 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Era of End-to-End Autonomy: Transitioning from Rule-Based Driving to Large Driving Models
Mar 17, 2026Autonomous driving is undergoing a shift from modular rule based pipelines toward end to end (E2E) learning systems. This paper examines this transition by tracing the evolution from classical sense perceive plan control architectures to large driving models (LDMs) capable of mapping raw sensor input directly to driving actions. We analyze recent developments including Tesla's Full Self Driving (FSD) V12 V14, Rivian's Unified Intelligence platform, NVIDIA Cosmos, and emerging commercial robotaxi deployments, focusing on architectural design, deployment strategies, safety considerations and industry implications. A key emerging product category is supervised E2E driving, often referred to as FSD (Supervised) or L2 plus plus, which several manufacturers plan to deploy from 2026 onwards. These systems can perform most of the Dynamic Driving Task (DDT) in complex environments while requiring human supervision, shifting the driver's role to safety oversight. Early operational evidence suggests E2E learning handles the long tail distribution of real world driving scenarios and is becoming a dominant commercial strategy. We also discuss how similar architectural advances may extend beyond autonomous vehicles (AV) to other embodied AI systems, including humanoid robotics.
MS3D++: Ensemble of Experts for Multi-Source Unsupervised Domain Adaption in 3D Object Detection
Aug 11, 2023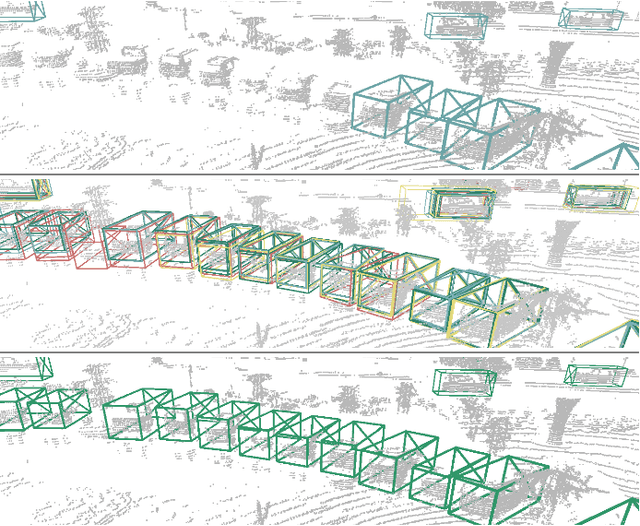
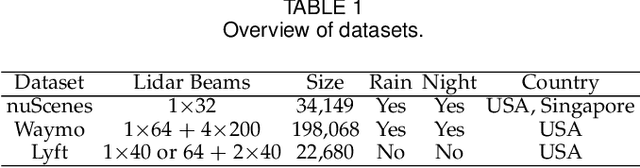
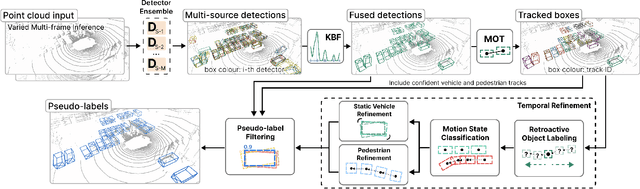
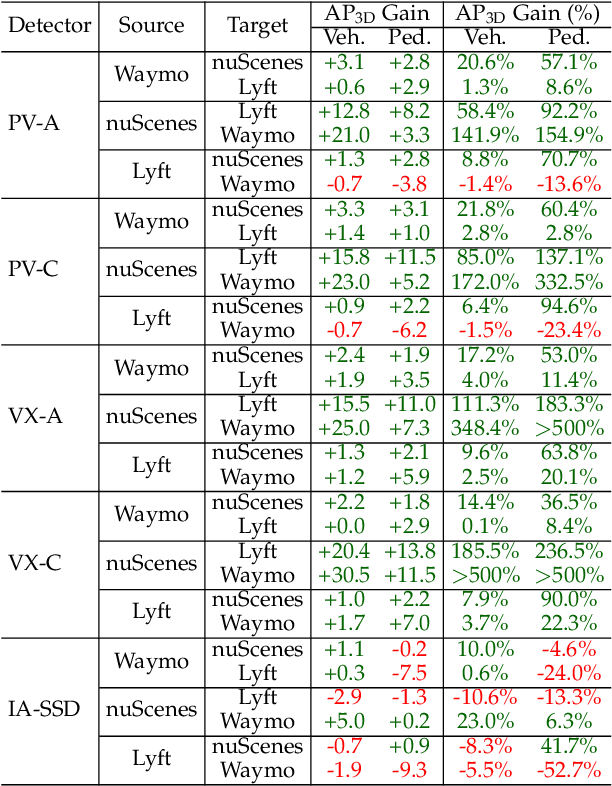
Deploying 3D detectors in unfamiliar domains has been demonstrated to result in a drastic drop of up to 70-90% in detection rate due to variations in lidar, geographical region, or weather conditions from their original training dataset. This domain gap leads to missing detections for densely observed objects, misaligned confidence scores, and increased high-confidence false positives, rendering the detector highly unreliable. To address this, we introduce MS3D++, a self-training framework for multi-source unsupervised domain adaptation in 3D object detection. MS3D++ provides a straightforward approach to domain adaptation by generating high-quality pseudo-labels, enabling the adaptation of 3D detectors to a diverse range of lidar types, regardless of their density. Our approach effectively fuses predictions of an ensemble of multi-frame pre-trained detectors from different source domains to improve domain generalization. We subsequently refine the predictions temporally to ensure temporal consistency in box localization and object classification. Furthermore, we present an in-depth study into the performance and idiosyncrasies of various 3D detector components in a cross-domain context, providing valuable insights for improved cross-domain detector ensembling. Experimental results on Waymo, nuScenes and Lyft demonstrate that detectors trained with MS3D++ pseudo-labels achieve state-of-the-art performance, comparable to training with human-annotated labels in Bird's Eye View (BEV) evaluation for both low and high density lidar.
LightFormer: An End-to-End Model for Intersection Right-of-Way Recognition Using Traffic Light Signals and an Attention Mechanism
Jul 14, 2023For smart vehicles driving through signalised intersections, it is crucial to determine whether the vehicle has right of way given the state of the traffic lights. To address this issue, camera based sensors can be used to determine whether the vehicle has permission to proceed straight, turn left or turn right. This paper proposes a novel end to end intersection right of way recognition model called LightFormer to generate right of way status for available driving directions in complex urban intersections. The model includes a spatial temporal inner structure with an attention mechanism, which incorporates features from past image to contribute to the classification of the current frame right of way status. In addition, a modified, multi weight arcface loss is introduced to enhance the model classification performance. Finally, the proposed LightFormer is trained and tested on two public traffic light datasets with manually augmented labels to demonstrate its effectiveness.
MS3D: Leveraging Multiple Detectors for Unsupervised Domain Adaptation in 3D Object Detection
Apr 10, 2023



We introduce Multi-Source 3D (MS3D), a new self-training pipeline for unsupervised domain adaptation in 3D object detection. Despite the remarkable accuracy of 3D detectors, they often overfit to specific domain biases, leading to suboptimal performance in various sensor setups and environments. Existing methods typically focus on adapting a single detector to the target domain, overlooking the fact that different detectors possess distinct expertise on different unseen domains. MS3D leverages this by combining different pre-trained detectors from multiple source domains and incorporating temporal information to produce high-quality pseudo-labels for fine-tuning. Our proposed Kernel-Density Estimation (KDE) Box Fusion method fuses box proposals from multiple domains to obtain pseudo-labels that surpass the performance of the best source domain detectors. MS3D exhibits greater robustness to domain shifts and produces accurate pseudo-labels over greater distances, making it well-suited for high-to-low beam domain adaptation and vice versa. Our method achieved state-of-the-art performance on all evaluated datasets, and we demonstrate that the choice of pre-trained source detectors has minimal impact on the self-training result, making MS3D suitable for real-world applications.
Viewer-Centred Surface Completion for Unsupervised Domain Adaptation in 3D Object Detection
Sep 14, 2022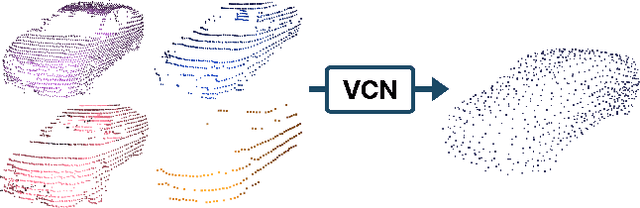
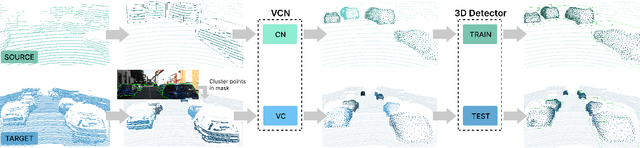
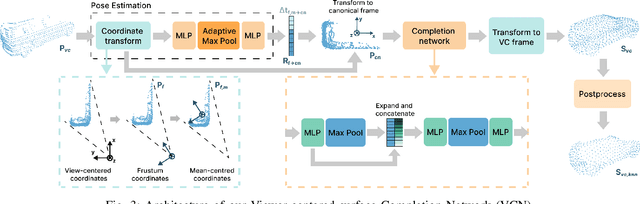

Every autonomous driving dataset has a different configuration of sensors, originating from distinct geographic regions and covering various scenarios. As a result, 3D detectors tend to overfit the datasets they are trained on. This causes a drastic decrease in accuracy when the detectors are trained on one dataset and tested on another. We observe that lidar scan pattern differences form a large component of this reduction in performance. We address this in our approach, SEE-VCN, by designing a novel viewer-centred surface completion network (VCN) to complete the surfaces of objects of interest within an unsupervised domain adaptation framework, SEE. With SEE-VCN, we obtain a unified representation of objects across datasets, allowing the network to focus on learning geometry, rather than overfitting on scan patterns. By adopting a domain-invariant representation, SEE-VCN can be classed as a multi-target domain adaptation approach where no annotations or re-training is required to obtain 3D detections for new scan patterns. Through extensive experiments, we show that our approach outperforms previous domain adaptation methods in multiple domain adaptation settings. Our code and data are available at https://github.com/darrenjkt/SEE-VCN.
Critical concrete scenario generation using scenario-based falsification
Aug 29, 2022

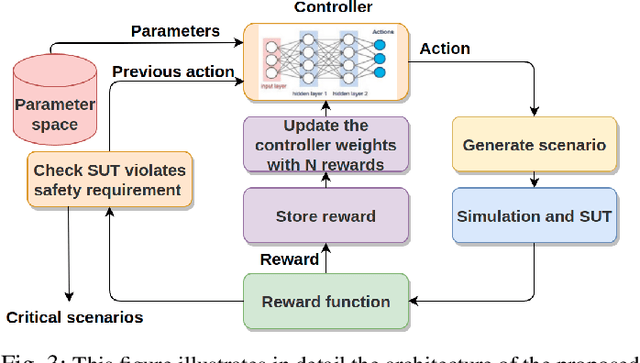

Autonomous vehicles have the potential to lower the accident rate when compared to human driving. Moreover, it is the driving force of the automated vehicles' rapid development over the last few years. In the higher Society of Automotive Engineers (SAE) automation level, the vehicle's and passengers' safety responsibility is transferred from the driver to the automated system, so thoroughly validating such a system is essential. Recently, academia and industry have embraced scenario-based evaluation as the complementary approach to road testing, reducing the overall testing effort required. It is essential to determine the system's flaws before deploying it on public roads as there is no safety driver to guarantee the reliability of such a system. This paper proposes a Reinforcement Learning (RL) based scenario-based falsification method to search for a high-risk scenario in a pedestrian crossing traffic situation. We define a scenario as risky when a system under testing (SUT) does not satisfy the requirement. The reward function for our RL approach is based on Intel's Responsibility Sensitive Safety(RSS), Euclidean distance, and distance to a potential collision.
Parameterisation of lane-change scenarios from real-world data
Jun 20, 2022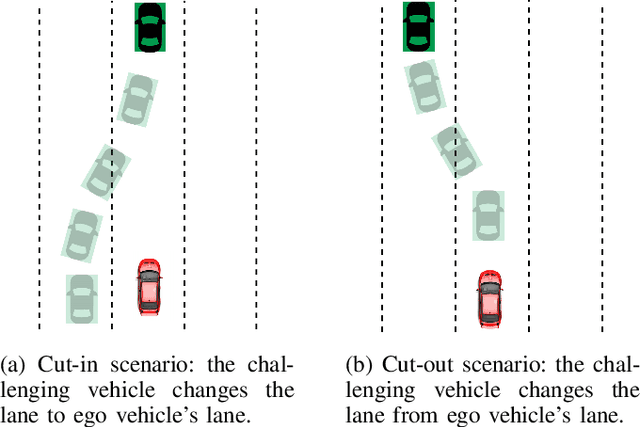


Recent Autonomous Vehicles (AV) technology includes machine learning and probabilistic techniques that add significant complexity to the traditional verification and validation methods. The research community and industry have widely accepted scenario-based testing in the last few years. As it is focused directly on the relevant crucial road situations, it can reduce the effort required in testing. Encoding real-world traffic participants' behaviour is essential to efficiently assess the System Under Test (SUT) in scenario-based testing. So, it is necessary to capture the scenario parameters from the real-world data that can model scenarios realistically in simulation. The primary emphasis of the paper is to identify the list of meaningful parameters that adequately model real-world lane-change scenarios. With these parameters, it is possible to build a parameter space capable of generating a range of challenging scenarios for AV testing efficiently. We validate our approach using Root Mean Square Error(RMSE) to compare the scenarios generated using the proposed parameters against the real-world trajectory data. In addition to that, we demonstrate that adding a slight disturbance to a few scenario parameters can generate different scenarios and utilise Responsibility-Sensitive Safety (RSS) metric to measure the scenarios' risk.
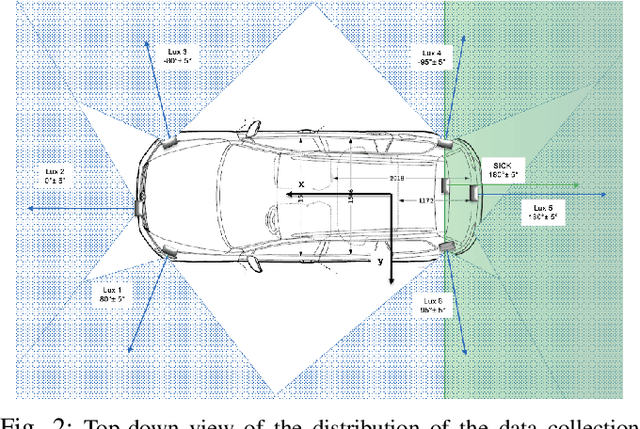
A Novel Probabilistic V2X Data Fusion Framework for Cooperative Perception
Mar 31, 2022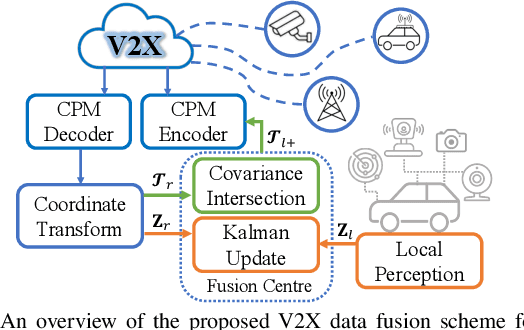
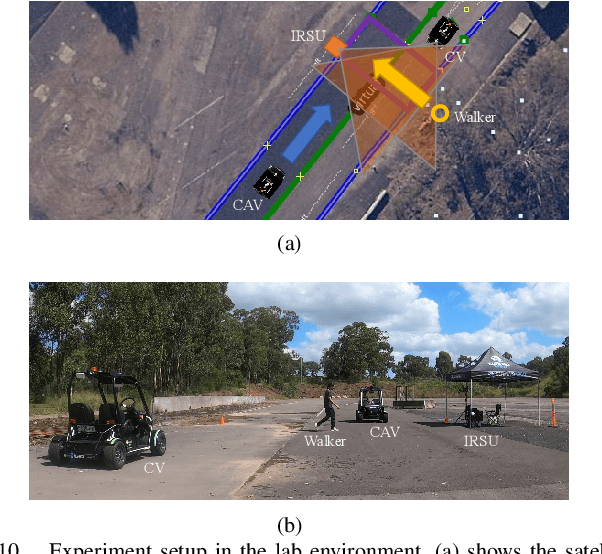
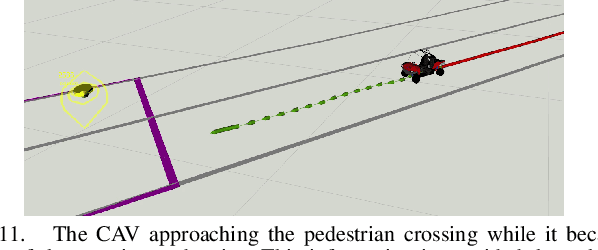
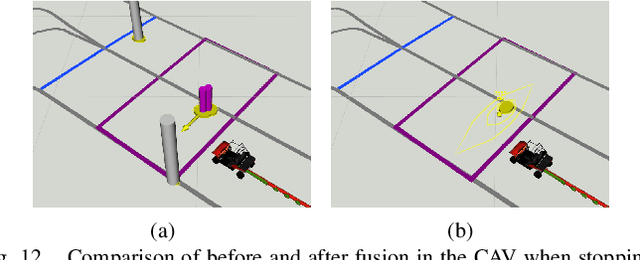
The paper addresses the vehicle-to-X (V2X) data fusion for cooperative or collective perception (CP). This emerging and promising intelligent transportation systems (ITS) technology has enormous potential for improving efficiency and safety of road transportation. Recent advances in V2X communication primarily address the definition of V2X messages and data dissemination amongst ITS stations (ITS-Ss) in a traffic environment. Yet, a largely unsolved problem is how a connected vehicle (CV) can efficiently and consistently fuse its local perception information with the data received from other ITS-Ss. In this paper, we present a novel data fusion framework to fuse the local and V2X perception data for CP that considers the presence of cross-correlation. The proposed approach is validated through comprehensive results obtained from numerical simulation, CARLA simulation, and real-world experimentation that incorporates V2X-enabled intelligent platforms. The real-world experiment includes a CV, a connected and automated vehicle (CAV), and an intelligent roadside unit (IRSU) retrofitted with vision and lidar sensors. We also demonstrate how the fused CP information can improve the awareness of vulnerable road users (VRU) for CV/CAV, and how this information can be considered in path planning/decision making within the CAV to facilitate safe interactions.
Automatic lane change scenario extraction and generation of scenarios in OpenX format from real-world data
Mar 14, 2022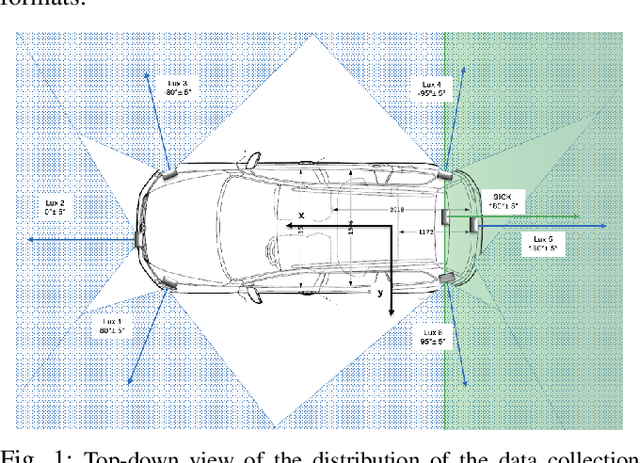

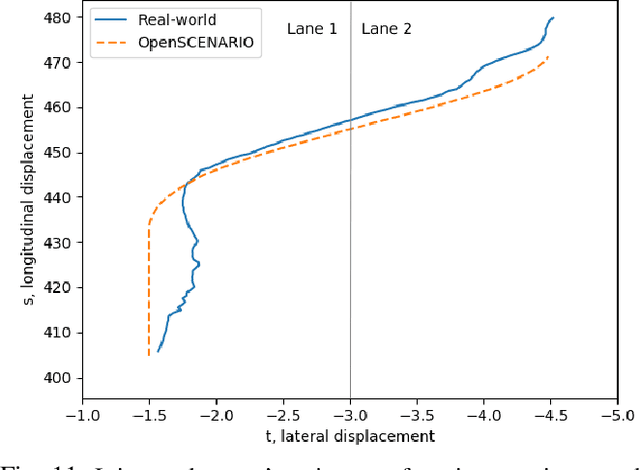
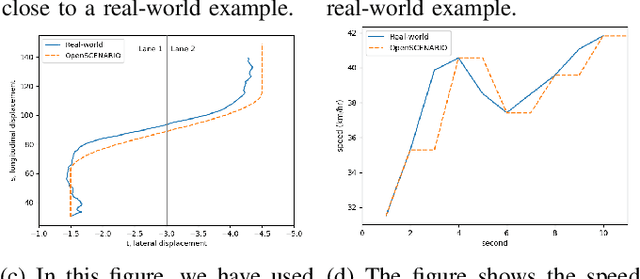
Autonomous Vehicles (AV)'s wide-scale deployment appears imminent despite many safety challenges yet to be resolved. The modern autonomous vehicles will undoubtedly include machine learning and probabilistic techniques that add significant complexity to the traditional verification and validation methods. Road testing is essential before the deployment, but scenarios are repeatable, and it's hard to collect challenging events. Exploring numerous, diverse and crucial scenarios is a time-consuming and expensive approach. The research community and industry have widely accepted scenario-based testing in the last few years. As it is focused directly on the relevant critical road situations, it can reduce the effort required in testing. The scenario-based testing in simulation requires the realistic behaviour of the traffic participants to assess the System Under Test (SUT). It is essential to capture the scenarios from the real world to encode the behaviour of actual traffic participants. This paper proposes a novel scenario extraction method to capture the lane change scenarios using point-cloud data and object tracking information. This method enables fully automatic scenario extraction compared to similar approaches in this area. The generated scenarios are represented in OpenX format to reuse them in the SUT evaluation easily. The motivation of this framework is to build a validation dataset to generate many critical concrete scenarios. The code is available online at https://github.com/dkarunakaran/scenario_extraction_framework.
See Eye to Eye: A Lidar-Agnostic 3D Detection Framework for Unsupervised Multi-Target Domain Adaptation
Nov 17, 2021
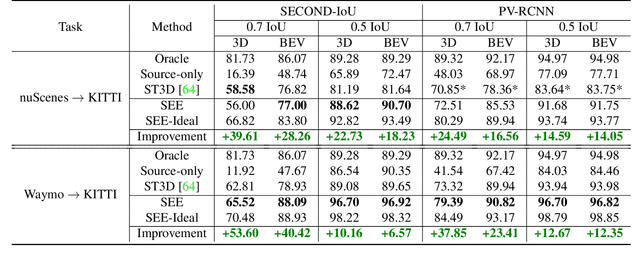
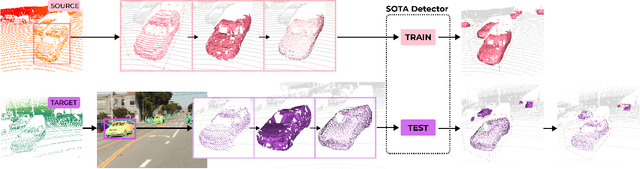

Sampling discrepancies between different manufacturers and models of lidar sensors result in inconsistent representations of objects. This leads to performance degradation when 3D detectors trained for one lidar are tested on other types of lidars. Remarkable progress in lidar manufacturing has brought about advances in mechanical, solid-state, and recently, adjustable scan pattern lidars. For the latter, existing works often require fine-tuning the model each time scan patterns are adjusted, which is infeasible. We explicitly deal with the sampling discrepancy by proposing a novel unsupervised multi-target domain adaptation framework, SEE, for transferring the performance of state-of-the-art 3D detectors across both fixed and flexible scan pattern lidars without requiring fine-tuning of models by end-users. Our approach interpolates the underlying geometry and normalizes the scan pattern of objects from different lidars before passing them to the detection network. We demonstrate the effectiveness of SEE on public datasets, achieving state-of-the-art results, and additionally provide quantitative results on a novel high-resolution lidar to prove the industry applications of our framework. This dataset and our code will be made publicly available.