 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow useful is Active Learning for Image-based Plant Phenotyping?
Jul 01, 2020



Deep learning models have been successfully deployed for a diverse array of image-based plant phenotyping applications including disease detection and classification. However, successful deployment of supervised deep learning models requires large amount of labeled data, which is a significant challenge in plant science (and most biological) domains due to the inherent complexity. Specifically, data annotation is costly, laborious, time consuming and needs domain expertise for phenotyping tasks, especially for diseases. To overcome this challenge, active learning algorithms have been proposed that reduce the amount of labeling needed by deep learning models to achieve good predictive performance. Active learning methods adaptively select samples to annotate using an acquisition function to achieve maximum (classification) performance under a fixed labeling budget. We report the performance of four different active learning methods, (1) Deep Bayesian Active Learning (DBAL), (2) Entropy, (3) Least Confidence, and (4) Coreset, with conventional random sampling-based annotation for two different image-based classification datasets. The first image dataset consists of soybean [Glycine max L. (Merr.)] leaves belonging to eight different soybean stresses and a healthy class, and the second consists of nine different weed species from the field. For a fixed labeling budget, we observed that the classification performance of deep learning models with active learning-based acquisition strategies is better than random sampling-based acquisition for both datasets. The integration of active learning strategies for data annotation can help mitigate labelling challenges in the plant sciences applications particularly where deep domain knowledge is required.
Comparison of object detection methods for crop damage assessment using deep learning
Dec 31, 2019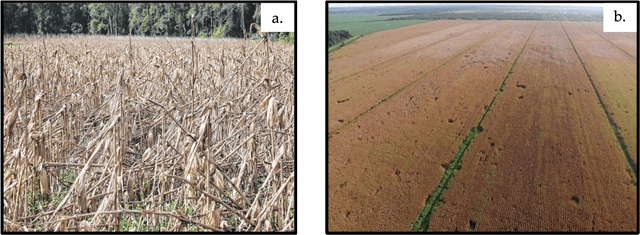


Severe weather events can cause large financial losses to farmers. Detailed information on the location and severity of damage will assist farmers, insurance companies, and disaster response agencies in making wise post-damage decisions. The goal of this study was a proof-of-concept to detect damaged crop areas from aerial imagery using computer vision and deep learning techniques. A specific objective was to compare existing object detection algorithms to determine which was best suited for crop damage detection. Two modes of crop damage common in maize (corn) production were simulated: stalk lodging at the lowest ear and stalk lodging at ground level. Simulated damage was used to create a training and analysis data set. An unmanned aerial system (UAS) equipped with a RGB camera was used for image acquisition. Three popular object detectors (Faster R-CNN, YOLOv2, and RetinaNet) were assessed for their ability to detect damaged regions in a field. Average precision was used to compare object detectors. YOLOv2 and RetinaNet were able to detect crop damage across multiple late-season growth stages. Faster R-CNN was not successful as the other two advanced detectors. Detecting crop damage at later growth stages was more difficult for all tested object detectors. Weed pressure in simulated damage plots and increased target density added additional complexity.
Apricot variety classification using image processing and machine learning approaches
Dec 27, 2019
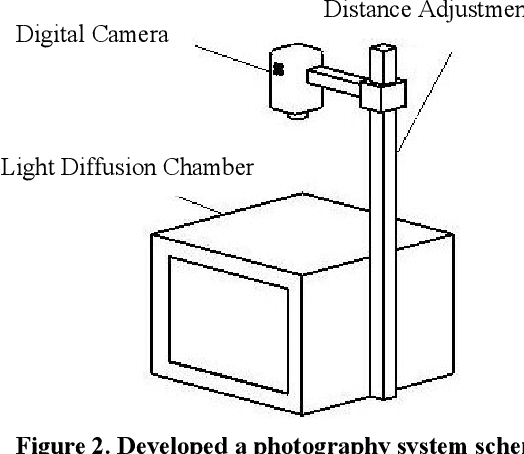
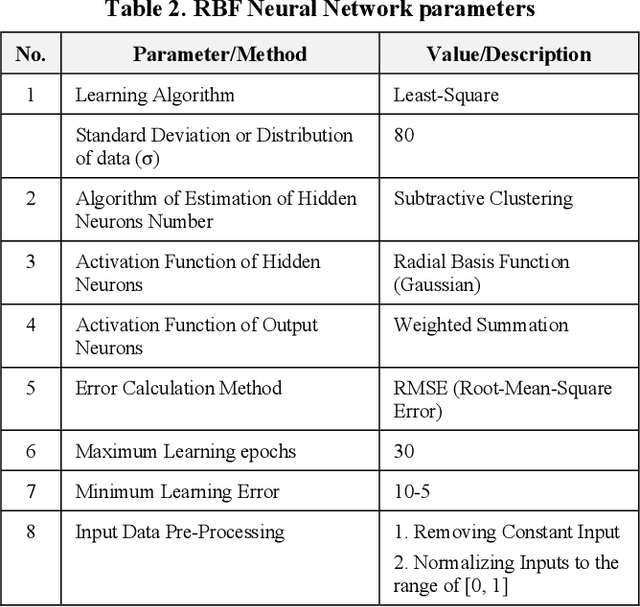
Apricot which is a cultivated type of Zerdali (wild apricot) has an important place in human nutrition and its medical properties are essential for human health. The objective of this research was to obtain a model for apricot mass and separate apricot variety with image processing technology using external features of apricot fruit. In this study, five verities of apricot were used. In order to determine the size of the fruits, three mutually perpendicular axes were defined, length, width, and thickness. Measurements show that the effect of variety on all properties was statistically significant at the 1% probability level. Furthermore, there is no significant difference between the estimated dimensions by image processing approach and the actual dimensions. The developed system consists of a digital camera, a light diffusion chamber, a distance adjustment pedestal, and a personal computer. Images taken by the digital camera were stored as (RGB) for further analysis. The images were taken for a number of 49 samples of each cultivar in three directions. A linear equation is recommended to calculate the apricot mass based on the length and the width with R 2 = 0.97. In addition, ANFIS model with C-means was the best model for classifying the apricot varieties based on the physical features including length, width, thickness, mass, and projected area of three perpendicular surfaces. The accuracy of the model was 87.7.