 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks on Federated Meta-Learning
Paper and Code
Jun 12, 2020

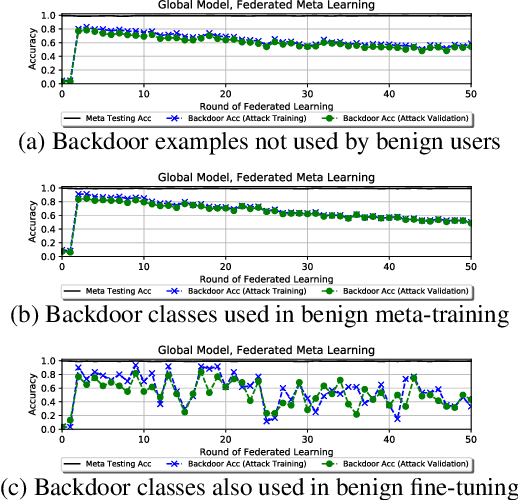
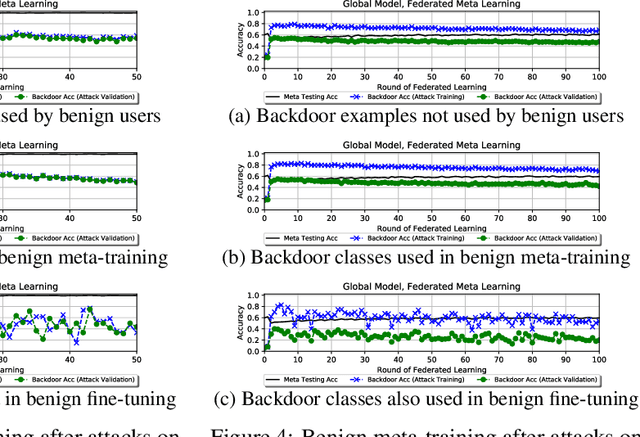
Federated learning allows multiple users to collaboratively train a shared classification model while preserving data privacy. This approach, where model updates are aggregated by a central server, was shown to be vulnerable to backdoor attacks: a malicious user can alter the shared model to arbitrarily classify specific inputs from a given class. In this paper, we analyze the effects of backdoor attacks in federated meta-learning, where users train a model that can be adapted to different sets of output classes using only a few training examples. While the ability to adapt could, in principle, make federated learning more robust to backdoor attacks when new training examples are benign, we find that even 1-shot poisoning attacks can be very successful and persist after additional training. To address these vulnerabilities, we propose a defense mechanism inspired by matching networks, where the class of an input is predicted from the cosine similarity of its features with a support set of labeled examples. By removing the decision logic from the model shared with the federation, success and persistence of backdoor attacks are greatly reduced.