 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoReDiT: Spatial Coherence-Guided Token Pruning and Reconstruction for Efficient Diffusion Transformers
May 13, 2026Diffusion Transformers (DiTs) deliver remarkable image and video generation quality but incur high computational cost, limiting scalability and on-device deployment. We introduce CoReDiT, a structured token pruning framework for DiTs across vision tasks. CoReDiT uses a linear-time spatial coherence score to estimate local redundancy in the latent token lattice and skips high coherence (redundant) tokens in self-attention. To maintain a dense representation and avoid visual discontinuities, we reconstruct skipped attention outputs via coherence-guided aggregation of spatially neighboring retained tokens. We further introduce a progressive, block-adaptive pruning schedule that increases pruning gradually and allocates larger budgets to blocks and denoising steps with higher redundancy. Across state-of-the-art diffusion backbones including PixArt-α and MagicDrive-V2, CoReDiT achieves up to 55% self-attention FLOPs reduction and inference speedups of 1.33x on cloud GPUs and 1.72x on mobile NPUs, while maintaining high visual quality. Notably, CoReDiT also increases on-device memory head-room, enabling higher-resolution generation.
* 8 pages, 8 figures, CVPR workshop
ZiCo-BC: A Bias Corrected Zero-Shot NAS for Vision Tasks
Sep 26, 2023Zero-Shot Neural Architecture Search (NAS) approaches propose novel training-free metrics called zero-shot proxies to substantially reduce the search time compared to the traditional training-based NAS. Despite the success on image classification, the effectiveness of zero-shot proxies is rarely evaluated on complex vision tasks such as semantic segmentation and object detection. Moreover, existing zero-shot proxies are shown to be biased towards certain model characteristics which restricts their broad applicability. In this paper, we empirically study the bias of state-of-the-art (SOTA) zero-shot proxy ZiCo across multiple vision tasks and observe that ZiCo is biased towards thinner and deeper networks, leading to sub-optimal architectures. To solve the problem, we propose a novel bias correction on ZiCo, called ZiCo-BC. Our extensive experiments across various vision tasks (image classification, object detection and semantic segmentation) show that our approach can successfully search for architectures with higher accuracy and significantly lower latency on Samsung Galaxy S10 devices.
Inference Latency Prediction at the Edge
Oct 06, 2022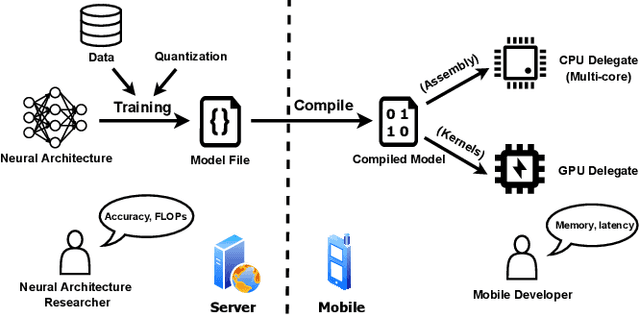
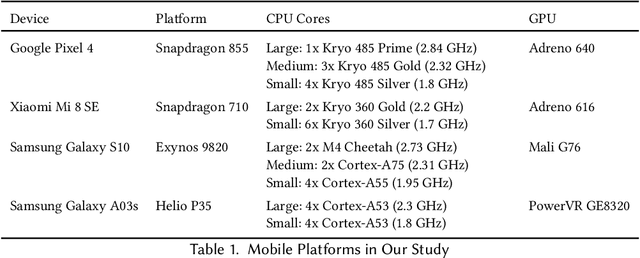
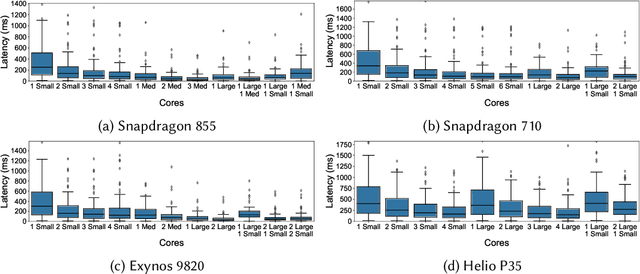
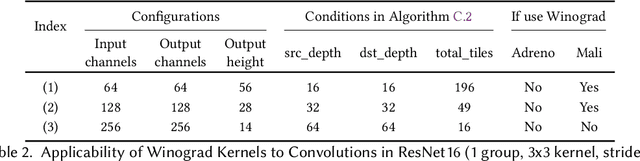
With the growing workload of inference tasks on mobile devices, state-of-the-art neural architectures (NAs) are typically designed through Neural Architecture Search (NAS) to identify NAs with good tradeoffs between accuracy and efficiency (e.g., latency). Since measuring the latency of a huge set of candidate architectures during NAS is not scalable, approaches are needed for predicting end-to-end inference latency on mobile devices. Such predictions are challenging due to hardware heterogeneity, optimizations applied by ML frameworks, and the diversity of neural architectures. Motivated by these challenges, in this paper, we first quantitatively assess characteristics of neural architectures and mobile devices that have significant effects on inference latency. Based on this assessment, we propose a latency prediction framework which addresses these challenges by developing operation-wise latency predictors, under a variety of settings and a number of hardware devices, with multi-core CPUs and GPUs, achieving high accuracy in end-to-end latency prediction, as shown by our comprehensive evaluations. To illustrate that our approach does not require expensive data collection, we also show that accurate predictions can be achieved on real-world NAs using only small amounts of profiling data.
Throughput Prediction of Asynchronous SGD in TensorFlow
Nov 12, 2019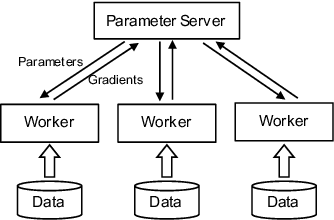

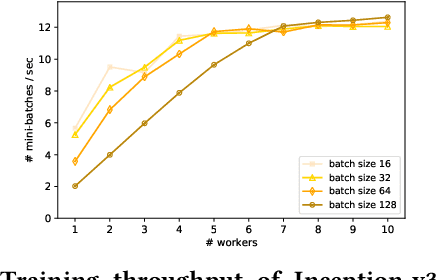
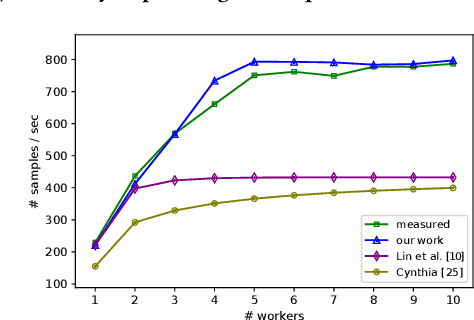
Modern machine learning frameworks can train neural networks using multiple nodes in parallel, each computing parameter updates with stochastic gradient descent (SGD) and sharing them asynchronously through a central parameter server. Due to communication overhead and bottlenecks, the total throughput of SGD updates in a cluster scales sublinearly, saturating as the the number of nodes increases. In this paper, we present a solution to predicting training throughput from profiling traces collected from a single-node configuration. Our approach is able to model the interaction of multiple nodes and the scheduling of concurrent transmissions between the parameter server and each node. By accounting for the dependencies between received parts and pending computations, we predict overlaps between computation and communication and generate synthetic execution traces for configurations with multiple nodes. We validate our approach on TensorFlow training jobs for popular image classification neural networks, on AWS and on our in-house cluster, using nodes equipped with GPUs or only with CPUs. We also investigate the effects of data transmission policies used in TensorFlow and the accuracy of our approach when combined with optimizations of the transmission schedule.