 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn automated approach for improving the inference latency and energy efficiency of pretrained CNNs by removing irrelevant pixels with focused convolutions
Oct 11, 2023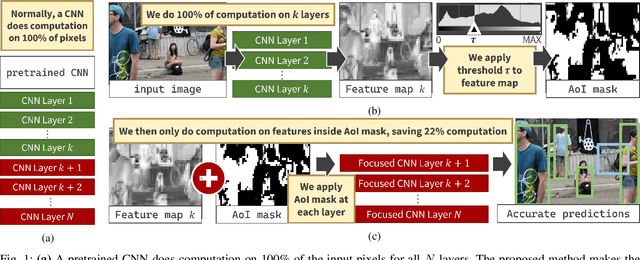

Computer vision often uses highly accurate Convolutional Neural Networks (CNNs), but these deep learning models are associated with ever-increasing energy and computation requirements. Producing more energy-efficient CNNs often requires model training which can be cost-prohibitive. We propose a novel, automated method to make a pretrained CNN more energy-efficient without re-training. Given a pretrained CNN, we insert a threshold layer that filters activations from the preceding layers to identify regions of the image that are irrelevant, i.e. can be ignored by the following layers while maintaining accuracy. Our modified focused convolution operation saves inference latency (by up to 25%) and energy costs (by up to 22%) on various popular pretrained CNNs, with little to no loss in accuracy.
Restructurable Activation Networks
Aug 17, 2022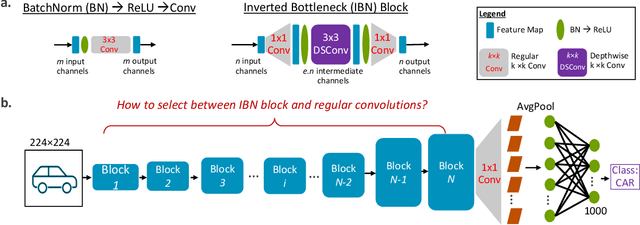
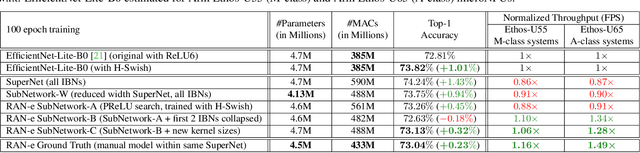
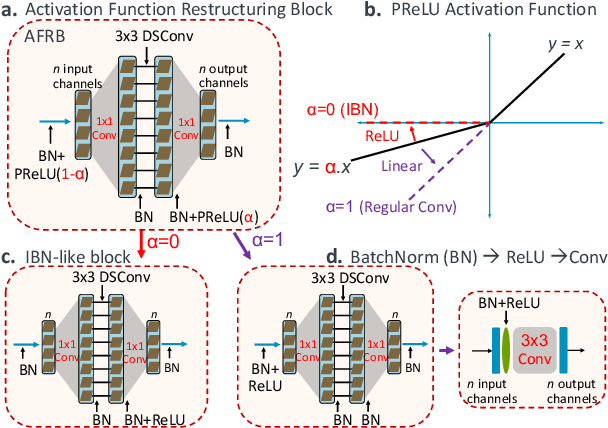
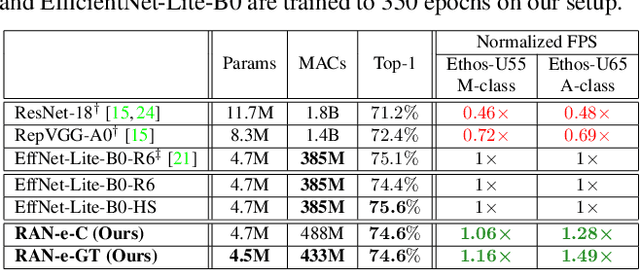
Is it possible to restructure the non-linear activation functions in a deep network to create hardware-efficient models? To address this question, we propose a new paradigm called Restructurable Activation Networks (RANs) that manipulate the amount of non-linearity in models to improve their hardware-awareness and efficiency. First, we propose RAN-explicit (RAN-e) -- a new hardware-aware search space and a semi-automatic search algorithm -- to replace inefficient blocks with hardware-aware blocks. Next, we propose a training-free model scaling method called RAN-implicit (RAN-i) where we theoretically prove the link between network topology and its expressivity in terms of number of non-linear units. We demonstrate that our networks achieve state-of-the-art results on ImageNet at different scales and for several types of hardware. For example, compared to EfficientNet-Lite-B0, RAN-e achieves a similar accuracy while improving Frames-Per-Second (FPS) by 1.5x on Arm micro-NPUs. On the other hand, RAN-i demonstrates up to 2x reduction in #MACs over ConvNexts with a similar or better accuracy. We also show that RAN-i achieves nearly 40% higher FPS than ConvNext on Arm-based datacenter CPUs. Finally, RAN-i based object detection networks achieve a similar or higher mAP and up to 33% higher FPS on datacenter CPUs compared to ConvNext based models.
Why Accuracy Is Not Enough: The Need for Consistency in Object Detection
Jul 28, 2022

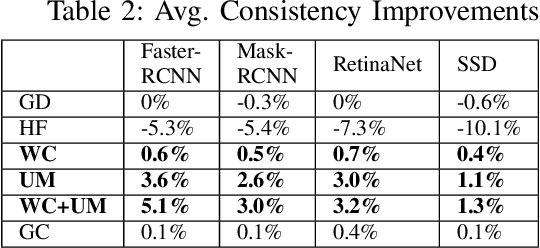
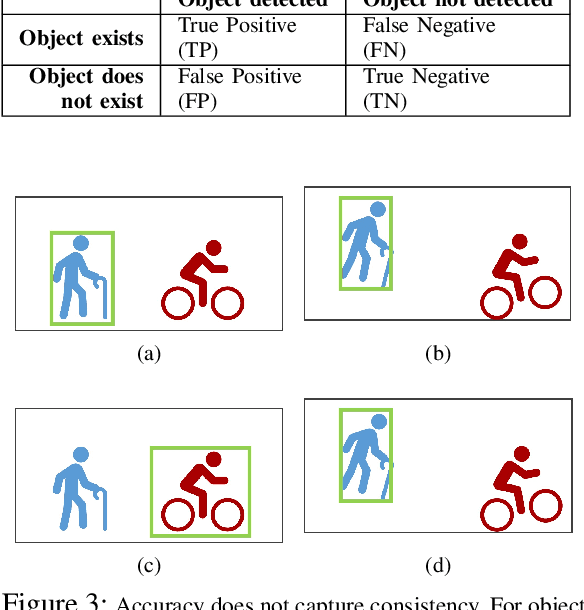
Object detectors are vital to many modern computer vision applications. However, even state-of-the-art object detectors are not perfect. On two images that look similar to human eyes, the same detector can make different predictions because of small image distortions like camera sensor noise and lighting changes. This problem is called inconsistency. Existing accuracy metrics do not properly account for inconsistency, and similar work in this area only targets improvements on artificial image distortions. Therefore, we propose a method to use non-artificial video frames to measure object detection consistency over time, across frames. Using this method, we show that the consistency of modern object detectors ranges from 83.2% to 97.1% on different video datasets from the Multiple Object Tracking Challenge. We conclude by showing that applying image distortion corrections like .WEBP Image Compression and Unsharp Masking can improve consistency by as much as 5.1%, with no loss in accuracy.
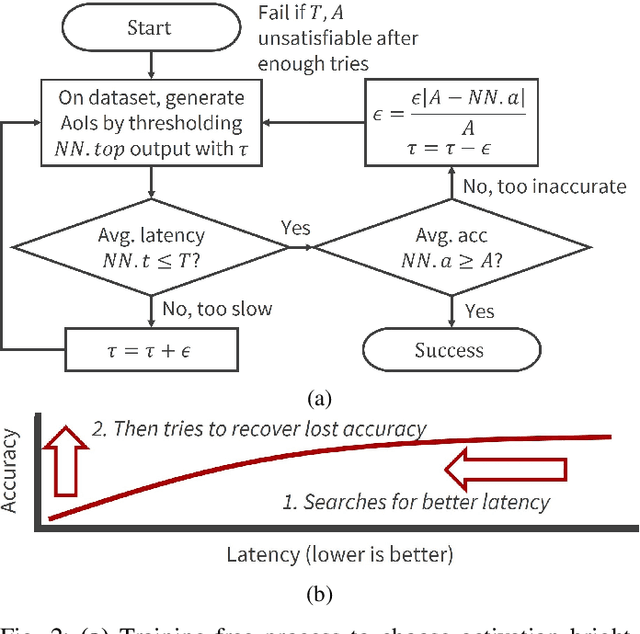
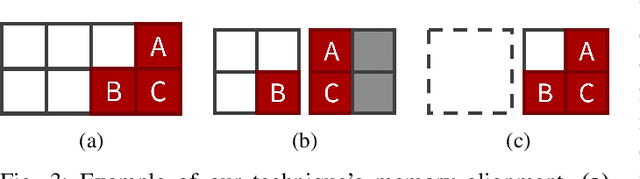
Irrelevant Pixels are Everywhere: Find and Exclude Them for More Efficient Computer Vision
Jul 21, 2022

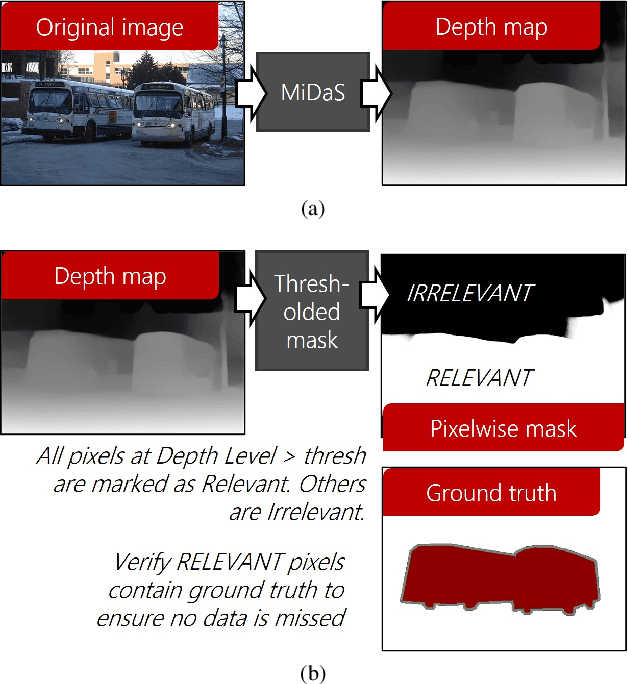
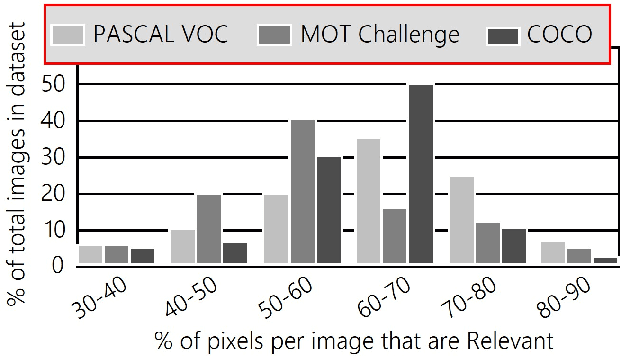
Computer vision is often performed using Convolutional Neural Networks (CNNs). CNNs are compute-intensive and challenging to deploy on power-contrained systems such as mobile and Internet-of-Things (IoT) devices. CNNs are compute-intensive because they indiscriminately compute many features on all pixels of the input image. We observe that, given a computer vision task, images often contain pixels that are irrelevant to the task. For example, if the task is looking for cars, pixels in the sky are not very useful. Therefore, we propose that a CNN be modified to only operate on relevant pixels to save computation and energy. We propose a method to study three popular computer vision datasets, finding that 48% of pixels are irrelevant. We also propose the focused convolution to modify a CNN's convolutional layers to reject the pixels that are marked irrelevant. On an embedded device, we observe no loss in accuracy, while inference latency, energy consumption, and multiply-add count are all reduced by about 45%.
Efficient Computer Vision on Edge Devices with Pipeline-Parallel Hierarchical Neural Networks
Sep 27, 2021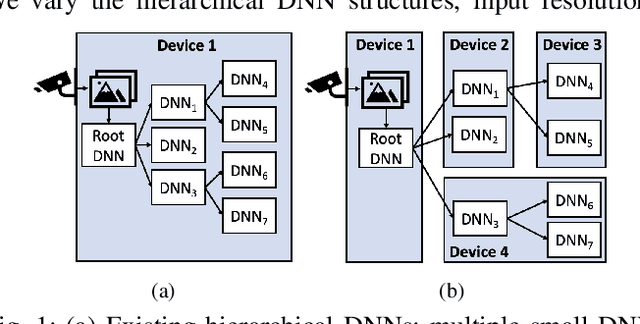
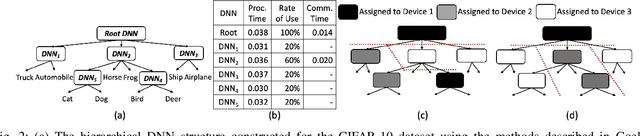
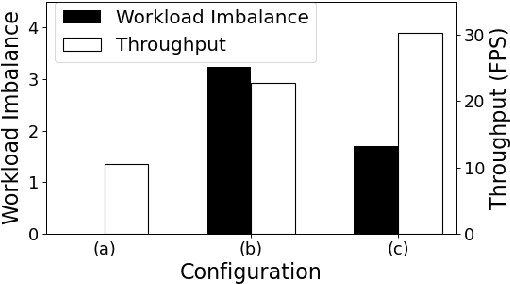
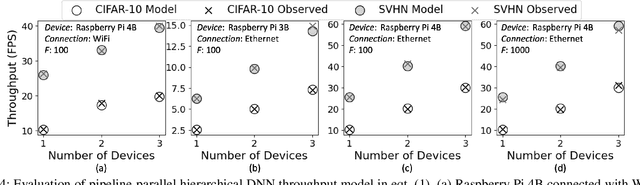
Computer vision on low-power edge devices enables applications including search-and-rescue and security. State-of-the-art computer vision algorithms, such as Deep Neural Networks (DNNs), are too large for inference on low-power edge devices. To improve efficiency, some existing approaches parallelize DNN inference across multiple edge devices. However, these techniques introduce significant communication and synchronization overheads or are unable to balance workloads across devices. This paper demonstrates that the hierarchical DNN architecture is well suited for parallel processing on multiple edge devices. We design a novel method that creates a parallel inference pipeline for computer vision problems that use hierarchical DNNs. The method balances loads across the collaborating devices and reduces communication costs to facilitate the processing of multiple video frames simultaneously with higher throughput. Our experiments consider a representative computer vision problem where image recognition is performed on each video frame, running on multiple Raspberry Pi 4Bs. With four collaborating low-power edge devices, our approach achieves 3.21X higher throughput, 68% less energy consumption per device per frame, and 58% decrease in memory when compared with existing single-device hierarchical DNNs.
Low-Power Multi-Camera Object Re-Identification using Hierarchical Neural Networks
Jun 19, 2021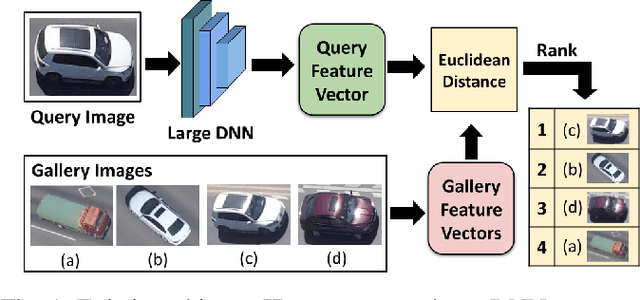
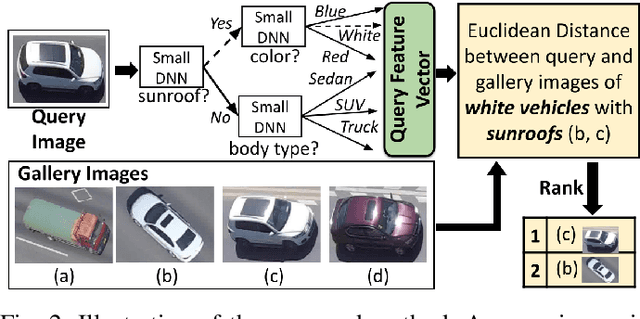

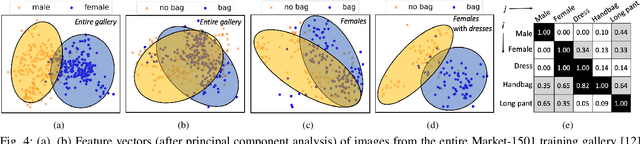
Low-power computer vision on embedded devices has many applications. This paper describes a low-power technique for the object re-identification (reID) problem: matching a query image against a gallery of previously seen images. State-of-the-art techniques rely on large, computationally-intensive Deep Neural Networks (DNNs). We propose a novel hierarchical DNN architecture that uses attribute labels in the training dataset to perform efficient object reID. At each node in the hierarchy, a small DNN identifies a different attribute of the query image. The small DNN at each leaf node is specialized to re-identify a subset of the gallery: only the images with the attributes identified along the path from the root to a leaf. Thus, a query image is re-identified accurately after processing with a few small DNNs. We compare our method with state-of-the-art object reID techniques. With a 4% loss in accuracy, our approach realizes significant resource savings: 74% less memory, 72% fewer operations, and 67% lower query latency, yielding 65% less energy consumption.
Analyzing Worldwide Social Distancing through Large-Scale Computer Vision
Aug 27, 2020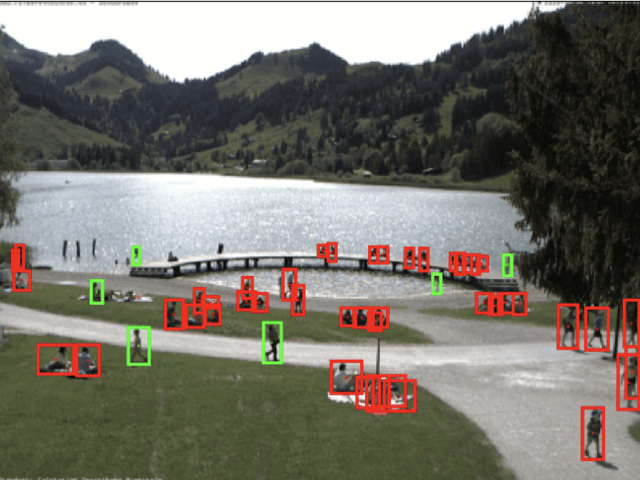
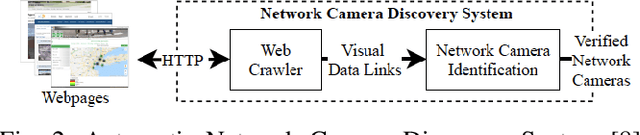
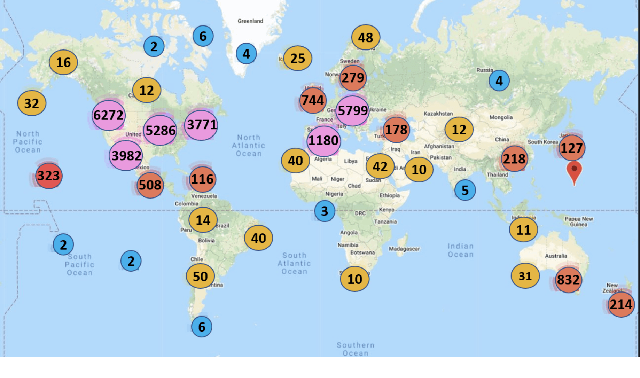
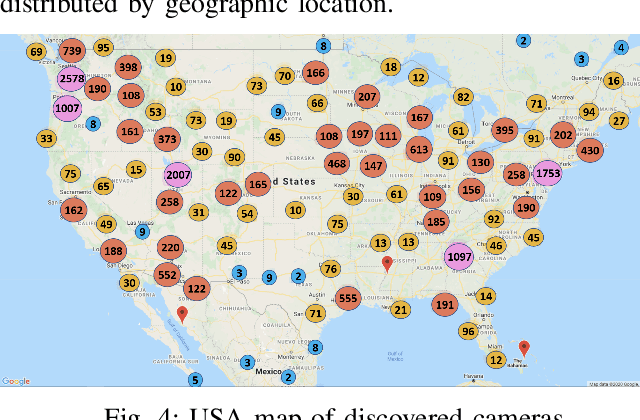
In order to contain the COVID-19 pandemic, countries around the world have introduced social distancing guidelines as public health interventions to reduce the spread of the disease. However, monitoring the efficacy of these guidelines at a large scale (nationwide or worldwide) is difficult. To make matters worse, traditional observational methods such as in-person reporting is dangerous because observers may risk infection. A better solution is to observe activities through network cameras; this approach is scalable and observers can stay in safe locations. This research team has created methods that can discover thousands of network cameras worldwide, retrieve data from the cameras, analyze the data, and report the sizes of crowds as different countries issued and lifted restrictions (also called ''lockdown''). We discover 11,140 network cameras that provide real-time data and we present the results across 15 countries. We collect data from these cameras beginning April 2020 at approximately 0.5TB per week. After analyzing 10,424,459 images from still image cameras and frames extracted periodically from video, the data reveals that the residents in some countries exhibited more activity (judged by numbers of people and vehicles) after the restrictions were lifted. In other countries, the amounts of activities showed no obvious changes during the restrictions and after the restrictions were lifted. The data further reveals whether people stay ''social distancing'', at least 6 feet apart. This study discerns whether social distancing is being followed in several types of locations and geographical locations worldwide and serve as an early indicator whether another wave of infections is likely to occur soon.
Low-Power Object Counting with Hierarchical Neural Networks
Jul 02, 2020

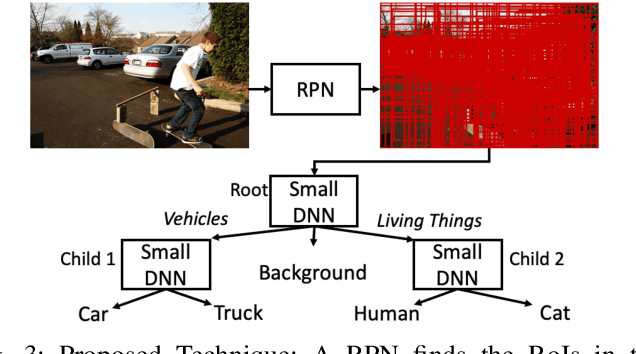

Deep Neural Networks (DNNs) can achieve state-of-the-art accuracy in many computer vision tasks, such as object counting. Object counting takes two inputs: an image and an object query and reports the number of occurrences of the queried object. To achieve high accuracy on such tasks, DNNs require billions of operations, making them difficult to deploy on resource-constrained, low-power devices. Prior work shows that a significant number of DNN operations are redundant and can be eliminated without affecting the accuracy. To reduce these redundancies, we propose a hierarchical DNN architecture for object counting. This architecture uses a Region Proposal Network (RPN) to propose regions-of-interest (RoIs) that may contain the queried objects. A hierarchical classifier then efficiently finds the RoIs that actually contain the queried objects. The hierarchy contains groups of visually similar object categories. Small DNNs are used at each node of the hierarchy to classify between these groups. The RoIs are incrementally processed by the hierarchical classifier. If the object in an RoI is in the same group as the queried object, then the next DNN in the hierarchy processes the RoI further; otherwise, the RoI is discarded. By using a few small DNNs to process each image, this method reduces the memory requirement, inference time, energy consumption, and number of operations with negligible accuracy loss when compared with the existing object counters.
A Survey of Methods for Low-Power Deep Learning and Computer Vision
Mar 24, 2020
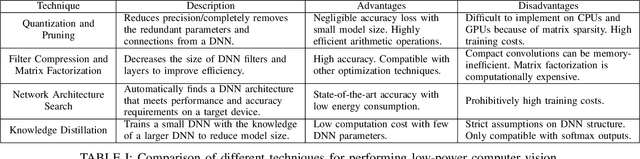
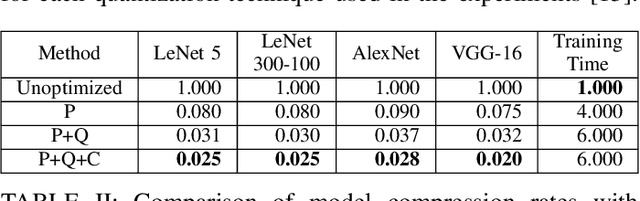

Deep neural networks (DNNs) are successful in many computer vision tasks. However, the most accurate DNNs require millions of parameters and operations, making them energy, computation and memory intensive. This impedes the deployment of large DNNs in low-power devices with limited compute resources. Recent research improves DNN models by reducing the memory requirement, energy consumption, and number of operations without significantly decreasing the accuracy. This paper surveys the progress of low-power deep learning and computer vision, specifically in regards to inference, and discusses the methods for compacting and accelerating DNN models. The techniques can be divided into four major categories: (1) parameter quantization and pruning, (2) compressed convolutional filters and matrix factorization, (3) network architecture search, and (4) knowledge distillation. We analyze the accuracy, advantages, disadvantages, and potential solutions to the problems with the techniques in each category. We also discuss new evaluation metrics as a guideline for future research.
Large-Scale Object Detection of Images from Network Cameras in Variable Ambient Lighting Conditions
Dec 31, 2018



Computer vision relies on labeled datasets for training and evaluation in detecting and recognizing objects. The popular computer vision program, YOLO ("You Only Look Once"), has been shown to accurately detect objects in many major image datasets. However, the images found in those datasets, are independent of one another and cannot be used to test YOLO's consistency at detecting the same object as its environment (e.g. ambient lighting) changes. This paper describes a novel effort to evaluate YOLO's consistency for large-scale applications. It does so by working (a) at large scale and (b) by using consecutive images from a curated network of public video cameras deployed in a variety of real-world situations, including traffic intersections, national parks, shopping malls, university campuses, etc. We specifically examine YOLO's ability to detect objects in different scenarios (e.g., daytime vs. night), leveraging the cameras' ability to rapidly retrieve many successive images for evaluating detection consistency. Using our camera network and advanced computing resources (supercomputers), we analyzed more than 5 million images captured by 140 network cameras in 24 hours. Compared with labels marked by humans (considered as "ground truth"), YOLO struggles to consistently detect the same humans and cars as their positions change from one frame to the next; it also struggles to detect objects at night time. Our findings suggest that state-of-the art vision solutions should be trained by data from network camera with contextual information before they can be deployed in applications that demand high consistency on object detection.