 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRWESummary: A Framework and Test for Choosing Large Language Models to Summarize Real-World Evidence (RWE) Studies
Jun 23, 2025

Large Language Models (LLMs) have been extensively evaluated for general summarization tasks as well as medical research assistance, but they have not been specifically evaluated for the task of summarizing real-world evidence (RWE) from structured output of RWE studies. We introduce RWESummary, a proposed addition to the MedHELM framework (Bedi, Cui, Fuentes, Unell et al., 2025) to enable benchmarking of LLMs for this task. RWESummary includes one scenario and three evaluations covering major types of errors observed in summarization of medical research studies and was developed using Atropos Health proprietary data. Additionally, we use RWESummary to compare the performance of different LLMs in our internal RWE summarization tool. At the time of publication, with 13 distinct RWE studies, we found the Gemini 2.5 models performed best overall (both Flash and Pro). We suggest RWESummary as a novel and useful foundation model benchmark for real-world evidence study summarization.
What do we know about Hugging Face? A systematic literature review and quantitative validation of qualitative claims
Jun 12, 2024



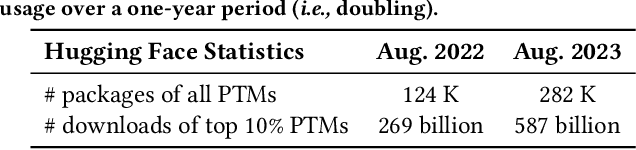
Background: Collaborative Software Package Registries (SPRs) are an integral part of the software supply chain. Much engineering work synthesizes SPR package into applications. Prior research has examined SPRs for traditional software, such as NPM (JavaScript) and PyPI (Python). Pre-Trained Model (PTM) Registries are an emerging class of SPR of increasing importance, because they support the deep learning supply chain. Aims: Recent empirical research has examined PTM registries in ways such as vulnerabilities, reuse processes, and evolution. However, no existing research synthesizes them to provide a systematic understanding of the current knowledge. Some of the existing research includes qualitative claims lacking quantitative analysis. Our research fills these gaps by providing a knowledge synthesis and quantitative analyses. Methods: We first conduct a systematic literature review (SLR). We then observe that some of the claims are qualitative. We identify quantifiable metrics associated with those claims, and measure in order to substantiate these claims. Results: From our SLR, we identify 12 claims about PTM reuse on the HuggingFace platform, 4 of which lack quantitative validation. We successfully test 3 of these claims through a quantitative analysis, and directly compare one with traditional software. Our findings corroborate qualitative claims with quantitative measurements. Our findings are: (1) PTMs have a much higher turnover rate than traditional software, indicating a dynamic and rapidly evolving reuse environment within the PTM ecosystem; and (2) There is a strong correlation between documentation quality and PTM popularity. Conclusions: We confirm qualitative research claims with concrete metrics, supporting prior qualitative and case study research. Our measures show further dynamics of PTM reuse, inspiring research infrastructure and new measures.
PeaTMOSS: A Dataset and Initial Analysis of Pre-Trained Models in Open-Source Software
Feb 01, 2024
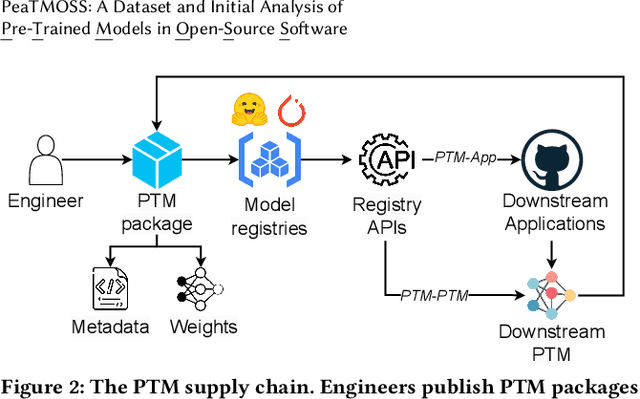

The development and training of deep learning models have become increasingly costly and complex. Consequently, software engineers are adopting pre-trained models (PTMs) for their downstream applications. The dynamics of the PTM supply chain remain largely unexplored, signaling a clear need for structured datasets that document not only the metadata but also the subsequent applications of these models. Without such data, the MSR community cannot comprehensively understand the impact of PTM adoption and reuse. This paper presents the PeaTMOSS dataset, which comprises metadata for 281,638 PTMs and detailed snapshots for all PTMs with over 50 monthly downloads (14,296 PTMs), along with 28,575 open-source software repositories from GitHub that utilize these models. Additionally, the dataset includes 44,337 mappings from 15,129 downstream GitHub repositories to the 2,530 PTMs they use. To enhance the dataset's comprehensiveness, we developed prompts for a large language model to automatically extract model metadata, including the model's training datasets, parameters, and evaluation metrics. Our analysis of this dataset provides the first summary statistics for the PTM supply chain, showing the trend of PTM development and common shortcomings of PTM package documentation. Our example application reveals inconsistencies in software licenses across PTMs and their dependent projects. PeaTMOSS lays the foundation for future research, offering rich opportunities to investigate the PTM supply chain. We outline mining opportunities on PTMs, their downstream usage, and cross-cutting questions.
PeaTMOSS: Mining Pre-Trained Models in Open-Source Software
Oct 05, 2023



Developing and training deep learning models is expensive, so software engineers have begun to reuse pre-trained deep learning models (PTMs) and fine-tune them for downstream tasks. Despite the wide-spread use of PTMs, we know little about the corresponding software engineering behaviors and challenges. To enable the study of software engineering with PTMs, we present the PeaTMOSS dataset: Pre-Trained Models in Open-Source Software. PeaTMOSS has three parts: a snapshot of (1) 281,638 PTMs, (2) 27,270 open-source software repositories that use PTMs, and (3) a mapping between PTMs and the projects that use them. We challenge PeaTMOSS miners to discover software engineering practices around PTMs. A demo and link to the full dataset are available at: https://github.com/PurdueDualityLab/PeaTMOSS-Demos.