 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Naming Conventions (and Defects) of Pre-trained Deep Learning Models in Hugging Face and Other Model Hubs
Oct 02, 2023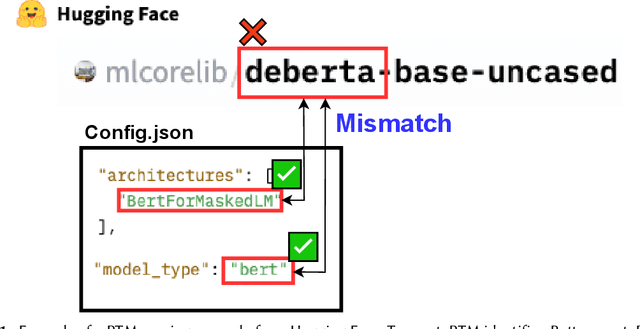
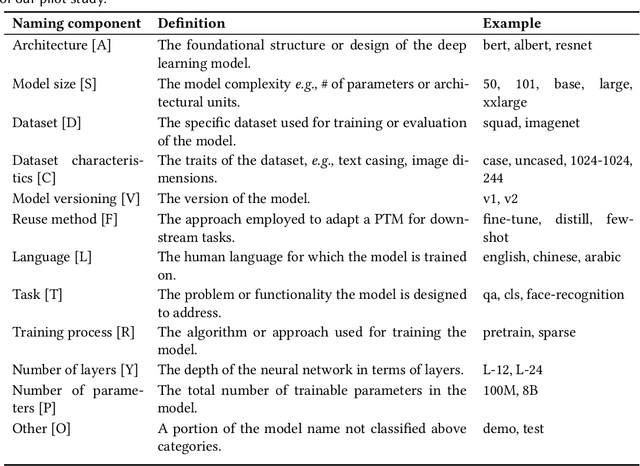
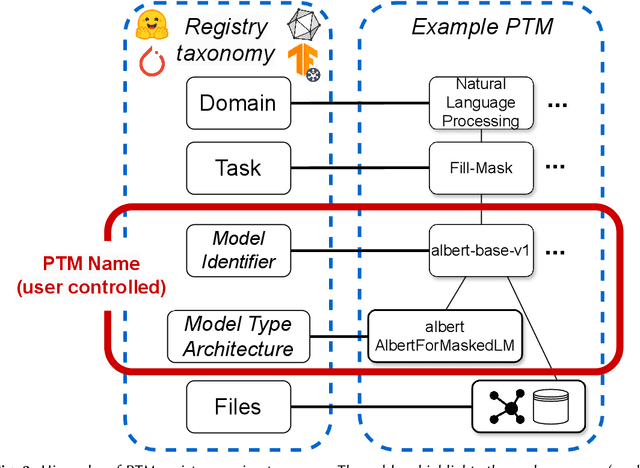

As innovation in deep learning continues, many engineers want to adopt Pre-Trained deep learning Models (PTMs) as components in computer systems. PTMs are part of a research-to-practice pipeline: researchers publish PTMs, which engineers adapt for quality or performance and then deploy. If PTM authors choose appropriate names for their PTMs, it could facilitate model discovery and reuse. However, prior research has reported that model names are not always well chosen, and are sometimes erroneous. The naming conventions and naming defects for PTM packages have not been systematically studied - understanding them will add to our knowledge of how the research-to-practice process works for PTM packages In this paper, we report the first study of PTM naming conventions and the associated PTM naming defects. We define the components of a PTM package name, comprising the package name and claimed architecture from the metadata. We present the first study focused on characterizing the nature of naming in PTM ecosystem. To this end, we developed a novel automated naming assessment technique that can automatically extract the semantic and syntactic patterns. To identify potential naming defects, we developed a novel algorithm, automated DNN ARchitecture Assessment pipeline (DARA), to cluster PTMs based on architectural differences. Our study suggests the naming conventions for PTMs, and frames the naming conventions as signal of the research-to-practice relationships in the PTM ecosystem. We envision future works on further empirical study on leveraging meta-features of PTMs to support model search and reuse.