 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic sensor fusion: from camera to sparse lidar information
Paper and Code
Mar 04, 2020


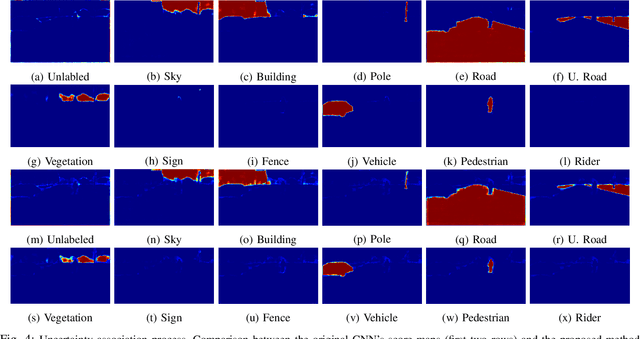
To navigate through urban roads, an automated vehicle must be able to perceive and recognize objects in a three-dimensional environment. A high-level contextual understanding of the surroundings is necessary to plan and execute accurate driving maneuvers. This paper presents an approach to fuse different sensory information, Light Detection and Ranging (lidar) scans and camera images. The output of a convolutional neural network (CNN) is used as classifier to obtain the labels of the environment. The transference of semantic information between the labelled image and the lidar point cloud is performed in four steps: initially, we use heuristic methods to associate probabilities to all the semantic classes contained in the labelled images. Then, the lidar points are corrected to compensate for the vehicle's motion given the difference between the timestamps of each lidar scan and camera image. In a third step, we calculate the pixel coordinate for the corresponding camera image. In the last step we perform the transfer of semantic information from the heuristic probability images to the lidar frame, while removing the lidar information that is not visible to the camera. We tested our approach in the Usyd Dataset \cite{usyd_dataset}, obtaining qualitative and quantitative results that demonstrate the validity of our probabilistic sensory fusion approach.