 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeFlow: Pipelined Processing and Motion-Aware Frame Selection for Long-Form Video Editing
Dec 30, 2025Long-form video editing poses unique challenges due to the exponential increase in the computational cost from joint editing and Denoising Diffusion Implicit Models (DDIM) inversion across extended sequences. To address these limitations, we propose PipeFlow, a scalable, pipelined video editing method that introduces three key innovations: First, based on a motion analysis using Structural Similarity Index Measure (SSIM) and Optical Flow, we identify and propose to skip editing of frames with low motion. Second, we propose a pipelined task scheduling algorithm that splits a video into multiple segments and performs DDIM inversion and joint editing in parallel based on available GPU memory. Lastly, we leverage a neural network-based interpolation technique to smooth out the border frames between segments and interpolate the previously skipped frames. Our method uniquely scales to longer videos by dividing them into smaller segments, allowing PipeFlow's editing time to increase linearly with video length. In principle, this enables editing of infinitely long videos without the growing per-frame computational overhead encountered by other methods. PipeFlow achieves up to a 9.6X speedup compared to TokenFlow and a 31.7X speedup over Diffusion Motion Transfer (DMT).
SubZero: Composing Subject, Style, and Action via Zero-Shot Personalization
Feb 27, 2025Diffusion models are increasingly popular for generative tasks, including personalized composition of subjects and styles. While diffusion models can generate user-specified subjects performing text-guided actions in custom styles, they require fine-tuning and are not feasible for personalization on mobile devices. Hence, tuning-free personalization methods such as IP-Adapters have progressively gained traction. However, for the composition of subjects and styles, these works are less flexible due to their reliance on ControlNet, or show content and style leakage artifacts. To tackle these, we present SubZero, a novel framework to generate any subject in any style, performing any action without the need for fine-tuning. We propose a novel set of constraints to enhance subject and style similarity, while reducing leakage. Additionally, we propose an orthogonalized temporal aggregation scheme in the cross-attention blocks of denoising model, effectively conditioning on a text prompt along with single subject and style images. We also propose a novel method to train customized content and style projectors to reduce content and style leakage. Through extensive experiments, we show that our proposed approach, while suitable for running on-edge, shows significant improvements over state-of-the-art works performing subject, style and action composition.
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


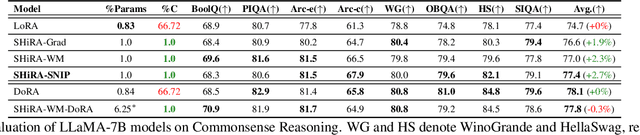
In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
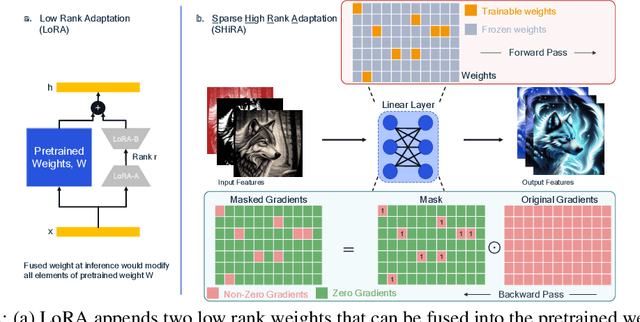
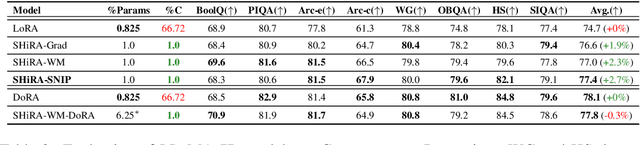
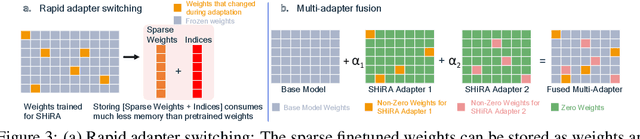
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FouRA: Fourier Low Rank Adaptation
Jun 13, 2024



While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on the GLUE benchmark.
Oh! We Freeze: Improving Quantized Knowledge Distillation via Signal Propagation Analysis for Large Language Models
Mar 28, 2024Large generative models such as large language models (LLMs) and diffusion models have revolutionized the fields of NLP and computer vision respectively. However, their slow inference, high computation and memory requirement makes it challenging to deploy them on edge devices. In this study, we propose a light-weight quantization aware fine tuning technique using knowledge distillation (KD-QAT) to improve the performance of 4-bit weight quantized LLMs using commonly available datasets to realize a popular language use case, on device chat applications. To improve this paradigm of finetuning, as main contributions, we provide insights into stability of KD-QAT by empirically studying the gradient propagation during training to better understand the vulnerabilities of KD-QAT based approaches to low-bit quantization errors. Based on our insights, we propose ov-freeze, a simple technique to stabilize the KD-QAT process. Finally, we experiment with the popular 7B LLaMAv2-Chat model at 4-bit quantization level and demonstrate that ov-freeze results in near floating point precision performance, i.e., less than 0.7% loss of accuracy on Commonsense Reasoning benchmarks.
ZiCo-BC: A Bias Corrected Zero-Shot NAS for Vision Tasks
Sep 26, 2023Zero-Shot Neural Architecture Search (NAS) approaches propose novel training-free metrics called zero-shot proxies to substantially reduce the search time compared to the traditional training-based NAS. Despite the success on image classification, the effectiveness of zero-shot proxies is rarely evaluated on complex vision tasks such as semantic segmentation and object detection. Moreover, existing zero-shot proxies are shown to be biased towards certain model characteristics which restricts their broad applicability. In this paper, we empirically study the bias of state-of-the-art (SOTA) zero-shot proxy ZiCo across multiple vision tasks and observe that ZiCo is biased towards thinner and deeper networks, leading to sub-optimal architectures. To solve the problem, we propose a novel bias correction on ZiCo, called ZiCo-BC. Our extensive experiments across various vision tasks (image classification, object detection and semantic segmentation) show that our approach can successfully search for architectures with higher accuracy and significantly lower latency on Samsung Galaxy S10 devices.
Zero-Shot Neural Architecture Search: Challenges, Solutions, and Opportunities
Jul 05, 2023Recently, zero-shot (or training-free) Neural Architecture Search (NAS) approaches have been proposed to liberate the NAS from training requirements. The key idea behind zero-shot NAS approaches is to design proxies that predict the accuracies of the given networks without training network parameters. The proxies proposed so far are usually inspired by recent progress in theoretical deep learning and have shown great potential on several NAS benchmark datasets. This paper aims to comprehensively review and compare the state-of-the-art (SOTA) zero-shot NAS approaches, with an emphasis on their hardware awareness. To this end, we first review the mainstream zero-shot proxies and discuss their theoretical underpinnings. We then compare these zero-shot proxies through large-scale experiments and demonstrate their effectiveness in both hardware-aware and hardware-oblivious NAS scenarios. Finally, we point out several promising ideas to design better proxies. Our source code and the related paper list are available on https://github.com/SLDGroup/survey-zero-shot-nas.
TIPS: Topologically Important Path Sampling for Anytime Neural Networks
May 13, 2023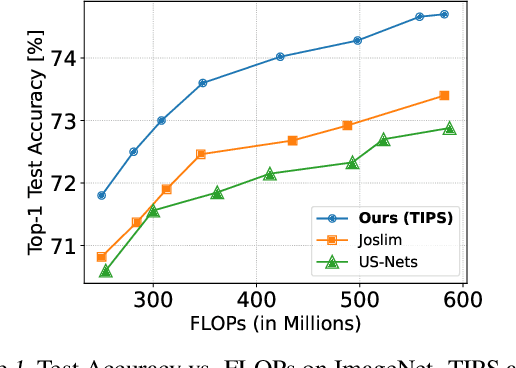
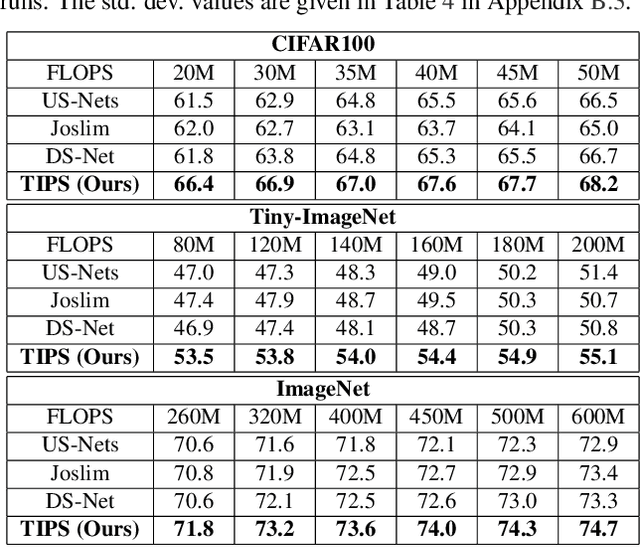
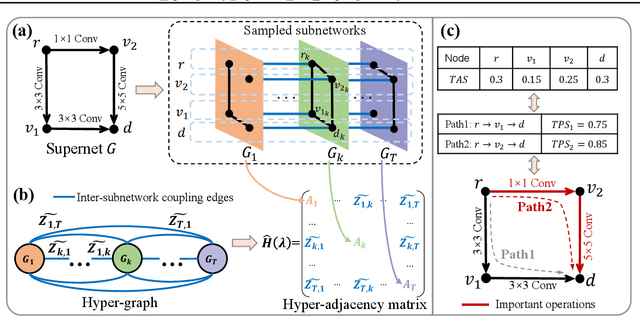
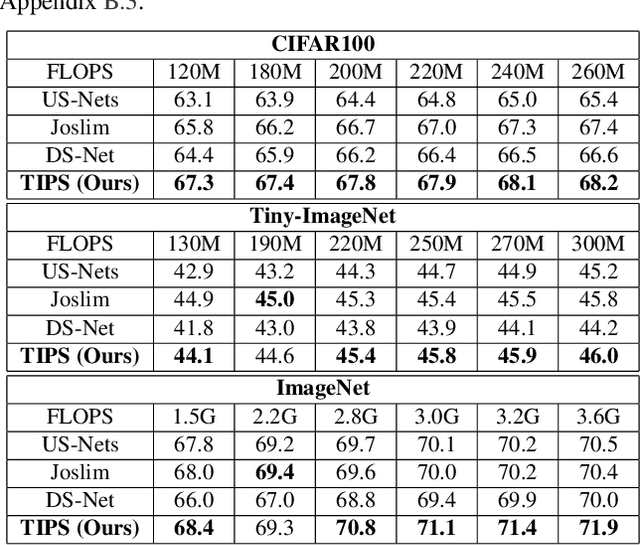
Anytime neural networks (AnytimeNNs) are a promising solution to adaptively adjust the model complexity at runtime under various hardware resource constraints. However, the manually-designed AnytimeNNs are biased by designers' prior experience and thus provide sub-optimal solutions. To address the limitations of existing hand-crafted approaches, we first model the training process of AnytimeNNs as a discrete-time Markov chain (DTMC) and use it to identify the paths that contribute the most to the training of AnytimeNNs. Based on this new DTMC-based analysis, we further propose TIPS, a framework to automatically design AnytimeNNs under various hardware constraints. Our experimental results show that TIPS can improve the convergence rate and test accuracy of AnytimeNNs. Compared to the existing AnytimeNNs approaches, TIPS improves the accuracy by 2%-6.6% on multiple datasets and achieves SOTA accuracy-FLOPs tradeoffs.
ZiCo: Zero-shot NAS via Inverse Coefficient of Variation on Gradients
Jan 26, 2023



Neural Architecture Search (NAS) is widely used to automatically design the neural network with the best performance among a large number of candidate architectures. To reduce the search time, zero-shot NAS aims at designing training-free proxies that can predict the test performance of a given architecture. However, as shown recently, none of the zero-shot proxies proposed to date can actually work consistently better than a naive proxy, namely, the number of network parameters (#Params). To improve this state of affairs, as the main theoretical contribution, we first reveal how some specific gradient properties across different samples impact the convergence rate and generalization capacity of neural networks. Based on this theoretical analysis, we propose a new zero-shot proxy, ZiCo, the first proxy that works consistently better than #Params. We demonstrate that ZiCo works better than State-Of-The-Art (SOTA) proxies on several popular NAS-Benchmarks (NASBench101, NATSBench-SSS/TSS, TransNASBench-101) for multiple applications (e.g., image classification/reconstruction and pixel-level prediction). Finally, we demonstrate that the optimal architectures found via ZiCo are as competitive as the ones found by one-shot and multi-shot NAS methods, but with much less search time. For example, ZiCo-based NAS can find optimal architectures with 78.1%, 79.4%, and 80.4% test accuracy under inference budgets of 450M, 600M, and 1000M FLOPs on ImageNet within 0.4 GPU days.