 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThroughput Prediction of Asynchronous SGD in TensorFlow
Paper and Code
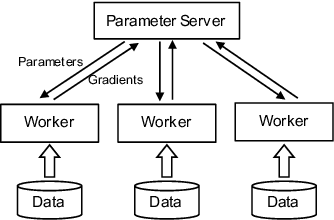

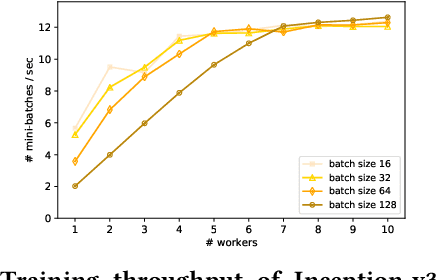
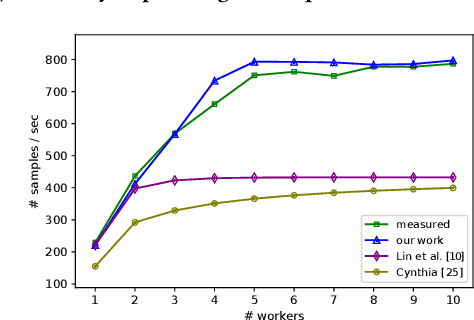
Modern machine learning frameworks can train neural networks using multiple nodes in parallel, each computing parameter updates with stochastic gradient descent (SGD) and sharing them asynchronously through a central parameter server. Due to communication overhead and bottlenecks, the total throughput of SGD updates in a cluster scales sublinearly, saturating as the the number of nodes increases. In this paper, we present a solution to predicting training throughput from profiling traces collected from a single-node configuration. Our approach is able to model the interaction of multiple nodes and the scheduling of concurrent transmissions between the parameter server and each node. By accounting for the dependencies between received parts and pending computations, we predict overlaps between computation and communication and generate synthetic execution traces for configurations with multiple nodes. We validate our approach on TensorFlow training jobs for popular image classification neural networks, on AWS and on our in-house cluster, using nodes equipped with GPUs or only with CPUs. We also investigate the effects of data transmission policies used in TensorFlow and the accuracy of our approach when combined with optimizations of the transmission schedule.