 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Music Performance Errors with Transformers
Jan 03, 2025



Beginner musicians often struggle to identify specific errors in their performances, such as playing incorrect notes or rhythms. There are two limitations in existing tools for music error detection: (1) Existing approaches rely on automatic alignment; therefore, they are prone to errors caused by small deviations between alignment targets.; (2) There is a lack of sufficient data to train music error detection models, resulting in over-reliance on heuristics. To address (1), we propose a novel transformer model, Polytune, that takes audio inputs and outputs annotated music scores. This model can be trained end-to-end to implicitly align and compare performance audio with music scores through latent space representations. To address (2), we present a novel data generation technique capable of creating large-scale synthetic music error datasets. Our approach achieves a 64.1% average Error Detection F1 score, improving upon prior work by 40 percentage points across 14 instruments. Additionally, compared with existing transcription methods repurposed for music error detection, our model can handle multiple instruments. Our source code and datasets are available at https://github.com/ben2002chou/Polytune.
Token Turing Machines are Efficient Vision Models
Sep 11, 2024We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
Reducing Vision Transformer Latency on Edge Devices via GPU Tail Effect and Training-free Token Pruning
Jul 01, 2024This paper investigates how to efficiently deploy transformer-based neural networks on edge devices. Recent methods reduce the latency of transformer neural networks by removing or merging tokens, with small accuracy degradation. However, these methods are not designed with edge device deployment in mind, and do not leverage information about the hardware characteristics to improve efficiency. First, we show that the relationship between latency and workload size is governed by the GPU tail-effect. This relationship is used to create a token pruning schedule tailored for a pre-trained model and device pair. Second, we demonstrate a training-free token pruning method utilizing this relationship. This method achieves accuracy-latency trade-offs in a hardware aware manner. We show that for single batch inference, other methods may actually increase latency by 18.6-30.3% with respect to baseline, while we can reduce it by 9%. For similar latency (within 5.2%) across devices we achieve 78.6%-84.5% ImageNet1K accuracy, while the state-of-the-art, Token Merging, achieves 45.8%-85.4%.
An automated approach for improving the inference latency and energy efficiency of pretrained CNNs by removing irrelevant pixels with focused convolutions
Oct 11, 2023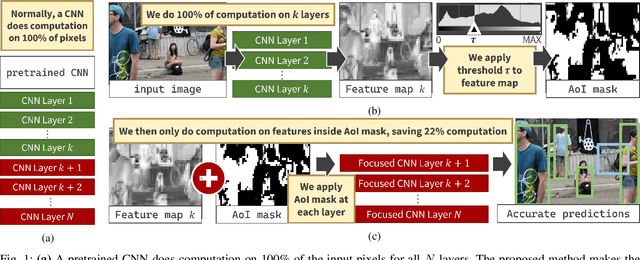
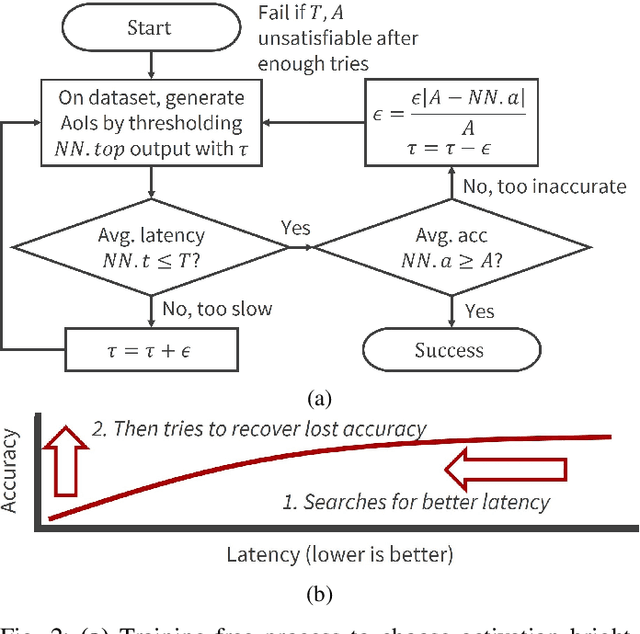

Computer vision often uses highly accurate Convolutional Neural Networks (CNNs), but these deep learning models are associated with ever-increasing energy and computation requirements. Producing more energy-efficient CNNs often requires model training which can be cost-prohibitive. We propose a novel, automated method to make a pretrained CNN more energy-efficient without re-training. Given a pretrained CNN, we insert a threshold layer that filters activations from the preceding layers to identify regions of the image that are irrelevant, i.e. can be ignored by the following layers while maintaining accuracy. Our modified focused convolution operation saves inference latency (by up to 25%) and energy costs (by up to 22%) on various popular pretrained CNNs, with little to no loss in accuracy.
Analysis of Failures and Risks in Deep Learning Model Converters: A Case Study in the ONNX Ecosystem
Mar 30, 2023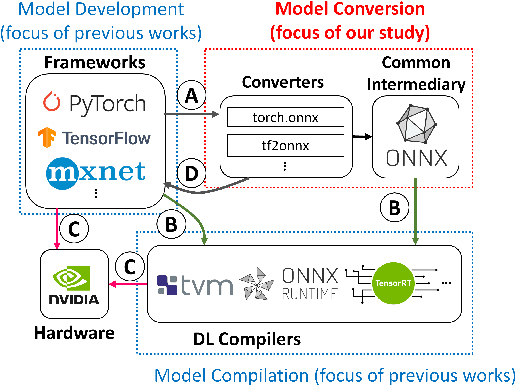
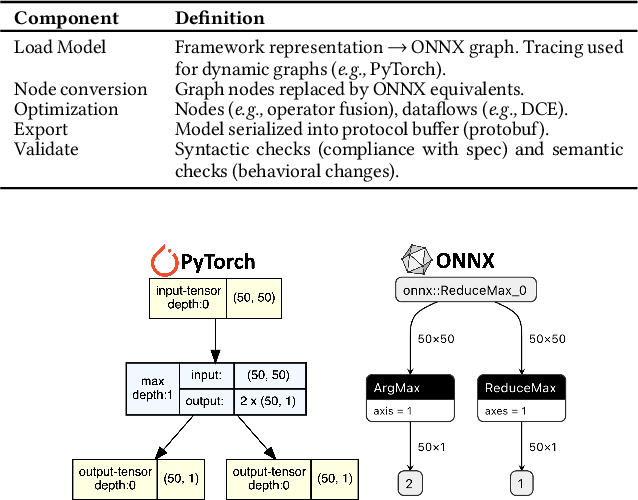

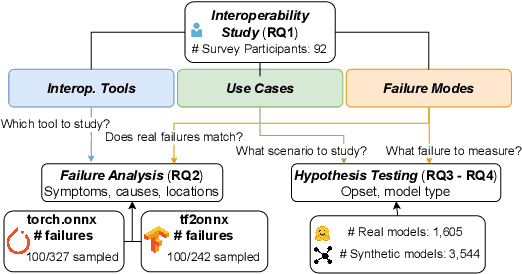
Software engineers develop, fine-tune, and deploy deep learning (DL) models. They use and re-use models in a variety of development frameworks and deploy them on a range of runtime environments. In this diverse ecosystem, engineers use DL model converters to move models from frameworks to runtime environments. However, errors in converters can compromise model quality and disrupt deployment. The failure frequency and failure modes of DL model converters are unknown. In this paper, we conduct the first failure analysis on DL model converters. Specifically, we characterize failures in model converters associated with ONNX (Open Neural Network eXchange). We analyze past failures in the ONNX converters in two major DL frameworks, PyTorch and TensorFlow. The symptoms, causes, and locations of failures (for N=200 issues), and trends over time are also reported. We also evaluate present-day failures by converting 8,797 models, both real-world and synthetically generated instances. The consistent result from both parts of the study is that DL model converters commonly fail by producing models that exhibit incorrect behavior: 33% of past failures and 8% of converted models fell into this category. Our results motivate future research on making DL software simpler to maintain, extend, and validate.