 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Winning Solutions of 2025 Low Power Computer Vision Challenge
Apr 22, 2026The IEEE Low-Power Computer Vision Challenge (LPCVC) aims to promote the development of efficient vision models for edge devices, balancing accuracy with constraints such as latency, memory capacity, and energy use. The 2025 challenge featured three tracks: (1) Image classification under various lighting conditions and styles, (2) Open-Vocabulary Segmentation with Text Prompt, and (3) Monocular Depth Estimation. This paper presents the design of LPCVC 2025, including its competition structure and evaluation framework, which integrates the Qualcomm AI Hub for consistent and reproducible benchmarking. The paper also introduces the top-performing solutions from each track and outlines key trends and observations. The paper concludes with suggestions for future computer vision competitions.
Real-Time Cellist Postural Evaluation With On-Device Computer Vision
Apr 19, 2026Posture is a critical factor for beginning instrumental learners. Most students receive instruction only once a week, and during the intervals between lessons they have little or no feedback on their physical posture. As a result, posture often deteriorates, increasing the risk of musculoskeletal injury and inefficient technique. Recent advances in computer vision and machine learning make it possible to evaluate posture without the constant presence of a human expert. However, current solutions have been extremely limited in availability and convenience due to their reliance on computationally expensive hardware or multi-sensor setups. We present Cello Evaluator, a real-time postural feedback system for practicing cellists. Through this optimization for on-device computer vision inference, we provide access to cellist postural evaluation to anyone with a current generation Android phone and thus reduces the postural feedback voids within individual practice. To validate our mobile application, we conduct a heuristic evaluation consisting of cellist and UX experts. Overall feedback from the evaluation found the app to be user friendly and helpful.
Advancing Multi-Instrument Music Transcription: Results from the 2025 AMT Challenge
Mar 29, 2026This paper presents the results of the 2025 Automatic Music Transcription (AMT) Challenge, an online competition to benchmark progress in multi-instrument transcription. Eight teams submitted valid solutions; two outperformed the baseline MT3 model. The results highlight both advances in transcription accuracy and the remaining difficulties in handling polyphony and timbre variation. We conclude with directions for future challenges: broader genre coverage and stronger emphasis on instrument detection.
From Score to Sound: An End-to-End MIDI-to-Motion Pipeline for Robotic Cello Performance
Jan 07, 2026Robot musicians require precise control to obtain proper note accuracy, sound quality, and musical expression. Performance of string instruments, such as violin and cello, presents a significant challenge due to the precise control required over bow angle and pressure to produce the desired sound. While prior robotic cellists focus on accurate bowing trajectories, these works often rely on expensive motion capture techniques, and fail to sightread music in a human-like way. We propose a novel end-to-end MIDI score to robotic motion pipeline which converts musical input directly into collision-aware bowing motions for a UR5e robot cellist. Through use of Universal Robot Freedrive feature, our robotic musician can achieve human-like sound without the need for motion capture. Additionally, this work records live joint data via Real-Time Data Exchange (RTDE) as the robot plays, providing labeled robotic playing data from a collection of five standard pieces to the research community. To demonstrate the effectiveness of our method in comparison to human performers, we introduce the Musical Turing Test, in which a collection of 132 human participants evaluate our robot's performance against a human baseline. Human reference recordings are also released, enabling direct comparison for future studies. This evaluation technique establishes the first benchmark for robotic cello performance. Finally, we outline a residual reinforcement learning methodology to improve upon baseline robotic controls, highlighting future opportunities for improved string-crossing efficiency and sound quality.
Detecting Music Performance Errors with Transformers
Jan 03, 2025



Beginner musicians often struggle to identify specific errors in their performances, such as playing incorrect notes or rhythms. There are two limitations in existing tools for music error detection: (1) Existing approaches rely on automatic alignment; therefore, they are prone to errors caused by small deviations between alignment targets.; (2) There is a lack of sufficient data to train music error detection models, resulting in over-reliance on heuristics. To address (1), we propose a novel transformer model, Polytune, that takes audio inputs and outputs annotated music scores. This model can be trained end-to-end to implicitly align and compare performance audio with music scores through latent space representations. To address (2), we present a novel data generation technique capable of creating large-scale synthetic music error datasets. Our approach achieves a 64.1% average Error Detection F1 score, improving upon prior work by 40 percentage points across 14 instruments. Additionally, compared with existing transcription methods repurposed for music error detection, our model can handle multiple instruments. Our source code and datasets are available at https://github.com/ben2002chou/Polytune.
Token Turing Machines are Efficient Vision Models
Sep 11, 2024We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
Reducing Vision Transformer Latency on Edge Devices via GPU Tail Effect and Training-free Token Pruning
Jul 01, 2024This paper investigates how to efficiently deploy transformer-based neural networks on edge devices. Recent methods reduce the latency of transformer neural networks by removing or merging tokens, with small accuracy degradation. However, these methods are not designed with edge device deployment in mind, and do not leverage information about the hardware characteristics to improve efficiency. First, we show that the relationship between latency and workload size is governed by the GPU tail-effect. This relationship is used to create a token pruning schedule tailored for a pre-trained model and device pair. Second, we demonstrate a training-free token pruning method utilizing this relationship. This method achieves accuracy-latency trade-offs in a hardware aware manner. We show that for single batch inference, other methods may actually increase latency by 18.6-30.3% with respect to baseline, while we can reduce it by 9%. For similar latency (within 5.2%) across devices we achieve 78.6%-84.5% ImageNet1K accuracy, while the state-of-the-art, Token Merging, achieves 45.8%-85.4%.
An automated approach for improving the inference latency and energy efficiency of pretrained CNNs by removing irrelevant pixels with focused convolutions
Oct 11, 2023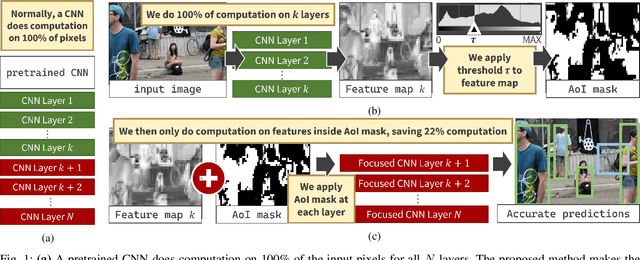
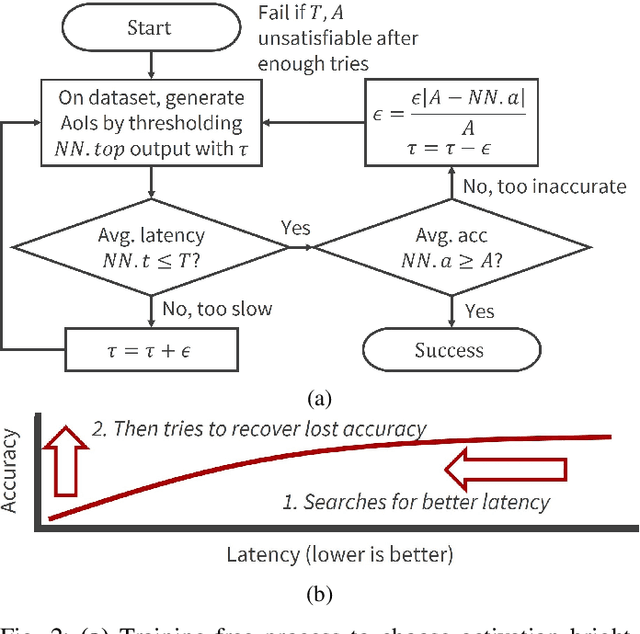
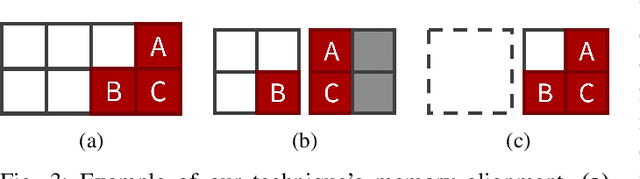

Computer vision often uses highly accurate Convolutional Neural Networks (CNNs), but these deep learning models are associated with ever-increasing energy and computation requirements. Producing more energy-efficient CNNs often requires model training which can be cost-prohibitive. We propose a novel, automated method to make a pretrained CNN more energy-efficient without re-training. Given a pretrained CNN, we insert a threshold layer that filters activations from the preceding layers to identify regions of the image that are irrelevant, i.e. can be ignored by the following layers while maintaining accuracy. Our modified focused convolution operation saves inference latency (by up to 25%) and energy costs (by up to 22%) on various popular pretrained CNNs, with little to no loss in accuracy.
Analysis of Failures and Risks in Deep Learning Model Converters: A Case Study in the ONNX Ecosystem
Mar 30, 2023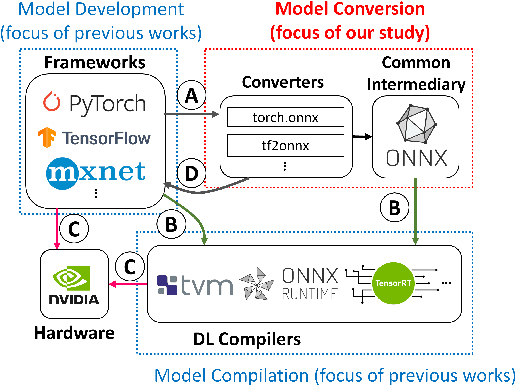
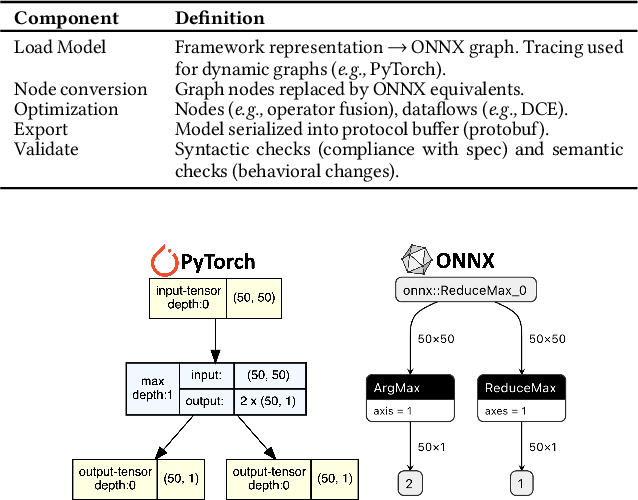

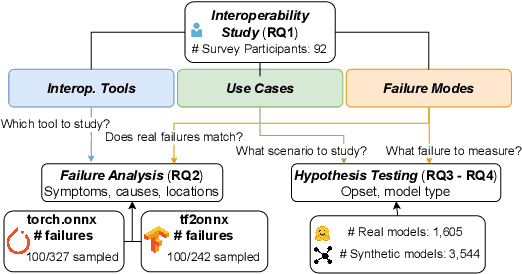
Software engineers develop, fine-tune, and deploy deep learning (DL) models. They use and re-use models in a variety of development frameworks and deploy them on a range of runtime environments. In this diverse ecosystem, engineers use DL model converters to move models from frameworks to runtime environments. However, errors in converters can compromise model quality and disrupt deployment. The failure frequency and failure modes of DL model converters are unknown. In this paper, we conduct the first failure analysis on DL model converters. Specifically, we characterize failures in model converters associated with ONNX (Open Neural Network eXchange). We analyze past failures in the ONNX converters in two major DL frameworks, PyTorch and TensorFlow. The symptoms, causes, and locations of failures (for N=200 issues), and trends over time are also reported. We also evaluate present-day failures by converting 8,797 models, both real-world and synthetically generated instances. The consistent result from both parts of the study is that DL model converters commonly fail by producing models that exhibit incorrect behavior: 33% of past failures and 8% of converted models fell into this category. Our results motivate future research on making DL software simpler to maintain, extend, and validate.
An Empirical Study of Pre-Trained Model Reuse in the Hugging Face Deep Learning Model Registry
Mar 05, 2023Deep Neural Networks (DNNs) are being adopted as components in software systems. Creating and specializing DNNs from scratch has grown increasingly difficult as state-of-the-art architectures grow more complex. Following the path of traditional software engineering, machine learning engineers have begun to reuse large-scale pre-trained models (PTMs) and fine-tune these models for downstream tasks. Prior works have studied reuse practices for traditional software packages to guide software engineers towards better package maintenance and dependency management. We lack a similar foundation of knowledge to guide behaviors in pre-trained model ecosystems. In this work, we present the first empirical investigation of PTM reuse. We interviewed 12 practitioners from the most popular PTM ecosystem, Hugging Face, to learn the practices and challenges of PTM reuse. From this data, we model the decision-making process for PTM reuse. Based on the identified practices, we describe useful attributes for model reuse, including provenance, reproducibility, and portability. Three challenges for PTM reuse are missing attributes, discrepancies between claimed and actual performance, and model risks. We substantiate these identified challenges with systematic measurements in the Hugging Face ecosystem. Our work informs future directions on optimizing deep learning ecosystems by automated measuring useful attributes and potential attacks, and envision future research on infrastructure and standardization for model registries.