 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Ground Reaction Force from Inertial Sensors
Nov 04, 2023The study of ground reaction forces (GRF) is used to characterize the mechanical loading experienced by individuals in movements such as running, which is clinically applicable to identify athletes at risk for stress-related injuries. Our aim in this paper is to determine if data collected with inertial measurement units (IMUs), that can be worn by athletes during outdoor runs, can be used to predict GRF with sufficient accuracy to allow the analysis of its derived biomechanical variables (e.g., contact time and loading rate). In this paper, we consider lightweight approaches in contrast to state-of-the-art prediction using LSTM neural networks. Specifically, we compare use of LSTMs to k-Nearest Neighbors (KNN) regression as well as propose a novel solution, SVD Embedding Regression (SER), using linear regression between singular value decomposition embeddings of IMUs data (input) and GRF data (output). We evaluate the accuracy of these techniques when using training data collected from different athletes, from the same athlete, or both, and we explore the use of acceleration and angular velocity data from sensors at different locations (sacrum and shanks). Our results illustrate that simple machine learning methods such as SER and KNN can be similarly accurate or more accurate than LSTM neural networks, with much faster training times and hyperparameter optimization; in particular, SER and KNN are more accurate when personal training data are available, and KNN comes with benefit of providing provenance of prediction. Notably, the use of personal data reduces prediction errors of all methods for most biomechanical variables.
Queue Scheduling with Adversarial Bandit Learning
Mar 03, 2023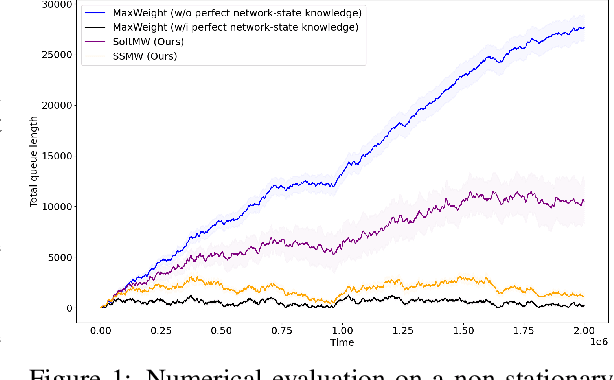

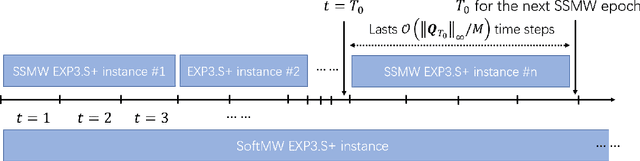
In this paper, we study scheduling of a queueing system with zero knowledge of instantaneous network conditions. We consider a one-hop single-server queueing system consisting of $K$ queues, each with time-varying and non-stationary arrival and service rates. Our scheduling approach builds on an innovative combination of adversarial bandit learning and Lyapunov drift minimization, without knowledge of the instantaneous network state (the arrival and service rates) of each queue. We then present two novel algorithms \texttt{SoftMW} (SoftMaxWeight) and \texttt{SSMW} (Sliding-window SoftMaxWeight), both capable of stabilizing systems that can be stablized by some (possibly unknown) sequence of randomized policies whose time-variation satisfies a mild condition. We further generalize our results to the setting where arrivals and departures only have bounded moments instead of being deterministically bounded and propose \texttt{SoftMW+} and \texttt{SSMW+} that are capable of stabilizing the system. As a building block of our new algorithms, we also extend the classical \texttt{EXP3.S} (Auer et al., 2002) algorithm for multi-armed bandits to handle unboundedly large feedback signals, which can be of independent interest.
Inference Latency Prediction at the Edge
Oct 06, 2022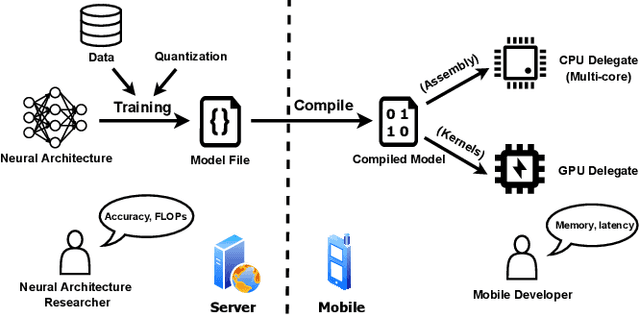
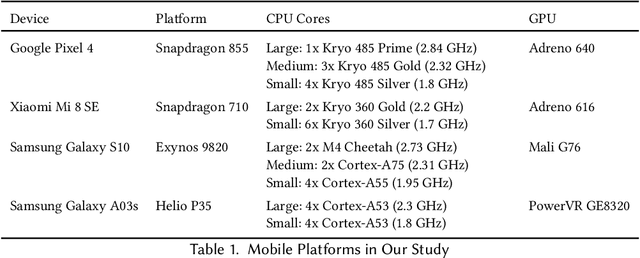
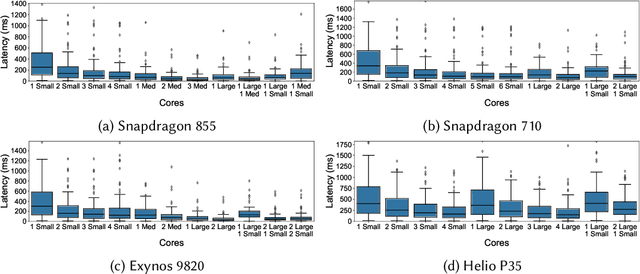
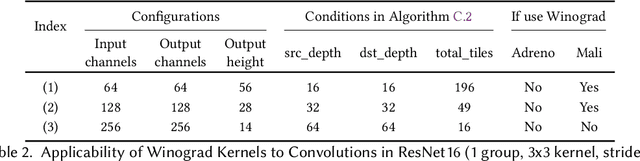
With the growing workload of inference tasks on mobile devices, state-of-the-art neural architectures (NAs) are typically designed through Neural Architecture Search (NAS) to identify NAs with good tradeoffs between accuracy and efficiency (e.g., latency). Since measuring the latency of a huge set of candidate architectures during NAS is not scalable, approaches are needed for predicting end-to-end inference latency on mobile devices. Such predictions are challenging due to hardware heterogeneity, optimizations applied by ML frameworks, and the diversity of neural architectures. Motivated by these challenges, in this paper, we first quantitatively assess characteristics of neural architectures and mobile devices that have significant effects on inference latency. Based on this assessment, we propose a latency prediction framework which addresses these challenges by developing operation-wise latency predictors, under a variety of settings and a number of hardware devices, with multi-core CPUs and GPUs, achieving high accuracy in end-to-end latency prediction, as shown by our comprehensive evaluations. To illustrate that our approach does not require expensive data collection, we also show that accurate predictions can be achieved on real-world NAs using only small amounts of profiling data.
Achieving Transparency Report Privacy in Linear Time
Apr 15, 2021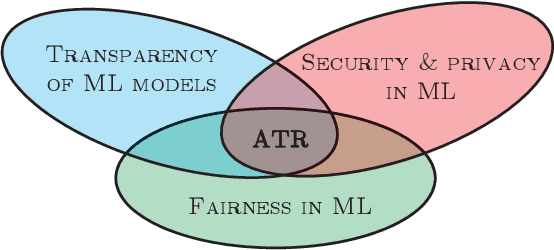
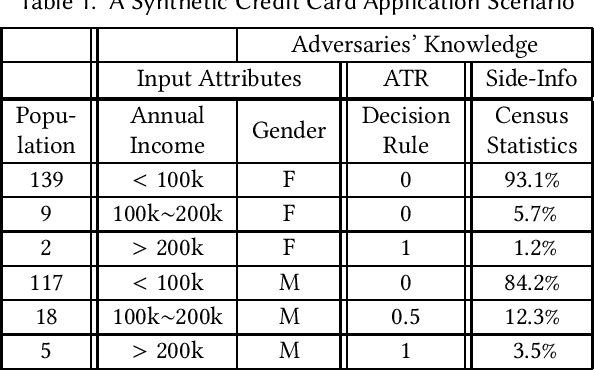

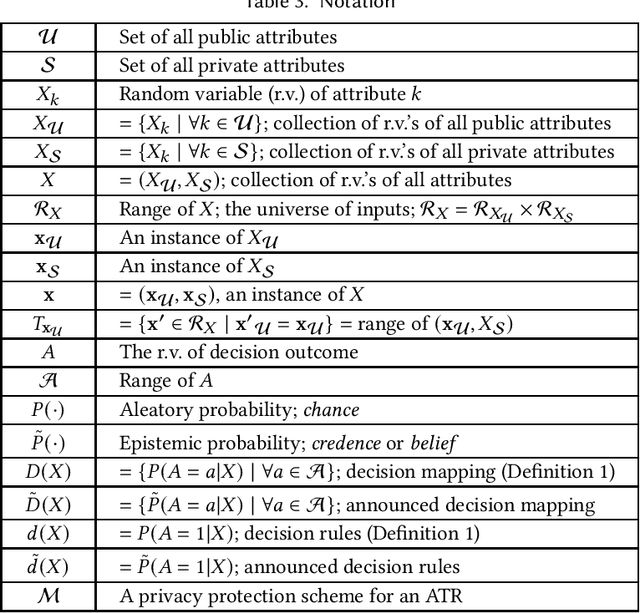
An accountable algorithmic transparency report (ATR) should ideally investigate the (a) transparency of the underlying algorithm, and (b) fairness of the algorithmic decisions, and at the same time preserve data subjects' privacy. However, a provably formal study of the impact to data subjects' privacy caused by the utility of releasing an ATR (that investigates transparency and fairness), is yet to be addressed in the literature. The far-fetched benefit of such a study lies in the methodical characterization of privacy-utility trade-offs for release of ATRs in public, and their consequential application-specific impact on the dimensions of society, politics, and economics. In this paper, we first investigate and demonstrate potential privacy hazards brought on by the deployment of transparency and fairness measures in released ATRs. To preserve data subjects' privacy, we then propose a linear-time optimal-privacy scheme, built upon standard linear fractional programming (LFP) theory, for announcing ATRs, subject to constraints controlling the tolerance of privacy perturbation on the utility of transparency schemes. Subsequently, we quantify the privacy-utility trade-offs induced by our scheme, and analyze the impact of privacy perturbation on fairness measures in ATRs. To the best of our knowledge, this is the first analytical work that simultaneously addresses trade-offs between the triad of privacy, utility, and fairness, applicable to algorithmic transparency reports.
Backdoor Attacks on Federated Meta-Learning
Jun 12, 2020

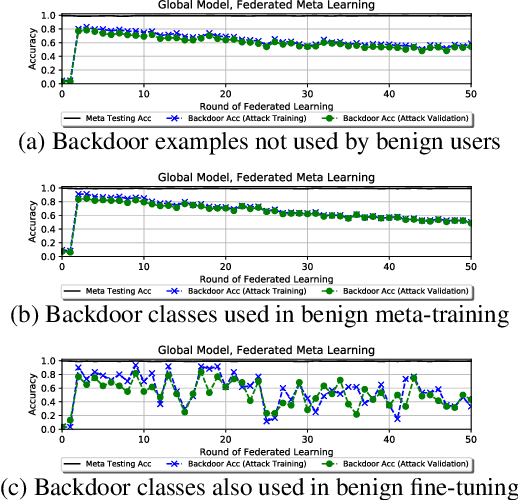
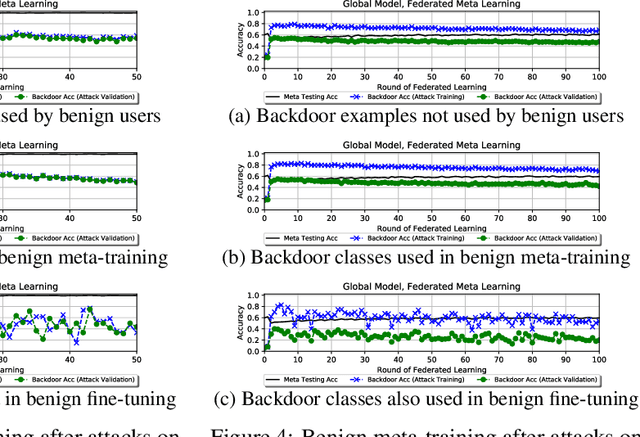
Federated learning allows multiple users to collaboratively train a shared classification model while preserving data privacy. This approach, where model updates are aggregated by a central server, was shown to be vulnerable to backdoor attacks: a malicious user can alter the shared model to arbitrarily classify specific inputs from a given class. In this paper, we analyze the effects of backdoor attacks in federated meta-learning, where users train a model that can be adapted to different sets of output classes using only a few training examples. While the ability to adapt could, in principle, make federated learning more robust to backdoor attacks when new training examples are benign, we find that even 1-shot poisoning attacks can be very successful and persist after additional training. To address these vulnerabilities, we propose a defense mechanism inspired by matching networks, where the class of an input is predicted from the cosine similarity of its features with a support set of labeled examples. By removing the decision logic from the model shared with the federation, success and persistence of backdoor attacks are greatly reduced.
Throughput Prediction of Asynchronous SGD in TensorFlow
Nov 12, 2019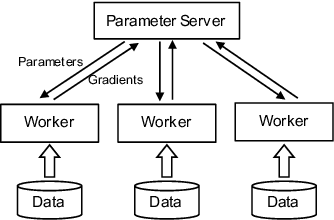

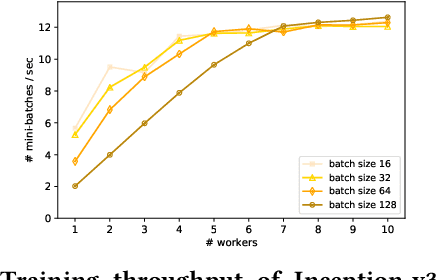
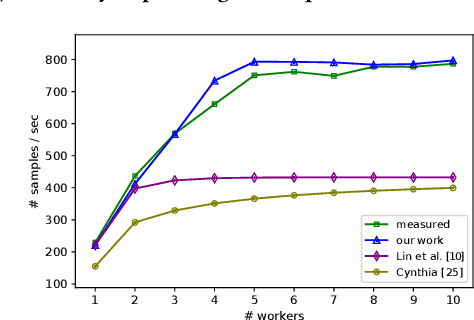
Modern machine learning frameworks can train neural networks using multiple nodes in parallel, each computing parameter updates with stochastic gradient descent (SGD) and sharing them asynchronously through a central parameter server. Due to communication overhead and bottlenecks, the total throughput of SGD updates in a cluster scales sublinearly, saturating as the the number of nodes increases. In this paper, we present a solution to predicting training throughput from profiling traces collected from a single-node configuration. Our approach is able to model the interaction of multiple nodes and the scheduling of concurrent transmissions between the parameter server and each node. By accounting for the dependencies between received parts and pending computations, we predict overlaps between computation and communication and generate synthetic execution traces for configurations with multiple nodes. We validate our approach on TensorFlow training jobs for popular image classification neural networks, on AWS and on our in-house cluster, using nodes equipped with GPUs or only with CPUs. We also investigate the effects of data transmission policies used in TensorFlow and the accuracy of our approach when combined with optimizations of the transmission schedule.