 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Intervals for Evaluation of Data Mining
Feb 10, 2025



In data mining, when binary prediction rules are used to predict a binary outcome, many performance measures are used in a vast array of literature for the purposes of evaluation and comparison. Some examples include classification accuracy, precision, recall, F measures, and Jaccard index. Typically, these performance measures are only approximately estimated from a finite dataset, which may lead to findings that are not statistically significant. In order to properly quantify such statistical uncertainty, it is important to provide confidence intervals associated with these estimated performance measures. We consider statistical inference about general performance measures used in data mining, with both individual and joint confidence intervals. These confidence intervals are based on asymptotic normal approximations and can be computed fast, without needs to do bootstrap resampling. We study the finite sample coverage probabilities for these confidence intervals and also propose a `blurring correction' on the variance to improve the finite sample performance. This 'blurring correction' generalizes the plus-four method from binomial proportion to general performance measures used in data mining. Our framework allows multiple performance measures of multiple classification rules to be inferred simultaneously for comparisons.
Recommending Pre-Trained Models for IoT Devices
Dec 25, 2024The availability of pre-trained models (PTMs) has enabled faster deployment of machine learning across applications by reducing the need for extensive training. Techniques like quantization and distillation have further expanded PTM applicability to resource-constrained IoT hardware. Given the many PTM options for any given task, engineers often find it too costly to evaluate each model's suitability. Approaches such as LogME, LEEP, and ModelSpider help streamline model selection by estimating task relevance without exhaustive tuning. However, these methods largely leave hardware constraints as future work-a significant limitation in IoT settings. In this paper, we identify the limitations of current model recommendation approaches regarding hardware constraints and introduce a novel, hardware-aware method for PTM selection. We also propose a research agenda to guide the development of effective, hardware-conscious model recommendation systems for IoT applications.
What do we know about Hugging Face? A systematic literature review and quantitative validation of qualitative claims
Jun 12, 2024



Background: Collaborative Software Package Registries (SPRs) are an integral part of the software supply chain. Much engineering work synthesizes SPR package into applications. Prior research has examined SPRs for traditional software, such as NPM (JavaScript) and PyPI (Python). Pre-Trained Model (PTM) Registries are an emerging class of SPR of increasing importance, because they support the deep learning supply chain. Aims: Recent empirical research has examined PTM registries in ways such as vulnerabilities, reuse processes, and evolution. However, no existing research synthesizes them to provide a systematic understanding of the current knowledge. Some of the existing research includes qualitative claims lacking quantitative analysis. Our research fills these gaps by providing a knowledge synthesis and quantitative analyses. Methods: We first conduct a systematic literature review (SLR). We then observe that some of the claims are qualitative. We identify quantifiable metrics associated with those claims, and measure in order to substantiate these claims. Results: From our SLR, we identify 12 claims about PTM reuse on the HuggingFace platform, 4 of which lack quantitative validation. We successfully test 3 of these claims through a quantitative analysis, and directly compare one with traditional software. Our findings corroborate qualitative claims with quantitative measurements. Our findings are: (1) PTMs have a much higher turnover rate than traditional software, indicating a dynamic and rapidly evolving reuse environment within the PTM ecosystem; and (2) There is a strong correlation between documentation quality and PTM popularity. Conclusions: We confirm qualitative research claims with concrete metrics, supporting prior qualitative and case study research. Our measures show further dynamics of PTM reuse, inspiring research infrastructure and new measures.
A Partial Replication of MaskFormer in TensorFlow on TPUs for the TensorFlow Model Garden
Apr 29, 2024This paper undertakes the task of replicating the MaskFormer model a universal image segmentation model originally developed using the PyTorch framework, within the TensorFlow ecosystem, specifically optimized for execution on Tensor Processing Units (TPUs). Our implementation exploits the modular constructs available within the TensorFlow Model Garden (TFMG), encompassing elements such as the data loader, training orchestrator, and various architectural components, tailored and adapted to meet the specifications of the MaskFormer model. We address key challenges encountered during the replication, non-convergence issues, slow training, adaptation of loss functions, and the integration of TPU-specific functionalities. We verify our reproduced implementation and present qualitative results on the COCO dataset. Although our implementation meets some of the objectives for end-to-end reproducibility, we encountered challenges in replicating the PyTorch version of MaskFormer in TensorFlow. This replication process is not straightforward and requires substantial engineering efforts. Specifically, it necessitates the customization of various components within the TFMG, alongside thorough verification and hyper-parameter tuning. The replication is available at: https://github.com/PurdueDualityLab/tf-maskformer/tree/main/official/projects/maskformer
PeaTMOSS: A Dataset and Initial Analysis of Pre-Trained Models in Open-Source Software
Feb 01, 2024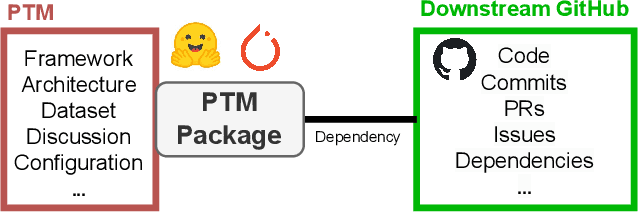
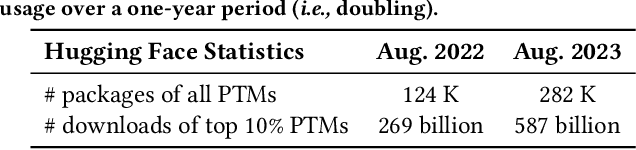
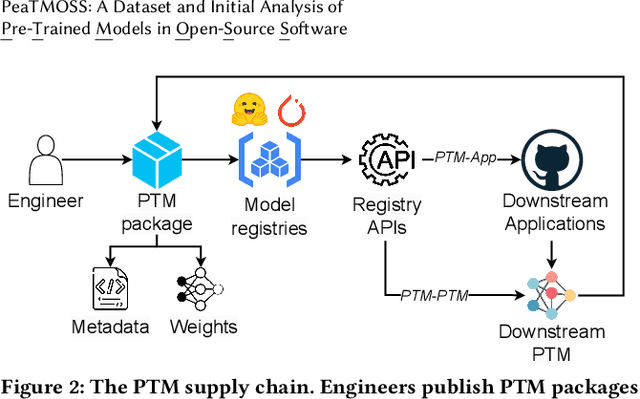

The development and training of deep learning models have become increasingly costly and complex. Consequently, software engineers are adopting pre-trained models (PTMs) for their downstream applications. The dynamics of the PTM supply chain remain largely unexplored, signaling a clear need for structured datasets that document not only the metadata but also the subsequent applications of these models. Without such data, the MSR community cannot comprehensively understand the impact of PTM adoption and reuse. This paper presents the PeaTMOSS dataset, which comprises metadata for 281,638 PTMs and detailed snapshots for all PTMs with over 50 monthly downloads (14,296 PTMs), along with 28,575 open-source software repositories from GitHub that utilize these models. Additionally, the dataset includes 44,337 mappings from 15,129 downstream GitHub repositories to the 2,530 PTMs they use. To enhance the dataset's comprehensiveness, we developed prompts for a large language model to automatically extract model metadata, including the model's training datasets, parameters, and evaluation metrics. Our analysis of this dataset provides the first summary statistics for the PTM supply chain, showing the trend of PTM development and common shortcomings of PTM package documentation. Our example application reveals inconsistencies in software licenses across PTMs and their dependent projects. PeaTMOSS lays the foundation for future research, offering rich opportunities to investigate the PTM supply chain. We outline mining opportunities on PTMs, their downstream usage, and cross-cutting questions.
PeaTMOSS: Mining Pre-Trained Models in Open-Source Software
Oct 05, 2023



Developing and training deep learning models is expensive, so software engineers have begun to reuse pre-trained deep learning models (PTMs) and fine-tune them for downstream tasks. Despite the wide-spread use of PTMs, we know little about the corresponding software engineering behaviors and challenges. To enable the study of software engineering with PTMs, we present the PeaTMOSS dataset: Pre-Trained Models in Open-Source Software. PeaTMOSS has three parts: a snapshot of (1) 281,638 PTMs, (2) 27,270 open-source software repositories that use PTMs, and (3) a mapping between PTMs and the projects that use them. We challenge PeaTMOSS miners to discover software engineering practices around PTMs. A demo and link to the full dataset are available at: https://github.com/PurdueDualityLab/PeaTMOSS-Demos.
Exploring Naming Conventions (and Defects) of Pre-trained Deep Learning Models in Hugging Face and Other Model Hubs
Oct 02, 2023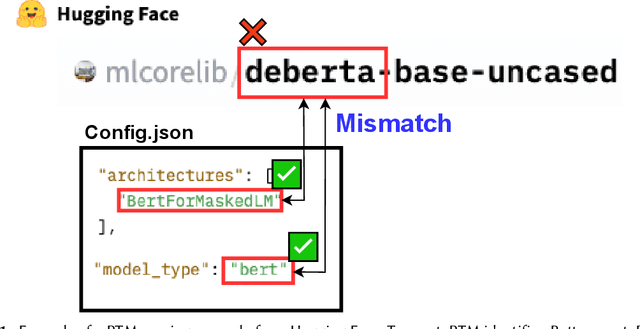
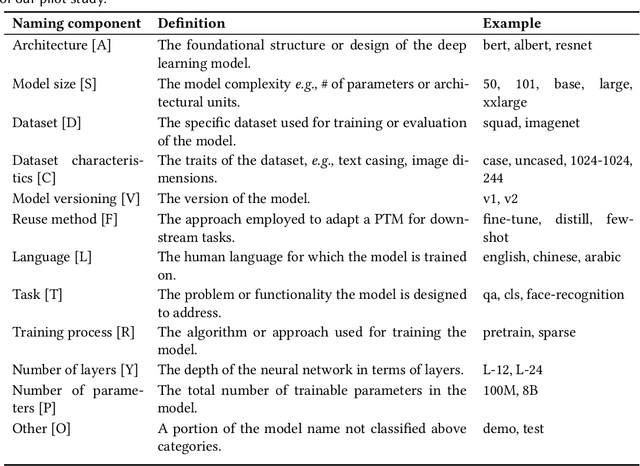
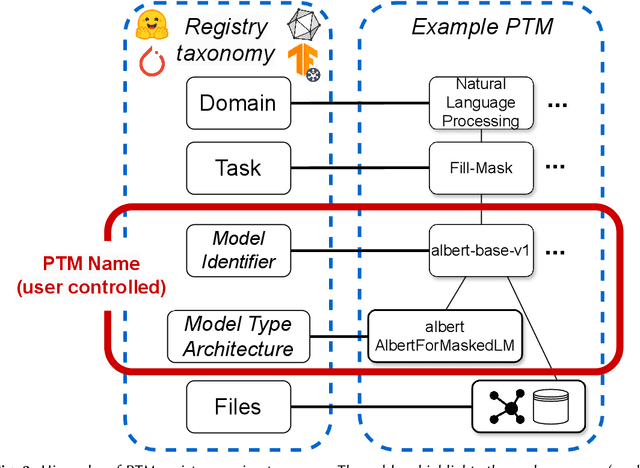

As innovation in deep learning continues, many engineers want to adopt Pre-Trained deep learning Models (PTMs) as components in computer systems. PTMs are part of a research-to-practice pipeline: researchers publish PTMs, which engineers adapt for quality or performance and then deploy. If PTM authors choose appropriate names for their PTMs, it could facilitate model discovery and reuse. However, prior research has reported that model names are not always well chosen, and are sometimes erroneous. The naming conventions and naming defects for PTM packages have not been systematically studied - understanding them will add to our knowledge of how the research-to-practice process works for PTM packages In this paper, we report the first study of PTM naming conventions and the associated PTM naming defects. We define the components of a PTM package name, comprising the package name and claimed architecture from the metadata. We present the first study focused on characterizing the nature of naming in PTM ecosystem. To this end, we developed a novel automated naming assessment technique that can automatically extract the semantic and syntactic patterns. To identify potential naming defects, we developed a novel algorithm, automated DNN ARchitecture Assessment pipeline (DARA), to cluster PTMs based on architectural differences. Our study suggests the naming conventions for PTMs, and frames the naming conventions as signal of the research-to-practice relationships in the PTM ecosystem. We envision future works on further empirical study on leveraging meta-features of PTMs to support model search and reuse.
Analysis of Failures and Risks in Deep Learning Model Converters: A Case Study in the ONNX Ecosystem
Mar 30, 2023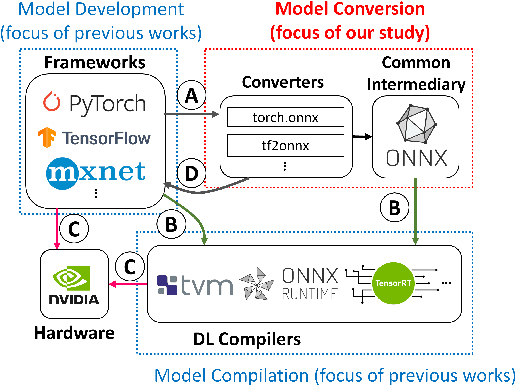
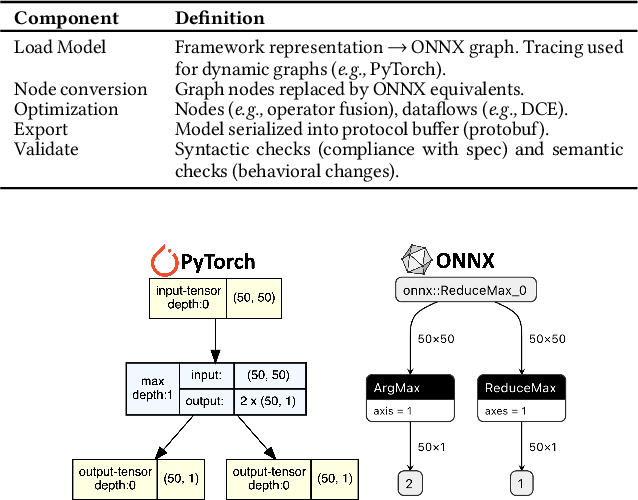

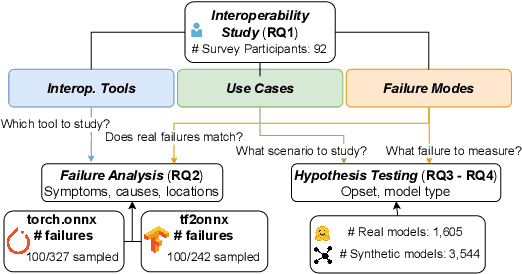
Software engineers develop, fine-tune, and deploy deep learning (DL) models. They use and re-use models in a variety of development frameworks and deploy them on a range of runtime environments. In this diverse ecosystem, engineers use DL model converters to move models from frameworks to runtime environments. However, errors in converters can compromise model quality and disrupt deployment. The failure frequency and failure modes of DL model converters are unknown. In this paper, we conduct the first failure analysis on DL model converters. Specifically, we characterize failures in model converters associated with ONNX (Open Neural Network eXchange). We analyze past failures in the ONNX converters in two major DL frameworks, PyTorch and TensorFlow. The symptoms, causes, and locations of failures (for N=200 issues), and trends over time are also reported. We also evaluate present-day failures by converting 8,797 models, both real-world and synthetically generated instances. The consistent result from both parts of the study is that DL model converters commonly fail by producing models that exhibit incorrect behavior: 33% of past failures and 8% of converted models fell into this category. Our results motivate future research on making DL software simpler to maintain, extend, and validate.
Challenges and Practices of Deep Learning Model Reengineering: A Case Study on Computer Vision
Mar 13, 2023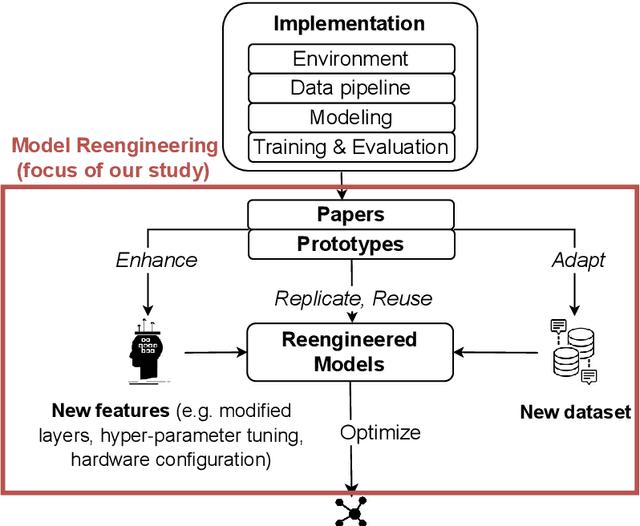


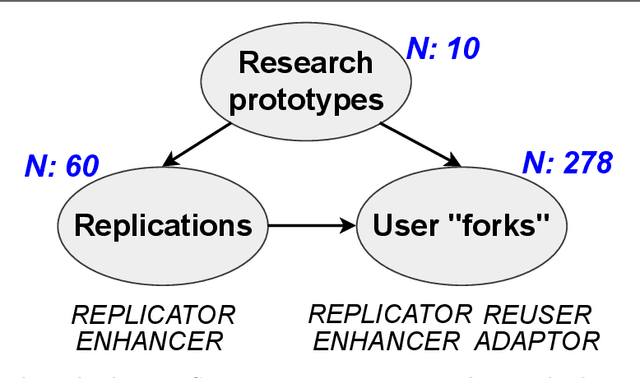
Many engineering organizations are reimplementing and extending deep neural networks from the research community. We describe this process as deep learning model reengineering. Deep learning model reengineering - reusing, reproducing, adapting, and enhancing state-of-the-art deep learning approaches - is challenging for reasons including under-documented reference models, changing requirements, and the cost of implementation and testing. In addition, individual engineers may lack expertise in software engineering, yet teams must apply knowledge of software engineering and deep learning to succeed. Prior work has examined on DL systems from a "product" view, examining defects from projects regardless of the engineers' purpose. Our study is focused on reengineering activities from a "process" view, and focuses on engineers specifically engaged in the reengineering process. Our goal is to understand the characteristics and challenges of deep learning model reengineering. We conducted a case study of this phenomenon, focusing on the context of computer vision. Our results draw from two data sources: defects reported in open-source reeengineering projects, and interviews conducted with open-source project contributors and the leaders of a reengineering team. Our results describe how deep learning-based computer vision techniques are reengineered, analyze the distribution of defects in this process, and discuss challenges and practices. Integrating our quantitative and qualitative data, we proposed a novel reengineering workflow. Our findings inform several future directions, including: measuring additional unknown aspects of model reengineering; standardizing engineering practices to facilitate reengineering; and developing tools to support model reengineering and model reuse.
An Empirical Study of Pre-Trained Model Reuse in the Hugging Face Deep Learning Model Registry
Mar 05, 2023Deep Neural Networks (DNNs) are being adopted as components in software systems. Creating and specializing DNNs from scratch has grown increasingly difficult as state-of-the-art architectures grow more complex. Following the path of traditional software engineering, machine learning engineers have begun to reuse large-scale pre-trained models (PTMs) and fine-tune these models for downstream tasks. Prior works have studied reuse practices for traditional software packages to guide software engineers towards better package maintenance and dependency management. We lack a similar foundation of knowledge to guide behaviors in pre-trained model ecosystems. In this work, we present the first empirical investigation of PTM reuse. We interviewed 12 practitioners from the most popular PTM ecosystem, Hugging Face, to learn the practices and challenges of PTM reuse. From this data, we model the decision-making process for PTM reuse. Based on the identified practices, we describe useful attributes for model reuse, including provenance, reproducibility, and portability. Three challenges for PTM reuse are missing attributes, discrepancies between claimed and actual performance, and model risks. We substantiate these identified challenges with systematic measurements in the Hugging Face ecosystem. Our work informs future directions on optimizing deep learning ecosystems by automated measuring useful attributes and potential attacks, and envision future research on infrastructure and standardization for model registries.