 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Transparency Report Privacy in Linear Time
Apr 15, 2021
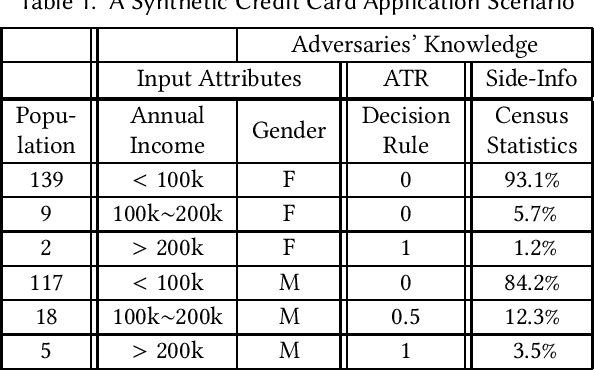

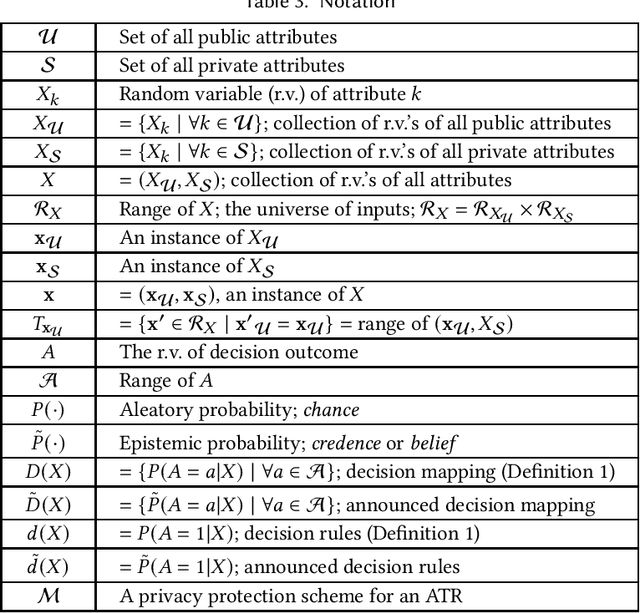
An accountable algorithmic transparency report (ATR) should ideally investigate the (a) transparency of the underlying algorithm, and (b) fairness of the algorithmic decisions, and at the same time preserve data subjects' privacy. However, a provably formal study of the impact to data subjects' privacy caused by the utility of releasing an ATR (that investigates transparency and fairness), is yet to be addressed in the literature. The far-fetched benefit of such a study lies in the methodical characterization of privacy-utility trade-offs for release of ATRs in public, and their consequential application-specific impact on the dimensions of society, politics, and economics. In this paper, we first investigate and demonstrate potential privacy hazards brought on by the deployment of transparency and fairness measures in released ATRs. To preserve data subjects' privacy, we then propose a linear-time optimal-privacy scheme, built upon standard linear fractional programming (LFP) theory, for announcing ATRs, subject to constraints controlling the tolerance of privacy perturbation on the utility of transparency schemes. Subsequently, we quantify the privacy-utility trade-offs induced by our scheme, and analyze the impact of privacy perturbation on fairness measures in ATRs. To the best of our knowledge, this is the first analytical work that simultaneously addresses trade-offs between the triad of privacy, utility, and fairness, applicable to algorithmic transparency reports.
Backdoor Attacks on Federated Meta-Learning
Jun 12, 2020

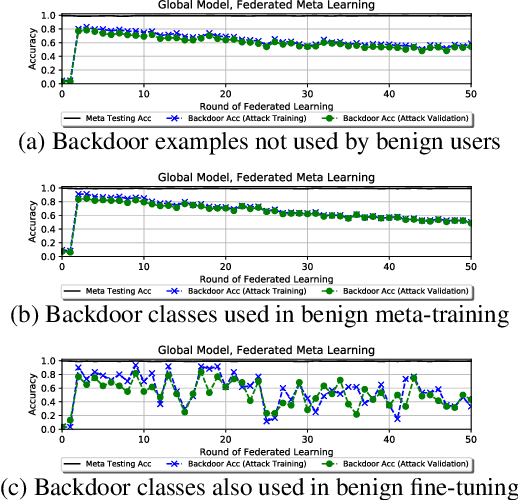
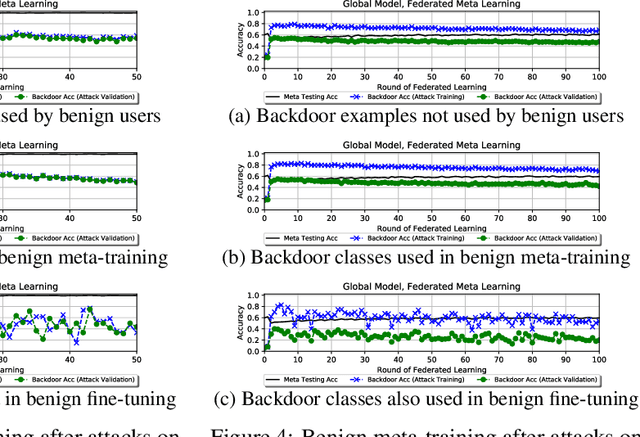
Federated learning allows multiple users to collaboratively train a shared classification model while preserving data privacy. This approach, where model updates are aggregated by a central server, was shown to be vulnerable to backdoor attacks: a malicious user can alter the shared model to arbitrarily classify specific inputs from a given class. In this paper, we analyze the effects of backdoor attacks in federated meta-learning, where users train a model that can be adapted to different sets of output classes using only a few training examples. While the ability to adapt could, in principle, make federated learning more robust to backdoor attacks when new training examples are benign, we find that even 1-shot poisoning attacks can be very successful and persist after additional training. To address these vulnerabilities, we propose a defense mechanism inspired by matching networks, where the class of an input is predicted from the cosine similarity of its features with a support set of labeled examples. By removing the decision logic from the model shared with the federation, success and persistence of backdoor attacks are greatly reduced.