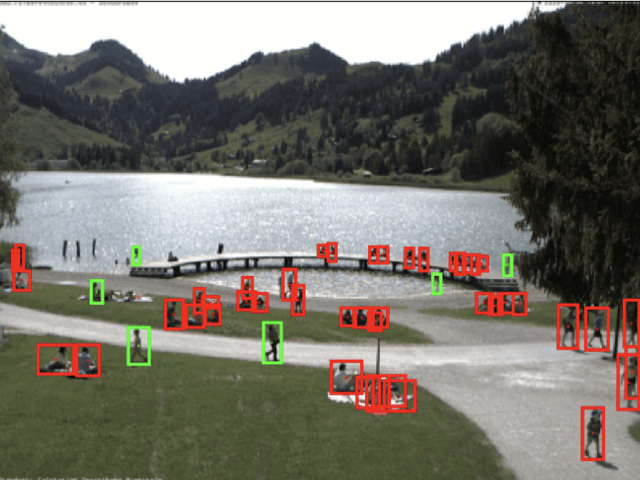
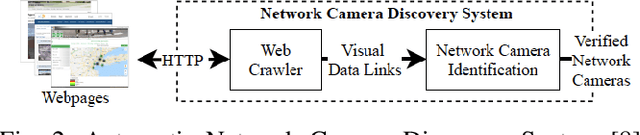
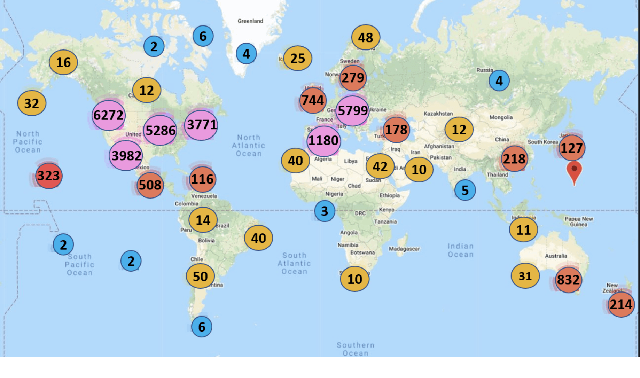
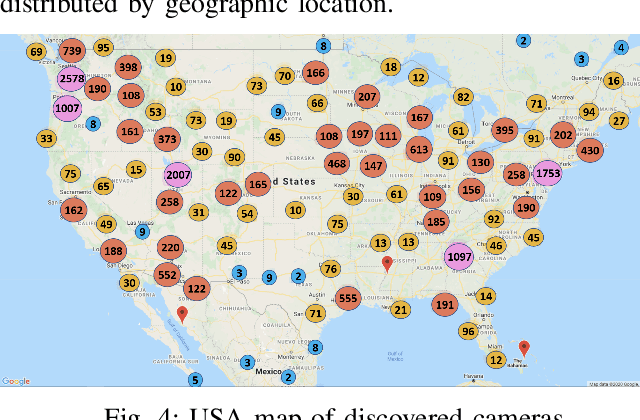
In order to contain the COVID-19 pandemic, countries around the world have introduced social distancing guidelines as public health interventions to reduce the spread of the disease. However, monitoring the efficacy of these guidelines at a large scale (nationwide or worldwide) is difficult. To make matters worse, traditional observational methods such as in-person reporting is dangerous because observers may risk infection. A better solution is to observe activities through network cameras; this approach is scalable and observers can stay in safe locations. This research team has created methods that can discover thousands of network cameras worldwide, retrieve data from the cameras, analyze the data, and report the sizes of crowds as different countries issued and lifted restrictions (also called ''lockdown''). We discover 11,140 network cameras that provide real-time data and we present the results across 15 countries. We collect data from these cameras beginning April 2020 at approximately 0.5TB per week. After analyzing 10,424,459 images from still image cameras and frames extracted periodically from video, the data reveals that the residents in some countries exhibited more activity (judged by numbers of people and vehicles) after the restrictions were lifted. In other countries, the amounts of activities showed no obvious changes during the restrictions and after the restrictions were lifted. The data further reveals whether people stay ''social distancing'', at least 6 feet apart. This study discerns whether social distancing is being followed in several types of locations and geographical locations worldwide and serve as an early indicator whether another wave of infections is likely to occur soon.