 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Local Code Optimization: Multi-Agent Reasoning for Software System Optimization
Mar 16, 2026Large language models and AI agents have recently shown promise in automating software performance optimization, but existing approaches predominantly rely on local, syntax-driven code transformations. This limits their ability to reason about program behavior and capture whole system performance interactions. As modern software increasingly comprises interacting components - such as microservices, databases, and shared infrastructure - effective code optimization requires reasoning about program structure and system architecture beyond individual functions or files. This paper explores the feasibility of whole system optimization for microservices. We introduce a multi-agent framework that integrates control-flow and data-flow representations with architectural and cross-component dependency signals to support system-level performance reasoning. The proposed system is decomposed into coordinated agent roles - summarization, analysis, optimization, and verification - that collaboratively identify cross-cutting bottlenecks and construct multi-step optimization strategies spanning the software stack. We present a proof-of-concept on a microservice-based system that illustrates the effectiveness of our proposed framework, achieving a 36.58% improvement in throughput and a 27.81% reduction in average response time.
How Do Agents Perform Code Optimization? An Empirical Study
Dec 25, 2025Performance optimization is a critical yet challenging aspect of software development, often requiring a deep understanding of system behavior, algorithmic tradeoffs, and careful code modifications. Although recent advances in AI coding agents have accelerated code generation and bug fixing, little is known about how these agents perform on real-world performance optimization tasks. We present the first empirical study comparing agent- and human-authored performance optimization commits, analyzing 324 agent-generated and 83 human-authored PRs from the AIDev dataset across adoption, maintainability, optimization patterns, and validation practices. We find that AI-authored performance PRs are less likely to include explicit performance validation than human-authored PRs (45.7\% vs. 63.6\%, $p=0.007$). In addition, AI-authored PRs largely use the same optimization patterns as humans. We further discuss limitations and opportunities for advancing agentic code optimization.
Improving the Reproducibility of Deep Learning Software: An Initial Investigation through a Case Study Analysis
May 06, 2025The field of deep learning has witnessed significant breakthroughs, spanning various applications, and fundamentally transforming current software capabilities. However, alongside these advancements, there have been increasing concerns about reproducing the results of these deep learning methods. This is significant because reproducibility is the foundation of reliability and validity in software development, particularly in the rapidly evolving domain of deep learning. The difficulty of reproducibility may arise due to several reasons, including having differences from the original execution environment, incompatible software libraries, proprietary data and source code, lack of transparency, and the stochastic nature in some software. A study conducted by the Nature journal reveals that more than 70% of researchers failed to reproduce other researchers experiments and over 50% failed to reproduce their own experiments. Irreproducibility of deep learning poses significant challenges for researchers and practitioners. To address these concerns, this paper presents a systematic approach at analyzing and improving the reproducibility of deep learning models by demonstrating these guidelines using a case study. We illustrate the patterns and anti-patterns involved with these guidelines for improving the reproducibility of deep learning models. These guidelines encompass establishing a methodology to replicate the original software environment, implementing end-to-end training and testing algorithms, disclosing architectural designs, and enhancing transparency in data processing and training pipelines. We also conduct a sensitivity analysis to understand the model performance across diverse conditions. By implementing these strategies, we aim to bridge the gap between research and practice, so that innovations in deep learning can be effectively reproduced and deployed within software.
Detecting Music Performance Errors with Transformers
Jan 03, 2025



Beginner musicians often struggle to identify specific errors in their performances, such as playing incorrect notes or rhythms. There are two limitations in existing tools for music error detection: (1) Existing approaches rely on automatic alignment; therefore, they are prone to errors caused by small deviations between alignment targets.; (2) There is a lack of sufficient data to train music error detection models, resulting in over-reliance on heuristics. To address (1), we propose a novel transformer model, Polytune, that takes audio inputs and outputs annotated music scores. This model can be trained end-to-end to implicitly align and compare performance audio with music scores through latent space representations. To address (2), we present a novel data generation technique capable of creating large-scale synthetic music error datasets. Our approach achieves a 64.1% average Error Detection F1 score, improving upon prior work by 40 percentage points across 14 instruments. Additionally, compared with existing transcription methods repurposed for music error detection, our model can handle multiple instruments. Our source code and datasets are available at https://github.com/ben2002chou/Polytune.
Recommending Pre-Trained Models for IoT Devices
Dec 25, 2024The availability of pre-trained models (PTMs) has enabled faster deployment of machine learning across applications by reducing the need for extensive training. Techniques like quantization and distillation have further expanded PTM applicability to resource-constrained IoT hardware. Given the many PTM options for any given task, engineers often find it too costly to evaluate each model's suitability. Approaches such as LogME, LEEP, and ModelSpider help streamline model selection by estimating task relevance without exhaustive tuning. However, these methods largely leave hardware constraints as future work-a significant limitation in IoT settings. In this paper, we identify the limitations of current model recommendation approaches regarding hardware constraints and introduce a novel, hardware-aware method for PTM selection. We also propose a research agenda to guide the development of effective, hardware-conscious model recommendation systems for IoT applications.
Token Turing Machines are Efficient Vision Models
Sep 11, 2024We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
What do we know about Hugging Face? A systematic literature review and quantitative validation of qualitative claims
Jun 12, 2024



Background: Collaborative Software Package Registries (SPRs) are an integral part of the software supply chain. Much engineering work synthesizes SPR package into applications. Prior research has examined SPRs for traditional software, such as NPM (JavaScript) and PyPI (Python). Pre-Trained Model (PTM) Registries are an emerging class of SPR of increasing importance, because they support the deep learning supply chain. Aims: Recent empirical research has examined PTM registries in ways such as vulnerabilities, reuse processes, and evolution. However, no existing research synthesizes them to provide a systematic understanding of the current knowledge. Some of the existing research includes qualitative claims lacking quantitative analysis. Our research fills these gaps by providing a knowledge synthesis and quantitative analyses. Methods: We first conduct a systematic literature review (SLR). We then observe that some of the claims are qualitative. We identify quantifiable metrics associated with those claims, and measure in order to substantiate these claims. Results: From our SLR, we identify 12 claims about PTM reuse on the HuggingFace platform, 4 of which lack quantitative validation. We successfully test 3 of these claims through a quantitative analysis, and directly compare one with traditional software. Our findings corroborate qualitative claims with quantitative measurements. Our findings are: (1) PTMs have a much higher turnover rate than traditional software, indicating a dynamic and rapidly evolving reuse environment within the PTM ecosystem; and (2) There is a strong correlation between documentation quality and PTM popularity. Conclusions: We confirm qualitative research claims with concrete metrics, supporting prior qualitative and case study research. Our measures show further dynamics of PTM reuse, inspiring research infrastructure and new measures.
A Partial Replication of MaskFormer in TensorFlow on TPUs for the TensorFlow Model Garden
Apr 29, 2024This paper undertakes the task of replicating the MaskFormer model a universal image segmentation model originally developed using the PyTorch framework, within the TensorFlow ecosystem, specifically optimized for execution on Tensor Processing Units (TPUs). Our implementation exploits the modular constructs available within the TensorFlow Model Garden (TFMG), encompassing elements such as the data loader, training orchestrator, and various architectural components, tailored and adapted to meet the specifications of the MaskFormer model. We address key challenges encountered during the replication, non-convergence issues, slow training, adaptation of loss functions, and the integration of TPU-specific functionalities. We verify our reproduced implementation and present qualitative results on the COCO dataset. Although our implementation meets some of the objectives for end-to-end reproducibility, we encountered challenges in replicating the PyTorch version of MaskFormer in TensorFlow. This replication process is not straightforward and requires substantial engineering efforts. Specifically, it necessitates the customization of various components within the TFMG, alongside thorough verification and hyper-parameter tuning. The replication is available at: https://github.com/PurdueDualityLab/tf-maskformer/tree/main/official/projects/maskformer
PeaTMOSS: A Dataset and Initial Analysis of Pre-Trained Models in Open-Source Software
Feb 01, 2024
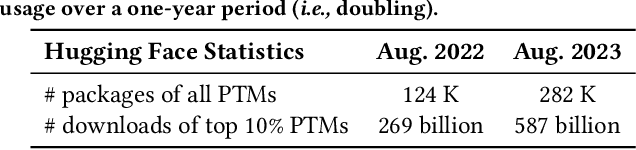
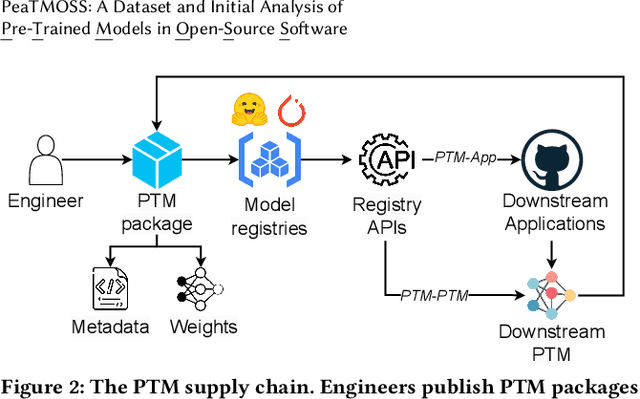

The development and training of deep learning models have become increasingly costly and complex. Consequently, software engineers are adopting pre-trained models (PTMs) for their downstream applications. The dynamics of the PTM supply chain remain largely unexplored, signaling a clear need for structured datasets that document not only the metadata but also the subsequent applications of these models. Without such data, the MSR community cannot comprehensively understand the impact of PTM adoption and reuse. This paper presents the PeaTMOSS dataset, which comprises metadata for 281,638 PTMs and detailed snapshots for all PTMs with over 50 monthly downloads (14,296 PTMs), along with 28,575 open-source software repositories from GitHub that utilize these models. Additionally, the dataset includes 44,337 mappings from 15,129 downstream GitHub repositories to the 2,530 PTMs they use. To enhance the dataset's comprehensiveness, we developed prompts for a large language model to automatically extract model metadata, including the model's training datasets, parameters, and evaluation metrics. Our analysis of this dataset provides the first summary statistics for the PTM supply chain, showing the trend of PTM development and common shortcomings of PTM package documentation. Our example application reveals inconsistencies in software licenses across PTMs and their dependent projects. PeaTMOSS lays the foundation for future research, offering rich opportunities to investigate the PTM supply chain. We outline mining opportunities on PTMs, their downstream usage, and cross-cutting questions.
PeaTMOSS: Mining Pre-Trained Models in Open-Source Software
Oct 05, 2023



Developing and training deep learning models is expensive, so software engineers have begun to reuse pre-trained deep learning models (PTMs) and fine-tune them for downstream tasks. Despite the wide-spread use of PTMs, we know little about the corresponding software engineering behaviors and challenges. To enable the study of software engineering with PTMs, we present the PeaTMOSS dataset: Pre-Trained Models in Open-Source Software. PeaTMOSS has three parts: a snapshot of (1) 281,638 PTMs, (2) 27,270 open-source software repositories that use PTMs, and (3) a mapping between PTMs and the projects that use them. We challenge PeaTMOSS miners to discover software engineering practices around PTMs. A demo and link to the full dataset are available at: https://github.com/PurdueDualityLab/PeaTMOSS-Demos.