 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHazard-Aware Traffic Scene Graph Generation
Mar 03, 2026Maintaining situational awareness in complex driving scenarios is challenging. It requires continuously prioritizing attention among extensive scene entities and understanding how prominent hazards might affect the ego vehicle. While existing studies excel at detecting specific semantic categories and visually salient regions, they lack the ability to assess safety-relevance. Meanwhile, the generic spatial predicates either for foreground objects only or for all scene entities modeled by existing scene graphs are inadequate for driving scenarios. To bridge this gap, we introduce a novel task, Traffic Scene Graph Generation, which captures traffic-specific relations between prominent hazards and the ego vehicle. We propose a novel framework that explicitly uses traffic accident data and depth cues to supplement visual features and semantic information for reasoning. The output traffic scene graphs provide intuitive guidelines that stress prominent hazards by color-coding their severity and notating their effect mechanism and relative location to the ego vehicle. We create relational annotations on Cityscapes dataset and evaluate our model on 10 tasks from 5 perspectives. The results in comparative experiments and ablation studies demonstrate our capacity in ego-centric reasoning for hazard-aware traffic scene understanding.
TFusionOcc: Student's t-Distribution Based Object-Centric Multi-Sensor Fusion Framework for 3D Occupancy Prediction
Feb 06, 20263D semantic occupancy prediction enables autonomous vehicles (AVs) to perceive fine-grained geometric and semantic structure of their surroundings from onboard sensors, which is essential for safe decision-making and navigation. Recent models for 3D semantic occupancy prediction have successfully addressed the challenge of describing real-world objects with varied shapes and classes. However, the intermediate representations used by existing methods for 3D semantic occupancy prediction rely heavily on 3D voxel volumes or a set of 3D Gaussians, hindering the model's ability to efficiently and effectively capture fine-grained geometric details in the 3D driving environment. This paper introduces TFusionOcc, a novel object-centric multi-sensor fusion framework for predicting 3D semantic occupancy. By leveraging multi-stage multi-sensor fusion, Student's t-distribution, and the T-Mixture model (TMM), together with more geometrically flexible primitives, such as the deformable superquadric (superquadric with inverse warp), the proposed method achieved state-of-the-art (SOTA) performance on the nuScenes benchmark. In addition, extensive experiments were conducted on the nuScenes-C dataset to demonstrate the robustness of the proposed method in different camera and lidar corruption scenarios. The code will be available at: https://github.com/DanielMing123/TFusionOcc
InterKey: Cross-modal Intersection Keypoints for Global Localization on OpenStreetMap
Sep 17, 2025Reliable global localization is critical for autonomous vehicles, especially in environments where GNSS is degraded or unavailable, such as urban canyons and tunnels. Although high-definition (HD) maps provide accurate priors, the cost of data collection, map construction, and maintenance limits scalability. OpenStreetMap (OSM) offers a free and globally available alternative, but its coarse abstraction poses challenges for matching with sensor data. We propose InterKey, a cross-modal framework that leverages road intersections as distinctive landmarks for global localization. Our method constructs compact binary descriptors by jointly encoding road and building imprints from point clouds and OSM. To bridge modality gaps, we introduce discrepancy mitigation, orientation determination, and area-equalized sampling strategies, enabling robust cross-modal matching. Experiments on the KITTI dataset demonstrate that InterKey achieves state-of-the-art accuracy, outperforming recent baselines by a large margin. The framework generalizes to sensors that can produce dense structural point clouds, offering a scalable and cost-effective solution for robust vehicle localization.
What Demands Attention in Urban Street Scenes? From Scene Understanding towards Road Safety: A Survey of Vision-driven Datasets and Studies
Jul 09, 2025



Advances in vision-based sensors and computer vision algorithms have significantly improved the analysis and understanding of traffic scenarios. To facilitate the use of these improvements for road safety, this survey systematically categorizes the critical elements that demand attention in traffic scenarios and comprehensively analyzes available vision-driven tasks and datasets. Compared to existing surveys that focus on isolated domains, our taxonomy categorizes attention-worthy traffic entities into two main groups that are anomalies and normal but critical entities, integrating ten categories and twenty subclasses. It establishes connections between inherently related fields and provides a unified analytical framework. Our survey highlights the analysis of 35 vision-driven tasks and comprehensive examinations and visualizations of 73 available datasets based on the proposed taxonomy. The cross-domain investigation covers the pros and cons of each benchmark with the aim of providing information on standards unification and resource optimization. Our article concludes with a systematic discussion of the existing weaknesses, underlining the potential effects and promising solutions from various perspectives. The integrated taxonomy, comprehensive analysis, and recapitulatory tables serve as valuable contributions to this rapidly evolving field by providing researchers with a holistic overview, guiding strategic resource selection, and highlighting critical research gaps.
OccCylindrical: Multi-Modal Fusion with Cylindrical Representation for 3D Semantic Occupancy Prediction
May 06, 2025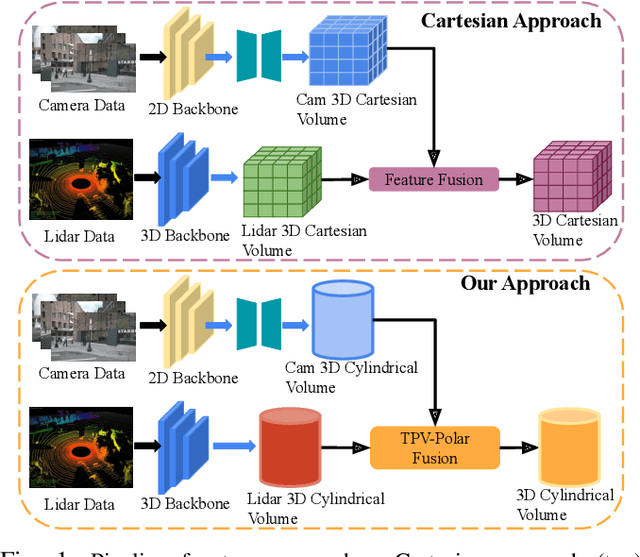
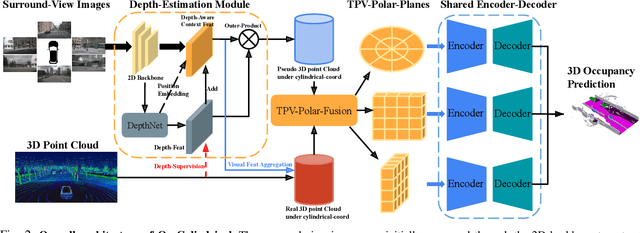
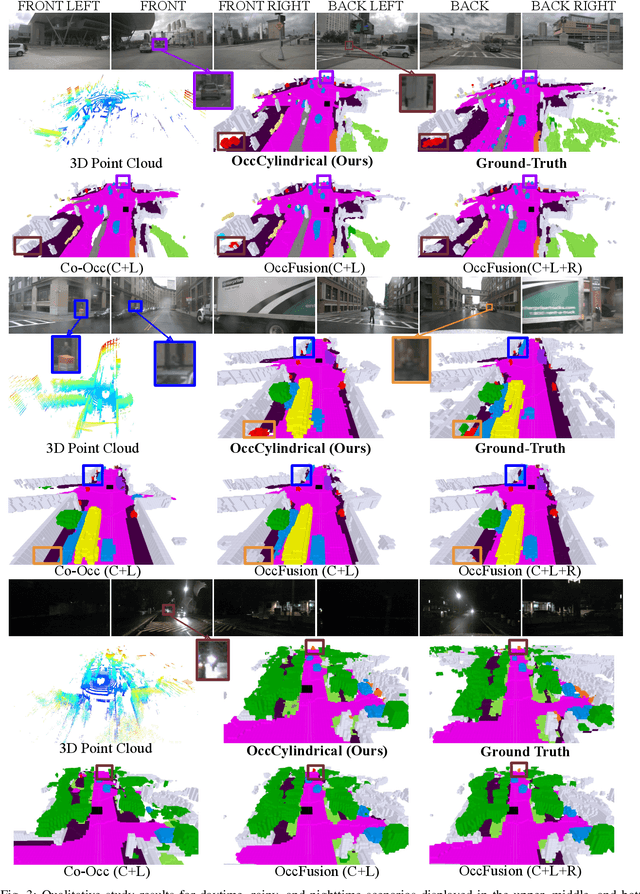
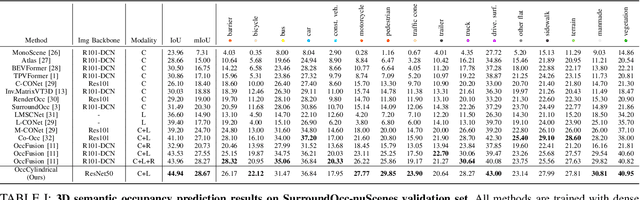
The safe operation of autonomous vehicles (AVs) is highly dependent on their understanding of the surroundings. For this, the task of 3D semantic occupancy prediction divides the space around the sensors into voxels, and labels each voxel with both occupancy and semantic information. Recent perception models have used multisensor fusion to perform this task. However, existing multisensor fusion-based approaches focus mainly on using sensor information in the Cartesian coordinate system. This ignores the distribution of the sensor readings, leading to a loss of fine-grained details and performance degradation. In this paper, we propose OccCylindrical that merges and refines the different modality features under cylindrical coordinates. Our method preserves more fine-grained geometry detail that leads to better performance. Extensive experiments conducted on the nuScenes dataset, including challenging rainy and nighttime scenarios, confirm our approach's effectiveness and state-of-the-art performance. The code will be available at: https://github.com/DanielMing123/OccCylindrical
InterLoc: LiDAR-based Intersection Localization using Road Segmentation with Automated Evaluation Method
May 01, 2025Intersections are geometric and functional key points in every road network. They offer strong landmarks to correct GNSS dropouts and anchor new sensor data in up-to-date maps. Despite that importance, intersection detectors either ignore the rich semantic information already computed onboard or depend on scarce, hand-labeled intersection datasets. To close that gap, this paper presents a LiDAR-based method for intersection detection that (i) fuses semantic road segmentation with vehicle localization to detect intersection candidates in a bird's eye view (BEV) representation and (ii) refines those candidates by analyzing branch topology with a least squares formulation. To evaluate our method, we introduce an automated benchmarking pipeline that pairs detections with OpenStreetMap (OSM) intersection nodes using precise GNSS/INS ground-truth poses. Tested on eight SemanticKITTI sequences, the approach achieves a mean localization error of 1.9 m, 89% precision, and 77% recall at a 5 m tolerance, outperforming the latest learning-based baseline. Moreover, the method is robust to segmentation errors higher than those of the benchmark model, demonstrating its applicability in the real world.
M2S-RoAD: Multi-Modal Semantic Segmentation for Road Damage Using Camera and LiDAR Data
Apr 14, 2025Road damage can create safety and comfort challenges for both human drivers and autonomous vehicles (AVs). This damage is particularly prevalent in rural areas due to less frequent surveying and maintenance of roads. Automated detection of pavement deterioration can be used as an input to AVs and driver assistance systems to improve road safety. Current research in this field has predominantly focused on urban environments driven largely by public datasets, while rural areas have received significantly less attention. This paper introduces M2S-RoAD, a dataset for the semantic segmentation of different classes of road damage. M2S-RoAD was collected in various towns across New South Wales, Australia, and labelled for semantic segmentation to identify nine distinct types of road damage. This dataset will be released upon the acceptance of the paper.
SydneyScapes: Image Segmentation for Australian Environments
Apr 10, 2025



Autonomous Vehicles (AVs) are being partially deployed and tested across various global locations, including China, the USA, Germany, France, Japan, Korea, and the UK, but with limited demonstrations in Australia. The integration of machine learning (ML) into AV perception systems highlights the need for locally labelled datasets to develop and test algorithms in specific environments. To address this, we introduce SydneyScapes - a dataset tailored for computer vision tasks of image semantic, instance, and panoptic segmentation. This dataset, collected from Sydney and surrounding cities in New South Wales (NSW), Australia, consists of 756 images with high-quality pixel-level annotations. It is designed to assist AV industry and researchers by providing annotated data and tools for algorithm development, testing, and deployment in the Australian context. Additionally, we offer benchmarking results using state-of-the-art algorithms to establish reference points for future research and development. The dataset is publicly available at https://hdl.handle.net/2123/33051.
Inverse++: Vision-Centric 3D Semantic Occupancy Prediction Assisted with 3D Object Detection
Apr 07, 20253D semantic occupancy prediction aims to forecast detailed geometric and semantic information of the surrounding environment for autonomous vehicles (AVs) using onboard surround-view cameras. Existing methods primarily focus on intricate inner structure module designs to improve model performance, such as efficient feature sampling and aggregation processes or intermediate feature representation formats. In this paper, we explore multitask learning by introducing an additional 3D supervision signal by incorporating an additional 3D object detection auxiliary branch. This extra 3D supervision signal enhances the model's overall performance by strengthening the capability of the intermediate features to capture small dynamic objects in the scene, and these small dynamic objects often include vulnerable road users, i.e. bicycles, motorcycles, and pedestrians, whose detection is crucial for ensuring driving safety in autonomous vehicles. Extensive experiments conducted on the nuScenes datasets, including challenging rainy and nighttime scenarios, showcase that our approach attains state-of-the-art results, achieving an IoU score of 31.73% and a mIoU score of 20.91% and excels at detecting vulnerable road users (VRU). The code will be made available at:https://github.com/DanielMing123/Inverse++
Panoptic-CUDAL Technical Report: Rural Australia Point Cloud Dataset in Rainy Conditions
Mar 20, 2025Existing autonomous driving datasets are predominantly oriented towards well-structured urban settings and favorable weather conditions, leaving the complexities of rural environments and adverse weather conditions largely unaddressed. Although some datasets encompass variations in weather and lighting, bad weather scenarios do not appear often. Rainfall can significantly impair sensor functionality, introducing noise and reflections in LiDAR and camera data and reducing the system's capabilities for reliable environmental perception and safe navigation. We introduce the Panoptic-CUDAL dataset, a novel dataset purpose-built for panoptic segmentation in rural areas subject to rain. By recording high-resolution LiDAR, camera, and pose data, Panoptic-CUDAL offers a diverse, information-rich dataset in a challenging scenario. We present analysis of the recorded data and provide baseline results for panoptic and semantic segmentation methods on LiDAR point clouds. The dataset can be found here: https://robotics.sydney.edu.au/our-research/intelligent-transportation-systems/