 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS3D++: Ensemble of Experts for Multi-Source Unsupervised Domain Adaption in 3D Object Detection
Aug 11, 2023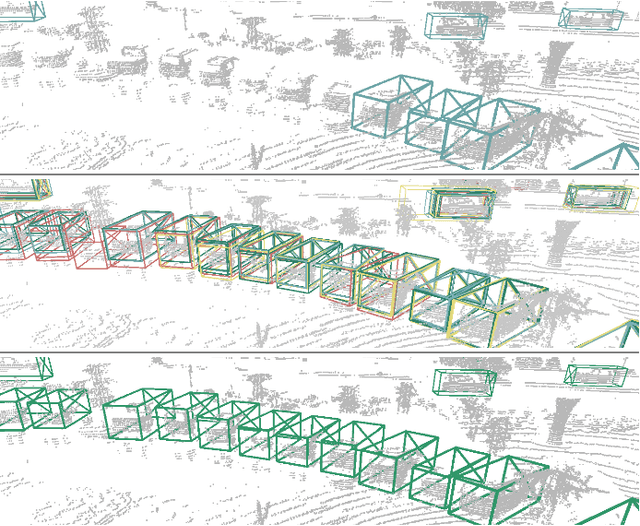
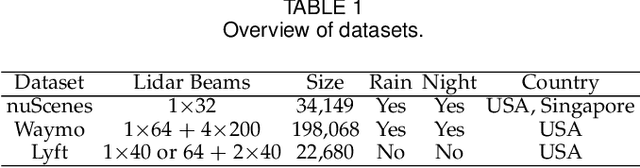
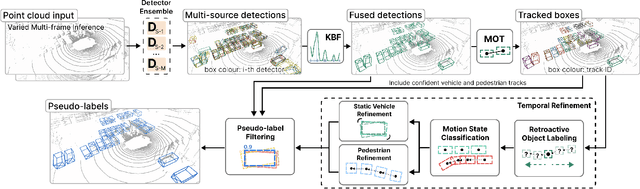
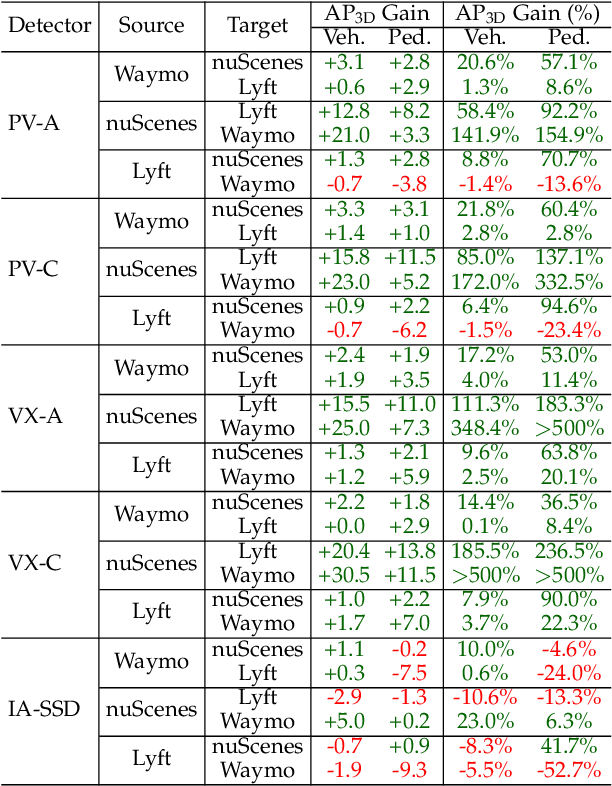
Deploying 3D detectors in unfamiliar domains has been demonstrated to result in a drastic drop of up to 70-90% in detection rate due to variations in lidar, geographical region, or weather conditions from their original training dataset. This domain gap leads to missing detections for densely observed objects, misaligned confidence scores, and increased high-confidence false positives, rendering the detector highly unreliable. To address this, we introduce MS3D++, a self-training framework for multi-source unsupervised domain adaptation in 3D object detection. MS3D++ provides a straightforward approach to domain adaptation by generating high-quality pseudo-labels, enabling the adaptation of 3D detectors to a diverse range of lidar types, regardless of their density. Our approach effectively fuses predictions of an ensemble of multi-frame pre-trained detectors from different source domains to improve domain generalization. We subsequently refine the predictions temporally to ensure temporal consistency in box localization and object classification. Furthermore, we present an in-depth study into the performance and idiosyncrasies of various 3D detector components in a cross-domain context, providing valuable insights for improved cross-domain detector ensembling. Experimental results on Waymo, nuScenes and Lyft demonstrate that detectors trained with MS3D++ pseudo-labels achieve state-of-the-art performance, comparable to training with human-annotated labels in Bird's Eye View (BEV) evaluation for both low and high density lidar.
MS3D: Leveraging Multiple Detectors for Unsupervised Domain Adaptation in 3D Object Detection
Apr 10, 2023



We introduce Multi-Source 3D (MS3D), a new self-training pipeline for unsupervised domain adaptation in 3D object detection. Despite the remarkable accuracy of 3D detectors, they often overfit to specific domain biases, leading to suboptimal performance in various sensor setups and environments. Existing methods typically focus on adapting a single detector to the target domain, overlooking the fact that different detectors possess distinct expertise on different unseen domains. MS3D leverages this by combining different pre-trained detectors from multiple source domains and incorporating temporal information to produce high-quality pseudo-labels for fine-tuning. Our proposed Kernel-Density Estimation (KDE) Box Fusion method fuses box proposals from multiple domains to obtain pseudo-labels that surpass the performance of the best source domain detectors. MS3D exhibits greater robustness to domain shifts and produces accurate pseudo-labels over greater distances, making it well-suited for high-to-low beam domain adaptation and vice versa. Our method achieved state-of-the-art performance on all evaluated datasets, and we demonstrate that the choice of pre-trained source detectors has minimal impact on the self-training result, making MS3D suitable for real-world applications.
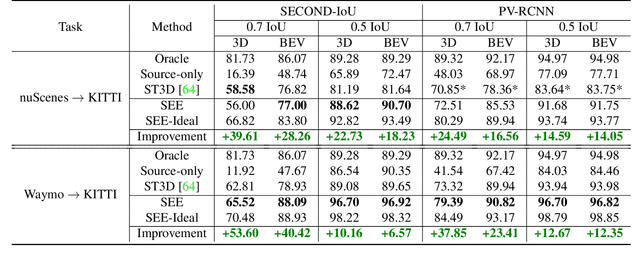
Viewer-Centred Surface Completion for Unsupervised Domain Adaptation in 3D Object Detection
Sep 14, 2022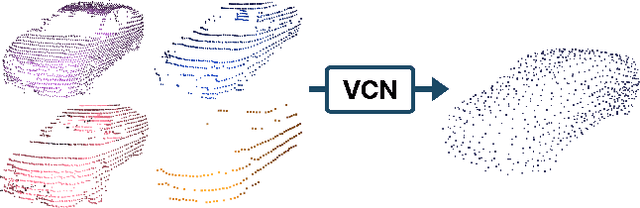
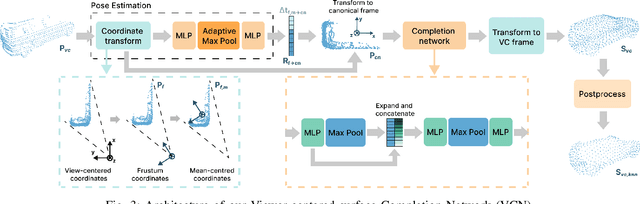

Every autonomous driving dataset has a different configuration of sensors, originating from distinct geographic regions and covering various scenarios. As a result, 3D detectors tend to overfit the datasets they are trained on. This causes a drastic decrease in accuracy when the detectors are trained on one dataset and tested on another. We observe that lidar scan pattern differences form a large component of this reduction in performance. We address this in our approach, SEE-VCN, by designing a novel viewer-centred surface completion network (VCN) to complete the surfaces of objects of interest within an unsupervised domain adaptation framework, SEE. With SEE-VCN, we obtain a unified representation of objects across datasets, allowing the network to focus on learning geometry, rather than overfitting on scan patterns. By adopting a domain-invariant representation, SEE-VCN can be classed as a multi-target domain adaptation approach where no annotations or re-training is required to obtain 3D detections for new scan patterns. Through extensive experiments, we show that our approach outperforms previous domain adaptation methods in multiple domain adaptation settings. Our code and data are available at https://github.com/darrenjkt/SEE-VCN.
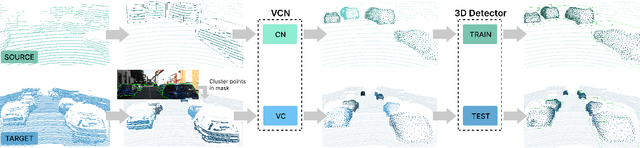
See Eye to Eye: A Lidar-Agnostic 3D Detection Framework for Unsupervised Multi-Target Domain Adaptation
Nov 17, 2021
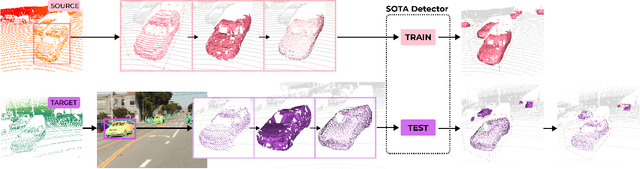

Sampling discrepancies between different manufacturers and models of lidar sensors result in inconsistent representations of objects. This leads to performance degradation when 3D detectors trained for one lidar are tested on other types of lidars. Remarkable progress in lidar manufacturing has brought about advances in mechanical, solid-state, and recently, adjustable scan pattern lidars. For the latter, existing works often require fine-tuning the model each time scan patterns are adjusted, which is infeasible. We explicitly deal with the sampling discrepancy by proposing a novel unsupervised multi-target domain adaptation framework, SEE, for transferring the performance of state-of-the-art 3D detectors across both fixed and flexible scan pattern lidars without requiring fine-tuning of models by end-users. Our approach interpolates the underlying geometry and normalizes the scan pattern of objects from different lidars before passing them to the detection network. We demonstrate the effectiveness of SEE on public datasets, achieving state-of-the-art results, and additionally provide quantitative results on a novel high-resolution lidar to prove the industry applications of our framework. This dataset and our code will be made publicly available.
Optimising the selection of samples for robust lidar camera calibration
Mar 23, 2021



We propose a robust calibration pipeline that optimises the selection of calibration samples for the estimation of calibration parameters that fit the entire scene. We minimise user error by automating the data selection process according to a metric, called Variability of Quality (VOQ) that gives a score to each calibration set of samples. We show that this VOQ score is correlated with the estimated calibration parameter's ability to generalise well to the entire scene, thereby overcoming the overfitting problems of existing calibration algorithms. Our approach has the benefits of simplifying the calibration process for practitioners of any calibration expertise level and providing an objective measure of the quality for our calibration pipeline's input and output data. We additionally use a novel method of assessing the accuracy of the calibration parameters. It involves computing reprojection errors for the entire scene to ensure that the parameters are well fitted to all features in the scene. Our proposed calibration pipeline takes 90s, and obtains an average reprojection error of 1-1.2cm, with standard deviation of 0.4-0.5cm over 46 poses evenly distributed in a scene. This process has been validated by experimentation on a high resolution, software definable lidar, Baraja Spectrum-Scan; and a low, fixed resolution lidar, Velodyne VLP-16. We have shown that despite the vast differences in lidar technologies, our proposed approach manages to estimate robust calibration parameters for both. Our code and data set used for this paper are made available as open-source.