 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS3D++: Ensemble of Experts for Multi-Source Unsupervised Domain Adaption in 3D Object Detection
Paper and Code
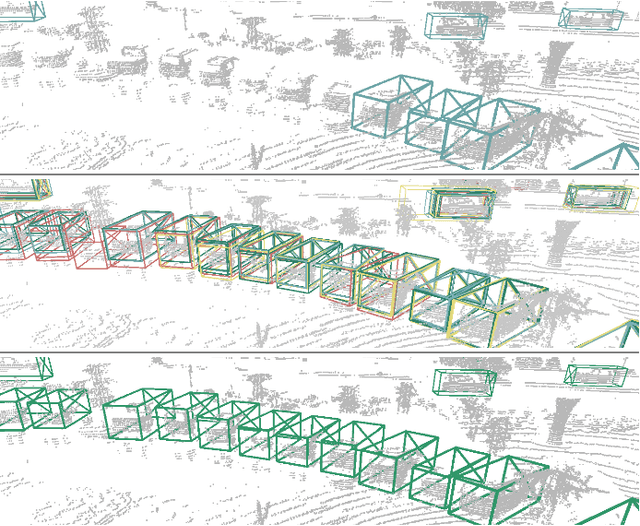
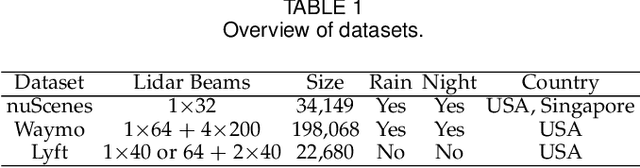
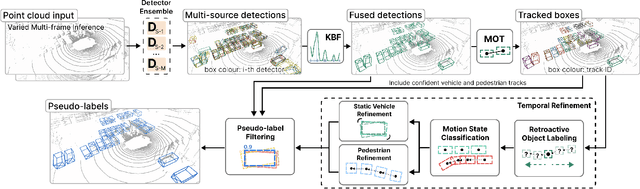
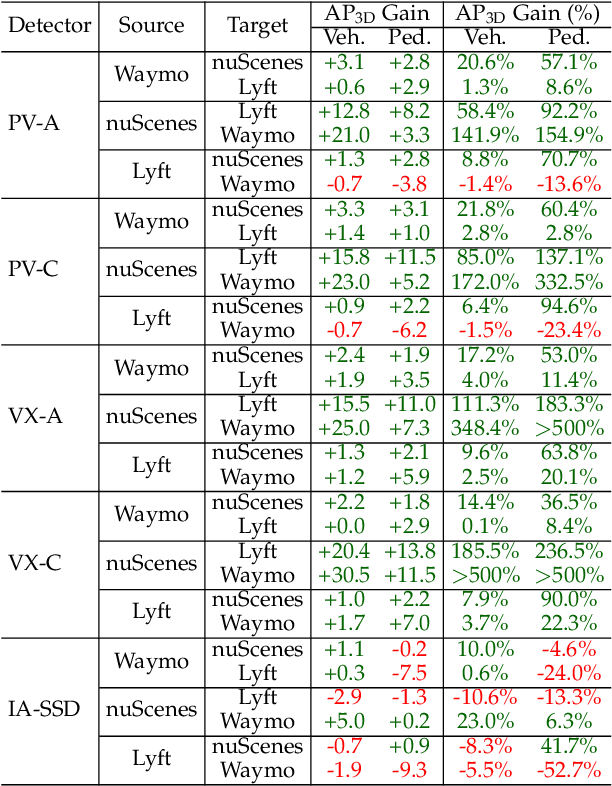
Deploying 3D detectors in unfamiliar domains has been demonstrated to result in a drastic drop of up to 70-90% in detection rate due to variations in lidar, geographical region, or weather conditions from their original training dataset. This domain gap leads to missing detections for densely observed objects, misaligned confidence scores, and increased high-confidence false positives, rendering the detector highly unreliable. To address this, we introduce MS3D++, a self-training framework for multi-source unsupervised domain adaptation in 3D object detection. MS3D++ provides a straightforward approach to domain adaptation by generating high-quality pseudo-labels, enabling the adaptation of 3D detectors to a diverse range of lidar types, regardless of their density. Our approach effectively fuses predictions of an ensemble of multi-frame pre-trained detectors from different source domains to improve domain generalization. We subsequently refine the predictions temporally to ensure temporal consistency in box localization and object classification. Furthermore, we present an in-depth study into the performance and idiosyncrasies of various 3D detector components in a cross-domain context, providing valuable insights for improved cross-domain detector ensembling. Experimental results on Waymo, nuScenes and Lyft demonstrate that detectors trained with MS3D++ pseudo-labels achieve state-of-the-art performance, comparable to training with human-annotated labels in Bird's Eye View (BEV) evaluation for both low and high density lidar.