 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubZero: Composing Subject, Style, and Action via Zero-Shot Personalization
Feb 27, 2025Diffusion models are increasingly popular for generative tasks, including personalized composition of subjects and styles. While diffusion models can generate user-specified subjects performing text-guided actions in custom styles, they require fine-tuning and are not feasible for personalization on mobile devices. Hence, tuning-free personalization methods such as IP-Adapters have progressively gained traction. However, for the composition of subjects and styles, these works are less flexible due to their reliance on ControlNet, or show content and style leakage artifacts. To tackle these, we present SubZero, a novel framework to generate any subject in any style, performing any action without the need for fine-tuning. We propose a novel set of constraints to enhance subject and style similarity, while reducing leakage. Additionally, we propose an orthogonalized temporal aggregation scheme in the cross-attention blocks of denoising model, effectively conditioning on a text prompt along with single subject and style images. We also propose a novel method to train customized content and style projectors to reduce content and style leakage. Through extensive experiments, we show that our proposed approach, while suitable for running on-edge, shows significant improvements over state-of-the-art works performing subject, style and action composition.
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


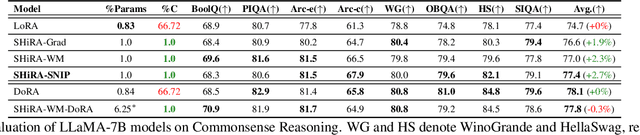
In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
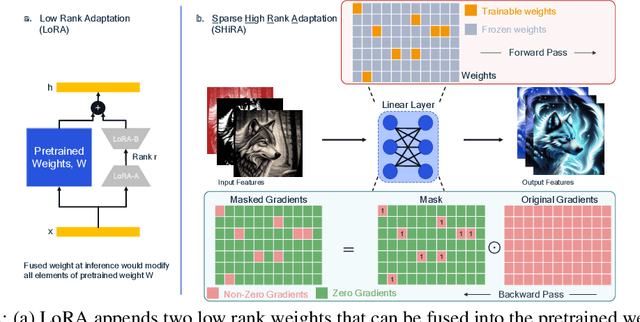
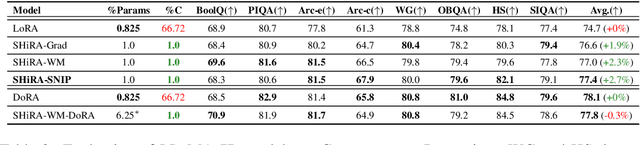
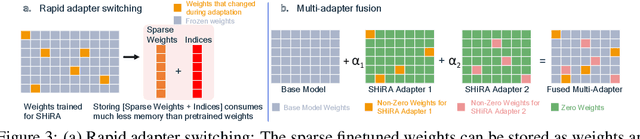
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
Oh! We Freeze: Improving Quantized Knowledge Distillation via Signal Propagation Analysis for Large Language Models
Mar 28, 2024Large generative models such as large language models (LLMs) and diffusion models have revolutionized the fields of NLP and computer vision respectively. However, their slow inference, high computation and memory requirement makes it challenging to deploy them on edge devices. In this study, we propose a light-weight quantization aware fine tuning technique using knowledge distillation (KD-QAT) to improve the performance of 4-bit weight quantized LLMs using commonly available datasets to realize a popular language use case, on device chat applications. To improve this paradigm of finetuning, as main contributions, we provide insights into stability of KD-QAT by empirically studying the gradient propagation during training to better understand the vulnerabilities of KD-QAT based approaches to low-bit quantization errors. Based on our insights, we propose ov-freeze, a simple technique to stabilize the KD-QAT process. Finally, we experiment with the popular 7B LLaMAv2-Chat model at 4-bit quantization level and demonstrate that ov-freeze results in near floating point precision performance, i.e., less than 0.7% loss of accuracy on Commonsense Reasoning benchmarks.
Moccasin: Efficient Tensor Rematerialization for Neural Networks
Apr 27, 2023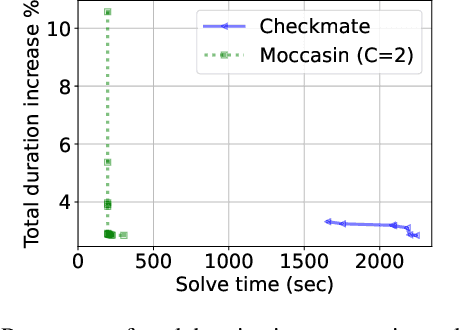

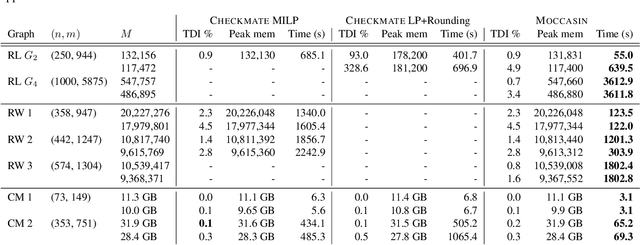
The deployment and training of neural networks on edge computing devices pose many challenges. The low memory nature of edge devices is often one of the biggest limiting factors encountered in the deployment of large neural network models. Tensor rematerialization or recompute is a way to address high memory requirements for neural network training and inference. In this paper we consider the problem of execution time minimization of compute graphs subject to a memory budget. In particular, we develop a new constraint programming formulation called \textsc{Moccasin} with only $O(n)$ integer variables, where $n$ is the number of nodes in the compute graph. This is a significant improvement over the works in the recent literature that propose formulations with $O(n^2)$ Boolean variables. We present numerical studies that show that our approach is up to an order of magnitude faster than recent work especially for large-scale graphs.
Neural Topological Ordering for Computation Graphs
Jul 13, 2022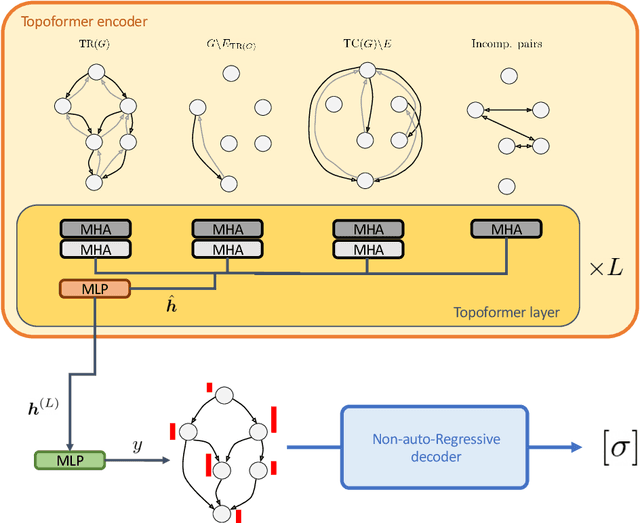
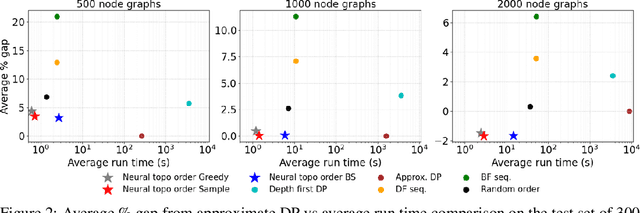
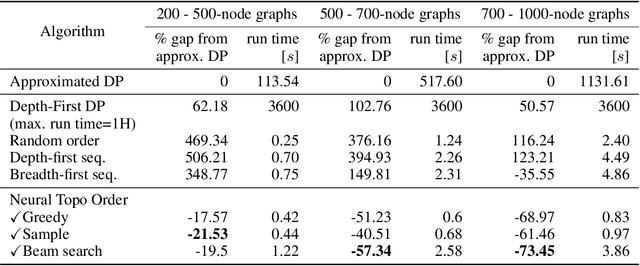
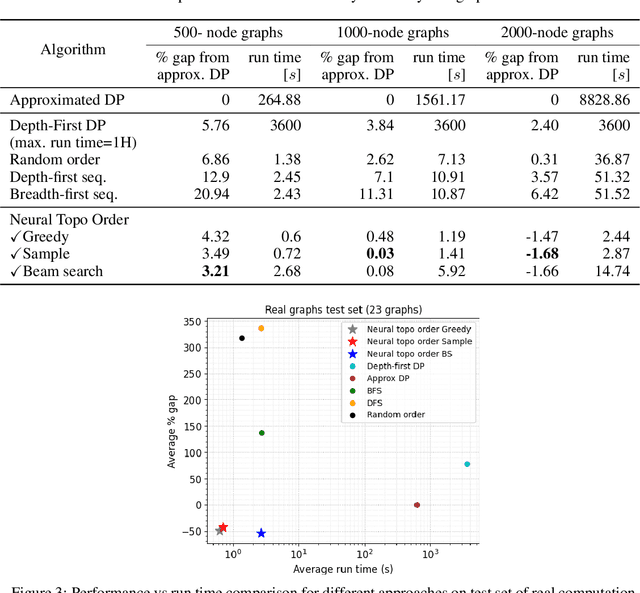
Recent works on machine learning for combinatorial optimization have shown that learning based approaches can outperform heuristic methods in terms of speed and performance. In this paper, we consider the problem of finding an optimal topological order on a directed acyclic graph with focus on the memory minimization problem which arises in compilers. We propose an end-to-end machine learning based approach for topological ordering using an encoder-decoder framework. Our encoder is a novel attention based graph neural network architecture called \emph{Topoformer} which uses different topological transforms of a DAG for message passing. The node embeddings produced by the encoder are converted into node priorities which are used by the decoder to generate a probability distribution over topological orders. We train our model on a dataset of synthetically generated graphs called layered graphs. We show that our model outperforms, or is on-par, with several topological ordering baselines while being significantly faster on synthetic graphs with up to 2k nodes. We also train and test our model on a set of real-world computation graphs, showing performance improvements.
SwiftNet: Using Graph Propagation as Meta-knowledge to Search Highly Representative Neural Architectures
Jun 25, 2019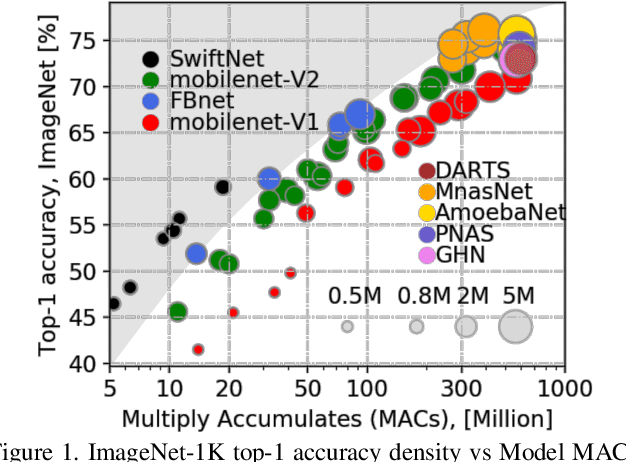
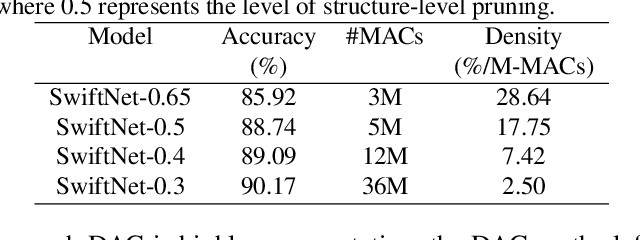
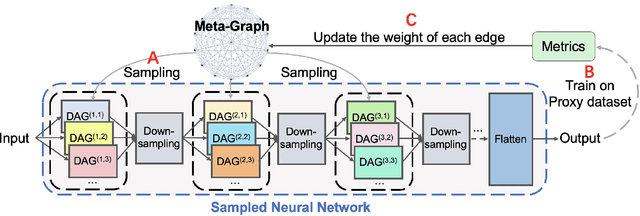

Designing neural architectures for edge devices is subject to constraints of accuracy, inference latency, and computational cost. Traditionally, researchers manually craft deep neural networks to meet the needs of mobile devices. Neural Architecture Search (NAS) was proposed to automate the neural architecture design without requiring extensive domain expertise and significant manual efforts. Recent works utilized NAS to design mobile models by taking into account hardware constraints and achieved state-of-the-art accuracy with fewer parameters and less computational cost measured in Multiply-accumulates (MACs). To find highly compact neural architectures, existing works relies on predefined cells and directly applying width multiplier, which may potentially limit the model flexibility, reduce the useful feature map information, and cause accuracy drop. To conquer this issue, we propose GRAM(GRAph propagation as Meta-knowledge) that adopts fine-grained (node-wise) search method and accumulates the knowledge learned in updates into a meta-graph. As a result, GRAM can enable more flexible search space and achieve higher search efficiency. Without the constraints of predefined cell or blocks, we propose a new structure-level pruning method to remove redundant operations in neural architectures. SwiftNet, which is a set of models discovered by GRAM, outperforms MobileNet-V2 by 2.15x higher accuracy density and 2.42x faster with similar accuracy. Compared with FBNet, SwiftNet reduces the search cost by 26x and achieves 2.35x higher accuracy density and 1.47x speedup while preserving similar accuracy. SwiftNetcan obtain 63.28% top-1 accuracy on ImageNet-1K with only 53M MACs and 2.07M parameters. The corresponding inference latency is only 19.09 ms on Google Pixel 1.
Comparison of Attitude Estimation Techniques for Low-cost Unmanned Aerial Vehicles
Feb 24, 2016
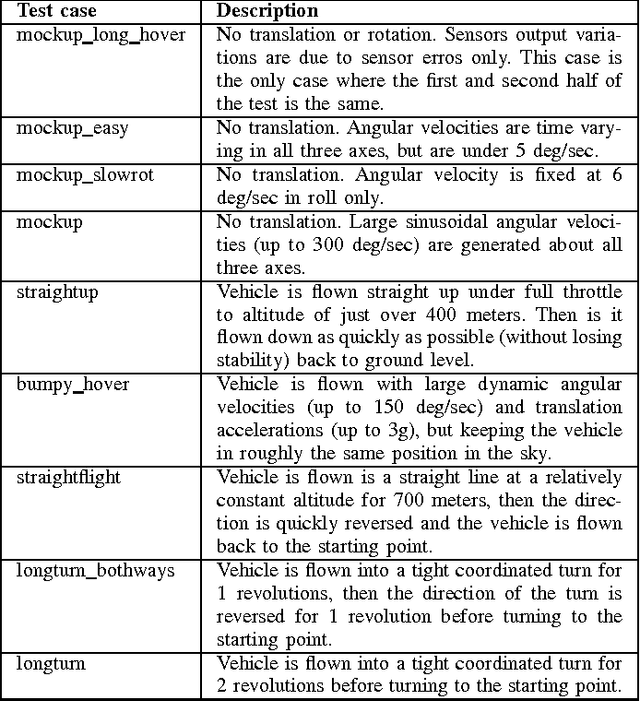
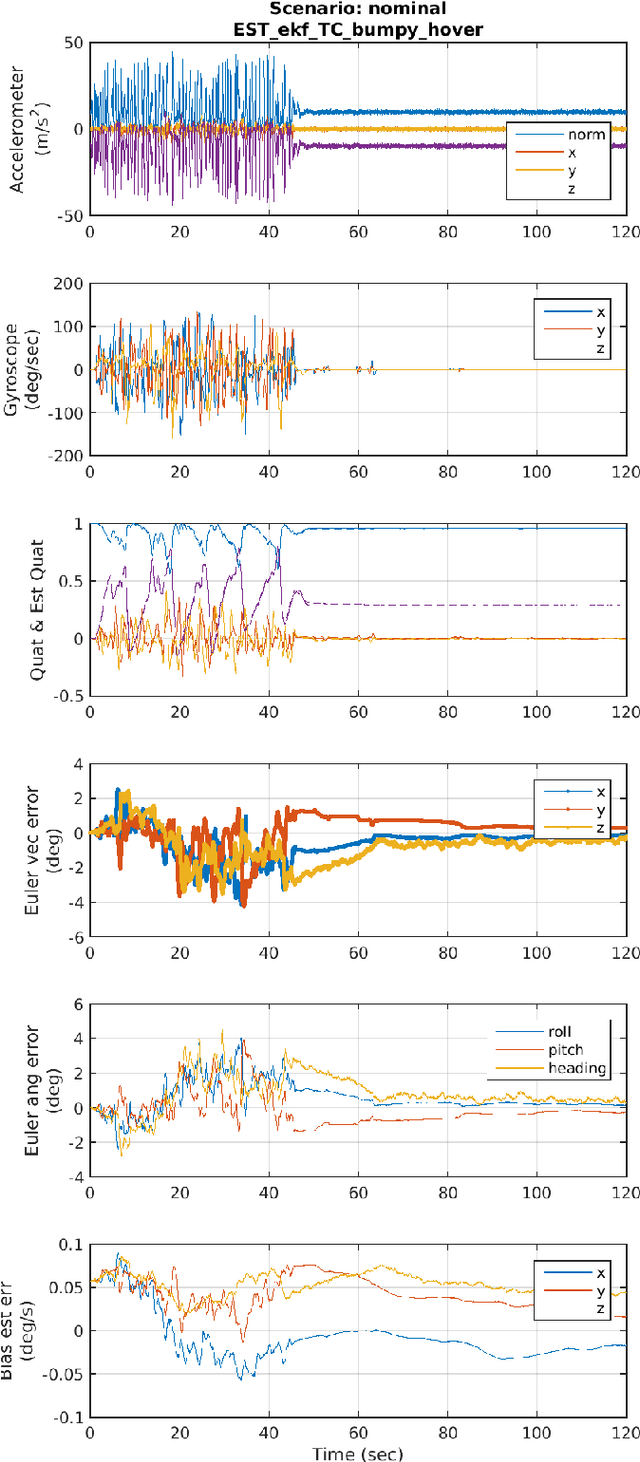
Attitude estimation for small, low-cost unmanned aerial vehicles is often achieved using a relatively simple complementary filter that combines onboard accelerometers, gyroscopes, and magnetometer sensing. This paper explores the limits of performance of such attitude estimation, with a focus on performance in highly dynamic maneuvers. The complementary filter is derived along with the extended Kalman filter and unscented Kalman filter to evaluate the potential performance gains when using a more sophisticated estimator. Simulations are presented that compare performance across a range of test cases, many where ground truth was generated from manually controlled flights in a flight simulator. Estimator scenarios that are generic across the different estimator types (such as the way sensor information is processed, and the use of dynamically changing gains) are compared across the test cases. An appendix is included as a quick reference for the common attitude representations and their kinematic expressions.