 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFusionOcc: Student's t-Distribution Based Object-Centric Multi-Sensor Fusion Framework for 3D Occupancy Prediction
Feb 06, 20263D semantic occupancy prediction enables autonomous vehicles (AVs) to perceive fine-grained geometric and semantic structure of their surroundings from onboard sensors, which is essential for safe decision-making and navigation. Recent models for 3D semantic occupancy prediction have successfully addressed the challenge of describing real-world objects with varied shapes and classes. However, the intermediate representations used by existing methods for 3D semantic occupancy prediction rely heavily on 3D voxel volumes or a set of 3D Gaussians, hindering the model's ability to efficiently and effectively capture fine-grained geometric details in the 3D driving environment. This paper introduces TFusionOcc, a novel object-centric multi-sensor fusion framework for predicting 3D semantic occupancy. By leveraging multi-stage multi-sensor fusion, Student's t-distribution, and the T-Mixture model (TMM), together with more geometrically flexible primitives, such as the deformable superquadric (superquadric with inverse warp), the proposed method achieved state-of-the-art (SOTA) performance on the nuScenes benchmark. In addition, extensive experiments were conducted on the nuScenes-C dataset to demonstrate the robustness of the proposed method in different camera and lidar corruption scenarios. The code will be available at: https://github.com/DanielMing123/TFusionOcc
OccCylindrical: Multi-Modal Fusion with Cylindrical Representation for 3D Semantic Occupancy Prediction
May 06, 2025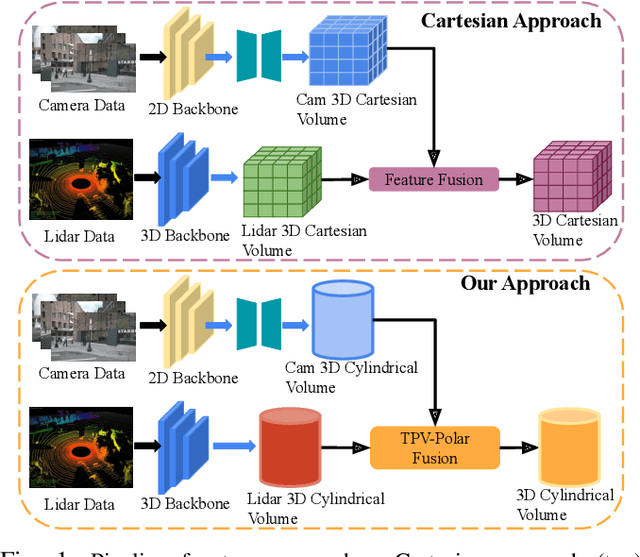
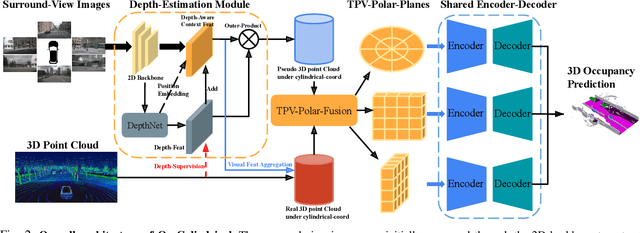
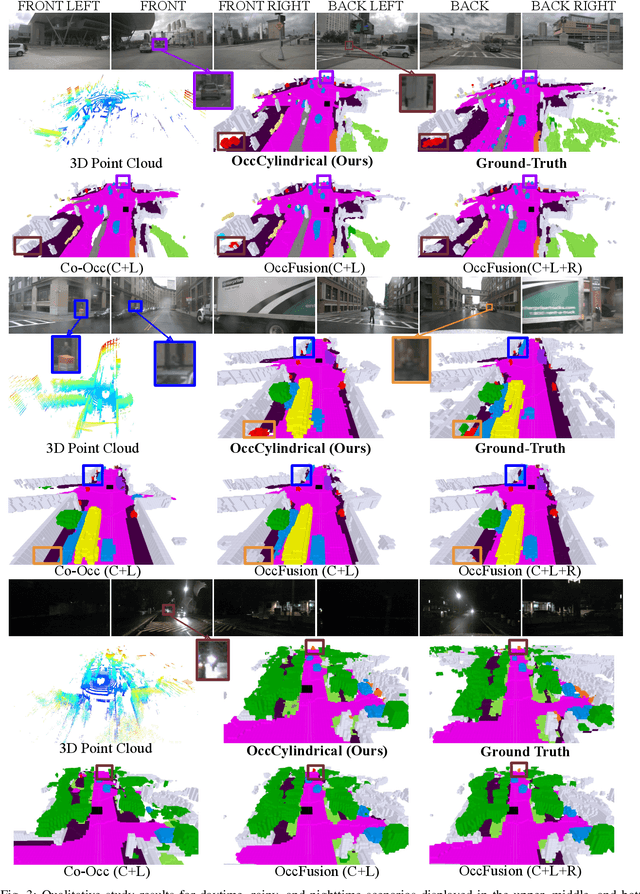
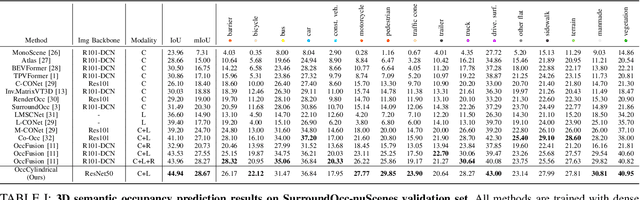
The safe operation of autonomous vehicles (AVs) is highly dependent on their understanding of the surroundings. For this, the task of 3D semantic occupancy prediction divides the space around the sensors into voxels, and labels each voxel with both occupancy and semantic information. Recent perception models have used multisensor fusion to perform this task. However, existing multisensor fusion-based approaches focus mainly on using sensor information in the Cartesian coordinate system. This ignores the distribution of the sensor readings, leading to a loss of fine-grained details and performance degradation. In this paper, we propose OccCylindrical that merges and refines the different modality features under cylindrical coordinates. Our method preserves more fine-grained geometry detail that leads to better performance. Extensive experiments conducted on the nuScenes dataset, including challenging rainy and nighttime scenarios, confirm our approach's effectiveness and state-of-the-art performance. The code will be available at: https://github.com/DanielMing123/OccCylindrical
InterLoc: LiDAR-based Intersection Localization using Road Segmentation with Automated Evaluation Method
May 01, 2025Intersections are geometric and functional key points in every road network. They offer strong landmarks to correct GNSS dropouts and anchor new sensor data in up-to-date maps. Despite that importance, intersection detectors either ignore the rich semantic information already computed onboard or depend on scarce, hand-labeled intersection datasets. To close that gap, this paper presents a LiDAR-based method for intersection detection that (i) fuses semantic road segmentation with vehicle localization to detect intersection candidates in a bird's eye view (BEV) representation and (ii) refines those candidates by analyzing branch topology with a least squares formulation. To evaluate our method, we introduce an automated benchmarking pipeline that pairs detections with OpenStreetMap (OSM) intersection nodes using precise GNSS/INS ground-truth poses. Tested on eight SemanticKITTI sequences, the approach achieves a mean localization error of 1.9 m, 89% precision, and 77% recall at a 5 m tolerance, outperforming the latest learning-based baseline. Moreover, the method is robust to segmentation errors higher than those of the benchmark model, demonstrating its applicability in the real world.
Inverse++: Vision-Centric 3D Semantic Occupancy Prediction Assisted with 3D Object Detection
Apr 07, 20253D semantic occupancy prediction aims to forecast detailed geometric and semantic information of the surrounding environment for autonomous vehicles (AVs) using onboard surround-view cameras. Existing methods primarily focus on intricate inner structure module designs to improve model performance, such as efficient feature sampling and aggregation processes or intermediate feature representation formats. In this paper, we explore multitask learning by introducing an additional 3D supervision signal by incorporating an additional 3D object detection auxiliary branch. This extra 3D supervision signal enhances the model's overall performance by strengthening the capability of the intermediate features to capture small dynamic objects in the scene, and these small dynamic objects often include vulnerable road users, i.e. bicycles, motorcycles, and pedestrians, whose detection is crucial for ensuring driving safety in autonomous vehicles. Extensive experiments conducted on the nuScenes datasets, including challenging rainy and nighttime scenarios, showcase that our approach attains state-of-the-art results, achieving an IoU score of 31.73% and a mIoU score of 20.91% and excels at detecting vulnerable road users (VRU). The code will be made available at:https://github.com/DanielMing123/Inverse++
OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
Mar 13, 2024



This paper introduces OccFusion, a straightforward and efficient sensor fusion framework for predicting 3D occupancy. A comprehensive understanding of 3D scenes is crucial in autonomous driving, and recent models for 3D semantic occupancy prediction have successfully addressed the challenge of describing real-world objects with varied shapes and classes. However, existing methods for 3D occupancy prediction heavily rely on surround-view camera images, making them susceptible to changes in lighting and weather conditions. By integrating features from additional sensors, such as lidar and surround view radars, our framework enhances the accuracy and robustness of occupancy prediction, resulting in top-tier performance on the nuScenes benchmark. Furthermore, extensive experiments conducted on the nuScenes dataset, including challenging night and rainy scenarios, confirm the superior performance of our sensor fusion strategy across various perception ranges. The code for this framework will be made available at https://github.com/DanielMing123/OCCFusion.
InverseMatrixVT3D: An Efficient Projection Matrix-Based Approach for 3D Occupancy Prediction
Jan 23, 2024



This paper introduces InverseMatrixVT3D, an efficient method for transforming multi-view image features into 3D feature volumes for 3D semantic occupancy prediction. Existing methods for constructing 3D volumes often rely on depth estimation, device-specific operators, or transformer queries, which hinders the widespread adoption of 3D occupancy models. In contrast, our approach leverages two projection matrices to store the static mapping relationships and matrix multiplications to efficiently generate global Bird's Eye View (BEV) features and local 3D feature volumes. Specifically, we achieve this by performing matrix multiplications between multi-view image feature maps and two sparse projection matrices. We introduce a sparse matrix handling technique for the projection matrices to optimise GPU memory usage. Moreover, a global-local attention fusion module is proposed to integrate the global BEV features with the local 3D feature volumes to obtain the final 3D volume. We also employ a multi-scale supervision mechanism to further enhance performance. Comprehensive experiments on the nuScenes dataset demonstrate the simplicity and effectiveness of our method. The code will be made available at:https://github.com/DanielMing123/InverseMatrixVT3D
LightFormer: An End-to-End Model for Intersection Right-of-Way Recognition Using Traffic Light Signals and an Attention Mechanism
Jul 14, 2023For smart vehicles driving through signalised intersections, it is crucial to determine whether the vehicle has right of way given the state of the traffic lights. To address this issue, camera based sensors can be used to determine whether the vehicle has permission to proceed straight, turn left or turn right. This paper proposes a novel end to end intersection right of way recognition model called LightFormer to generate right of way status for available driving directions in complex urban intersections. The model includes a spatial temporal inner structure with an attention mechanism, which incorporates features from past image to contribute to the classification of the current frame right of way status. In addition, a modified, multi weight arcface loss is introduced to enhance the model classification performance. Finally, the proposed LightFormer is trained and tested on two public traffic light datasets with manually augmented labels to demonstrate its effectiveness.