 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Metric Magnitude of Point Sets
Sep 06, 2024


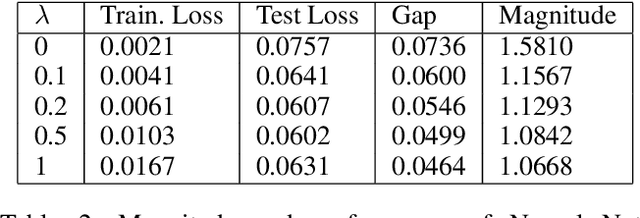
Metric magnitude is a measure of the "size" of point clouds with many desirable geometric properties. It has been adapted to various mathematical contexts and recent work suggests that it can enhance machine learning and optimization algorithms. But its usability is limited due to the computational cost when the dataset is large or when the computation must be carried out repeatedly (e.g. in model training). In this paper, we study the magnitude computation problem, and show efficient ways of approximating it. We show that it can be cast as a convex optimization problem, but not as a submodular optimization. The paper describes two new algorithms - an iterative approximation algorithm that converges fast and is accurate, and a subset selection method that makes the computation even faster. It has been previously proposed that magnitude of model sequences generated during stochastic gradient descent is correlated to generalization gap. Extension of this result using our more scalable algorithms shows that longer sequences in fact bear higher correlations. We also describe new applications of magnitude in machine learning - as an effective regularizer for neural network training, and as a novel clustering criterion.
Swift Trust in Mobile Ad Hoc Human-Robot Teams
Aug 18, 2024

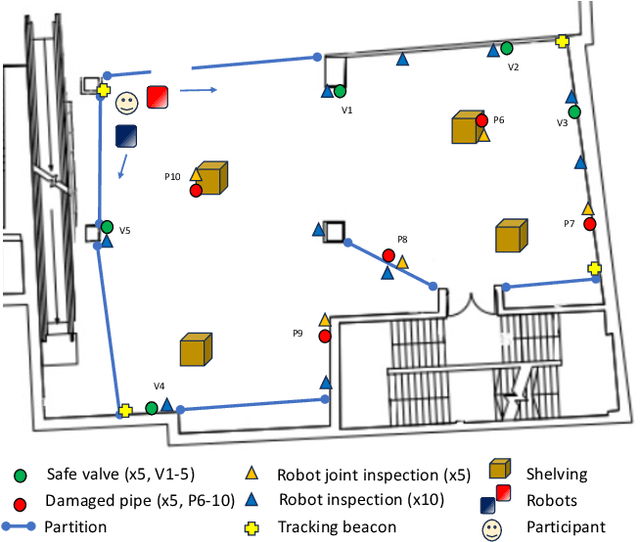

Integrating robots into teams of humans is anticipated to bring significant capability improvements for tasks such as searching potentially hazardous buildings. Trust between humans and robots is recognized as a key enabler for human-robot teaming (HRT) activity: if trust during a mission falls below sufficient levels for cooperative tasks to be completed, it could critically affect success. Changes in trust could be particularly problematic in teams that have formed on an ad hoc basis (as might be expected in emergency situations) where team members may not have previously worked together. In such ad hoc teams, a foundational level of 'swift trust' may be fragile and challenging to sustain in the face of inevitable setbacks. We present results of an experiment focused on understanding trust building, violation and repair processes in ad hoc teams (one human and two robots). Trust violation occurred through robots becoming unresponsive, with limited communication and feedback. We perform exploratory analysis of a variety of data, including communications and performance logs, trust surveys and post-experiment interviews, toward understanding how autonomous systems can be designed into interdependent ad hoc human-robot teams where swift trust can be sustained.
Restructurable Activation Networks
Aug 17, 2022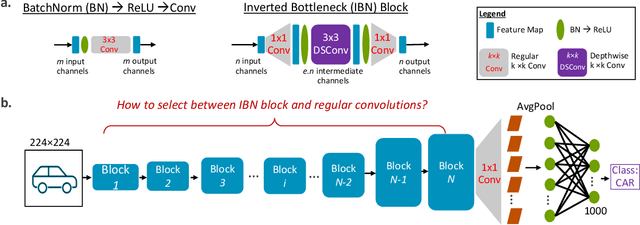
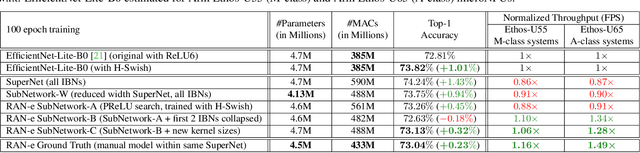
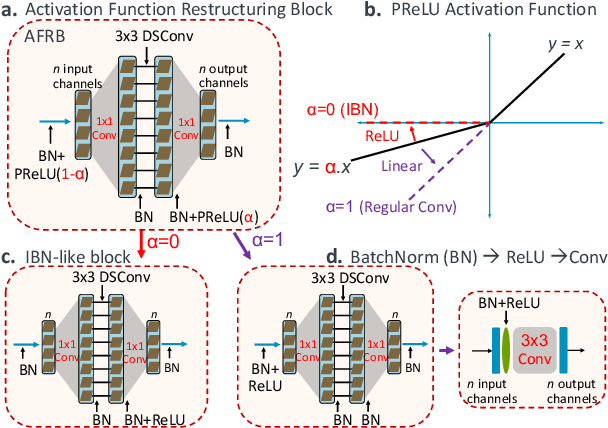
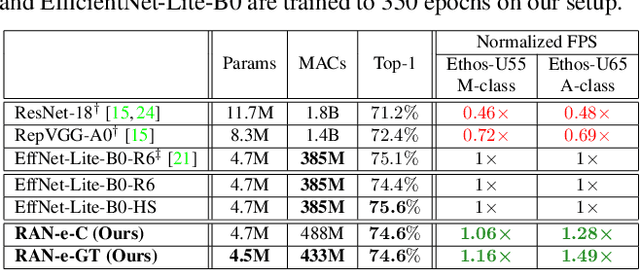
Is it possible to restructure the non-linear activation functions in a deep network to create hardware-efficient models? To address this question, we propose a new paradigm called Restructurable Activation Networks (RANs) that manipulate the amount of non-linearity in models to improve their hardware-awareness and efficiency. First, we propose RAN-explicit (RAN-e) -- a new hardware-aware search space and a semi-automatic search algorithm -- to replace inefficient blocks with hardware-aware blocks. Next, we propose a training-free model scaling method called RAN-implicit (RAN-i) where we theoretically prove the link between network topology and its expressivity in terms of number of non-linear units. We demonstrate that our networks achieve state-of-the-art results on ImageNet at different scales and for several types of hardware. For example, compared to EfficientNet-Lite-B0, RAN-e achieves a similar accuracy while improving Frames-Per-Second (FPS) by 1.5x on Arm micro-NPUs. On the other hand, RAN-i demonstrates up to 2x reduction in #MACs over ConvNexts with a similar or better accuracy. We also show that RAN-i achieves nearly 40% higher FPS than ConvNext on Arm-based datacenter CPUs. Finally, RAN-i based object detection networks achieve a similar or higher mAP and up to 33% higher FPS on datacenter CPUs compared to ConvNext based models.
Transmit Precoder Design Approaches for Dual-Function Radar-Communication Systems
Mar 17, 2022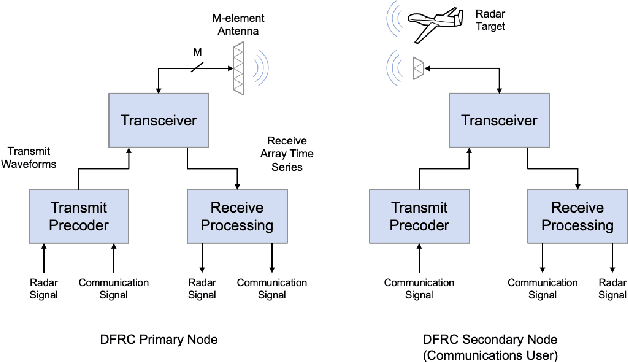
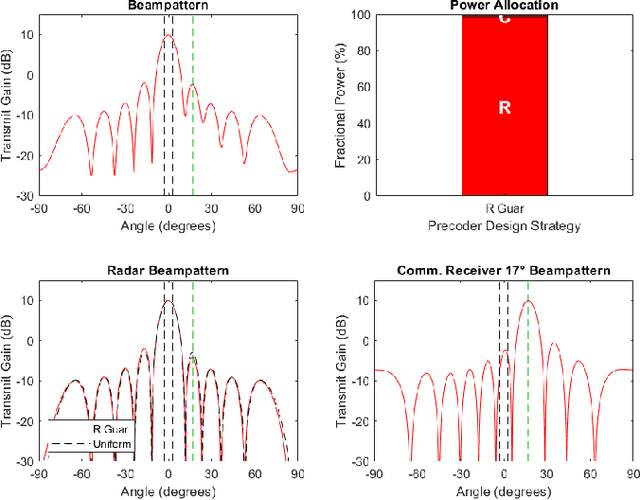
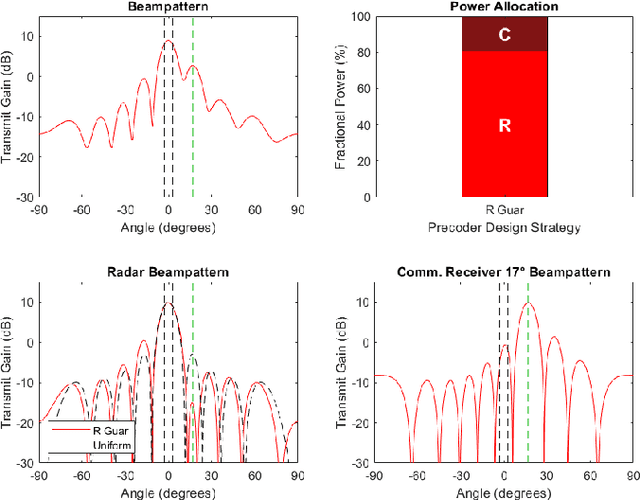
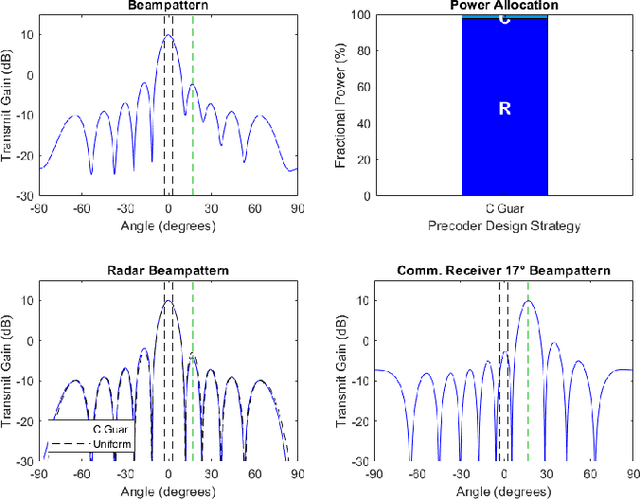
As radio-frequency (RF) antenna, component and processing capabilities increase, the ability to perform multiple RF system functions from a common aperture is being realized. Conducting both radar and communications from the same system is potentially useful in vehicular, health monitoring, and surveillance settings. This paper considers multiple-input-multiple-output (MIMO) dual-function radar-communication (DFRC) systems in which the radar and communication modes use distinct baseband waveforms. A transmit precoder provides spatial multiplexing and power allocation among the radar and communication modes. Multiple precoder design approaches are introduced for a radar detection mode in which a total search volume is divided into dwells to be searched sequentially. The approaches are designed to enforce a reliance on radar waveforms for sensing purposes, yielding improved approximation of desired ambiguity functions over prior methods found in the literature. The methods are also shown via simulation to enable design flexibility, allowing for prioritization of either subsystem and specification of a desired level of radar or communication performance.
Super-Efficient Super Resolution for Fast Adversarial Defense at the Edge
Dec 29, 2021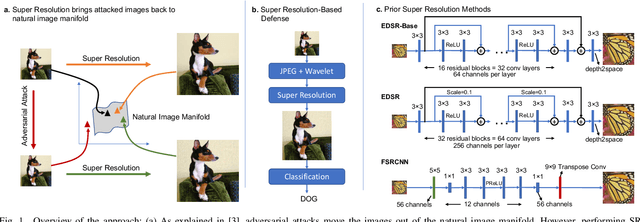
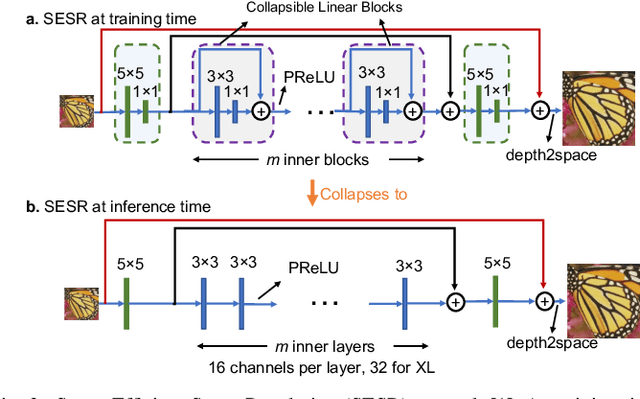
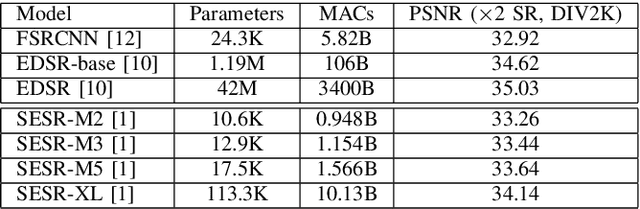
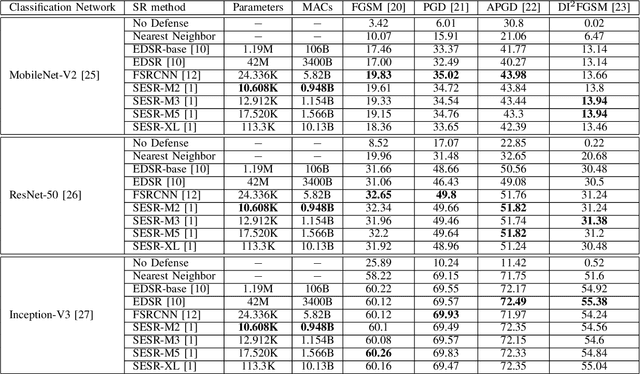
Autonomous systems are highly vulnerable to a variety of adversarial attacks on Deep Neural Networks (DNNs). Training-free model-agnostic defenses have recently gained popularity due to their speed, ease of deployment, and ability to work across many DNNs. To this end, a new technique has emerged for mitigating attacks on image classification DNNs, namely, preprocessing adversarial images using super resolution -- upscaling low-quality inputs into high-resolution images. This defense requires running both image classifiers and super resolution models on constrained autonomous systems. However, super resolution incurs a heavy computational cost. Therefore, in this paper, we investigate the following question: Does the robustness of image classifiers suffer if we use tiny super resolution models? To answer this, we first review a recent work called Super-Efficient Super Resolution (SESR) that achieves similar or better image quality than prior art while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. We demonstrate that despite being orders of magnitude smaller than existing models, SESR achieves the same level of robustness as significantly larger networks. Finally, we estimate end-to-end performance of super resolution-based defenses on a commercial Arm Ethos-U55 micro-NPU. Our findings show that SESR achieves nearly 3x higher FPS than a baseline while achieving similar robustness.
Semantic sensor fusion: from camera to sparse lidar information
Mar 04, 2020


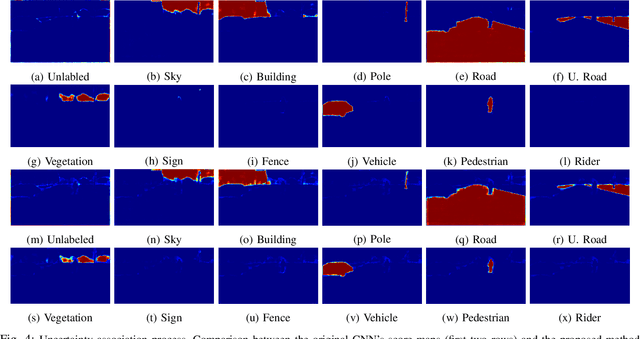
To navigate through urban roads, an automated vehicle must be able to perceive and recognize objects in a three-dimensional environment. A high-level contextual understanding of the surroundings is necessary to plan and execute accurate driving maneuvers. This paper presents an approach to fuse different sensory information, Light Detection and Ranging (lidar) scans and camera images. The output of a convolutional neural network (CNN) is used as classifier to obtain the labels of the environment. The transference of semantic information between the labelled image and the lidar point cloud is performed in four steps: initially, we use heuristic methods to associate probabilities to all the semantic classes contained in the labelled images. Then, the lidar points are corrected to compensate for the vehicle's motion given the difference between the timestamps of each lidar scan and camera image. In a third step, we calculate the pixel coordinate for the corresponding camera image. In the last step we perform the transfer of semantic information from the heuristic probability images to the lidar frame, while removing the lidar information that is not visible to the camera. We tested our approach in the Usyd Dataset \cite{usyd_dataset}, obtaining qualitative and quantitative results that demonstrate the validity of our probabilistic sensory fusion approach.
Comparison of object detection methods for crop damage assessment using deep learning
Dec 31, 2019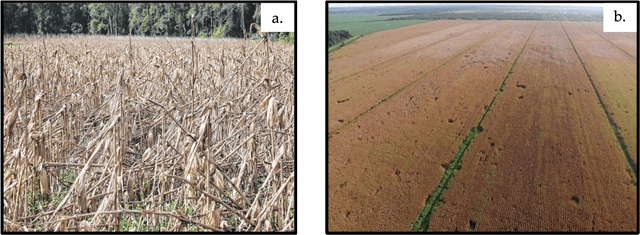
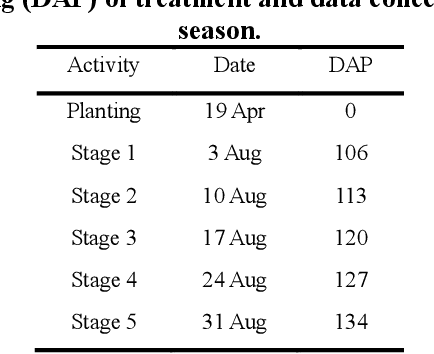


Severe weather events can cause large financial losses to farmers. Detailed information on the location and severity of damage will assist farmers, insurance companies, and disaster response agencies in making wise post-damage decisions. The goal of this study was a proof-of-concept to detect damaged crop areas from aerial imagery using computer vision and deep learning techniques. A specific objective was to compare existing object detection algorithms to determine which was best suited for crop damage detection. Two modes of crop damage common in maize (corn) production were simulated: stalk lodging at the lowest ear and stalk lodging at ground level. Simulated damage was used to create a training and analysis data set. An unmanned aerial system (UAS) equipped with a RGB camera was used for image acquisition. Three popular object detectors (Faster R-CNN, YOLOv2, and RetinaNet) were assessed for their ability to detect damaged regions in a field. Average precision was used to compare object detectors. YOLOv2 and RetinaNet were able to detect crop damage across multiple late-season growth stages. Faster R-CNN was not successful as the other two advanced detectors. Detecting crop damage at later growth stages was more difficult for all tested object detectors. Weed pressure in simulated damage plots and increased target density added additional complexity.
Towards Provably Not-at-Fault Control of Autonomous Robots in Arbitrary Dynamic Environments
Feb 07, 2019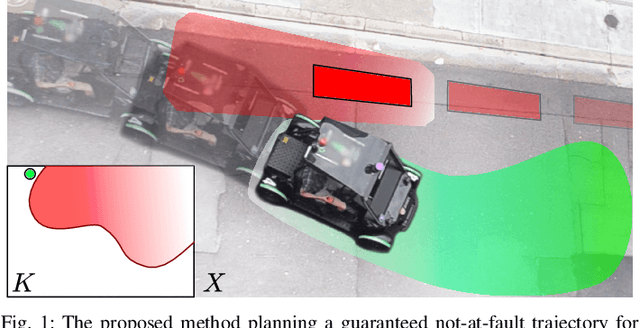
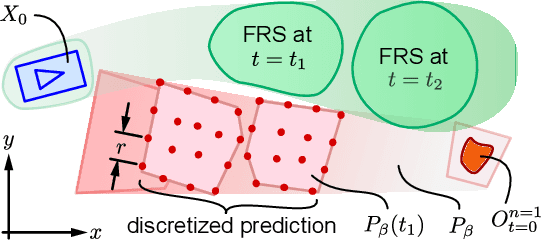

As autonomous robots increasingly become part of daily life, they will often encounter dynamic environments while only having limited information about their surroundings. Unfortunately, due to the possible presence of malicious dynamic actors, it is infeasible to develop an algorithm that can guarantee collision-free operation. Instead, one can attempt to design a control technique that guarantees the robot is not-at-fault in any collision. In the literature, making such guarantees in real time has been restricted to static environments or specific dynamic models. To ensure not-at-fault behavior, a robot must first correctly sense and predict the world around it within some sufficiently large sensor horizon (the prediction problem), then correctly control relative to the predictions (the control problem). This paper addresses the control problem by proposing Reachability-based Trajectory Design for Dynamic environments (RTD-D), which guarantees that a robot with an arbitrary nonlinear dynamic model correctly responds to predictions in arbitrary dynamic environments. RTD-D first computes a Forward Reachable Set (FRS) offline of the robot tracking parameterized desired trajectories that include fail-safe maneuvers. Then, for online receding-horizon planning, the method provides a way to discretize predictions of an arbitrary dynamic environment to enable real-time collision checking. The FRS is used to map these discretized predictions to trajectories that the robot can track while provably not-at-fault. One such trajectory is chosen at each iteration, or the robot executes the fail-safe maneuver from its previous trajectory which is guaranteed to be not at fault. RTD-D is shown to produce not-at-fault behavior over thousands of simulations and several real-world hardware demonstrations on two robots: a Segway, and a small electric vehicle.
Identifying robust landmarks in feature-based maps
Sep 26, 2018



To operate in an urban environment, an automated vehicle must be capable of accurately estimating its position within a global map reference frame. This is necessary for optimal path planning and safe navigation. To accomplish this over an extended period of time, the global map requires long-term maintenance. This includes the addition of newly observable features and the removal of transient features belonging to dynamic objects. The latter is especially important for the long-term use of the map as matching against a map with features that no longer exist can result in incorrect data associations, and consequently erroneous localisation. This paper addresses the problem of removing features from the map that correspond to objects that are no longer observable/present in the environment. This is achieved by assigning a single score which depends on the geometric distribution and characteristics when the features are re-detected (or not) on different occasions. Our approach not only eliminates ephemeral features, but also can be used as a reduction algorithm for highly dense maps. We tested our approach using half a year of weekly drives over the same 500-metre section of road in an urban environment. The results presented demonstrate the validity of the long-term approach to map maintenance.