 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated Deep Segmentation and Spatial-Statistics Approach for Post-Blast Rock Fragmentation Assessment
Jul 27, 2025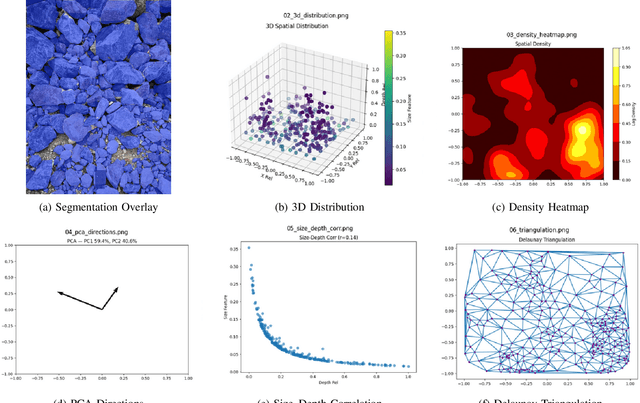
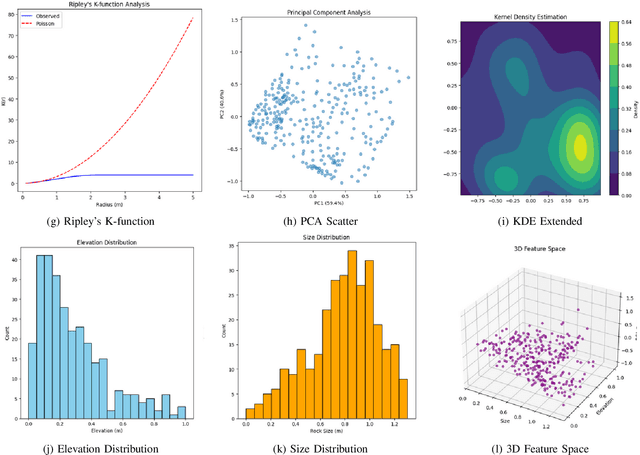
We introduce an end-to-end pipeline that leverages a fine-tuned YOLO12l-seg model -- trained on over 500 annotated post-blast images -- to deliver real-time instance segmentation (Box mAP@0.5 ~ 0.769, Mask mAP@0.5 ~ 0.800 at ~ 15 FPS). High-fidelity masks are converted into normalized 3D coordinates, from which we extract multi-metric spatial descriptors: principal component directions, kernel density hotspots, size-depth regression, and Delaunay edge statistics. We present four representative examples to illustrate key fragmentation patterns. Experimental results confirm the framework's accuracy, robustness to small-object crowding, and feasibility for rapid, automated blast-effect assessment in field conditions.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Coordinated Sparse Recovery of Label Noise
Apr 07, 2024Label noise is a common issue in real-world datasets that inevitably impacts the generalization of models. This study focuses on robust classification tasks where the label noise is instance-dependent. Estimating the transition matrix accurately in this task is challenging, and methods based on sample selection often exhibit confirmation bias to varying degrees. Sparse over-parameterized training (SOP) has been theoretically effective in estimating and recovering label noise, offering a novel solution for noise-label learning. However, this study empirically observes and verifies a technical flaw of SOP: the lack of coordination between model predictions and noise recovery leads to increased generalization error. To address this, we propose a method called Coordinated Sparse Recovery (CSR). CSR introduces a collaboration matrix and confidence weights to coordinate model predictions and noise recovery, reducing error leakage. Based on CSR, this study designs a joint sample selection strategy and constructs a comprehensive and powerful learning framework called CSR+. CSR+ significantly reduces confirmation bias, especially for datasets with more classes and a high proportion of instance-specific noise. Experimental results on simulated and real-world noisy datasets demonstrate that both CSR and CSR+ achieve outstanding performance compared to methods at the same level.
A theory for the sparsity emerged in the Forward Forward algorithm
Nov 09, 2023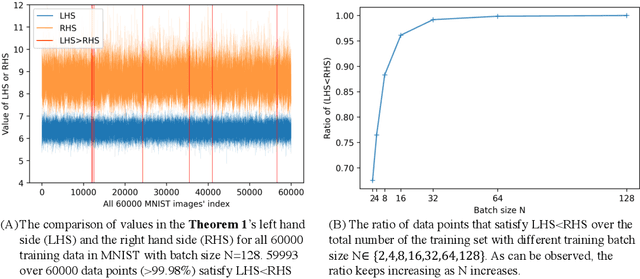
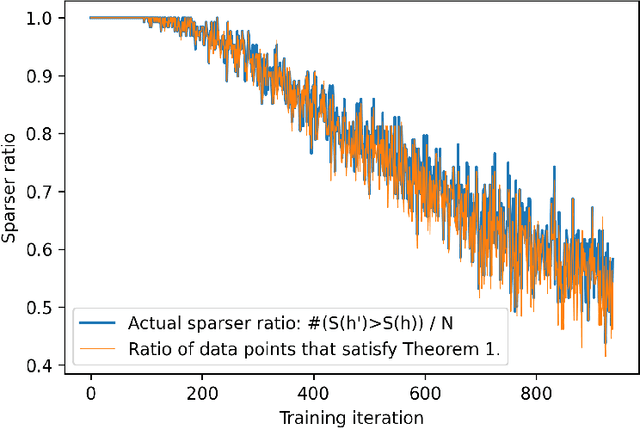
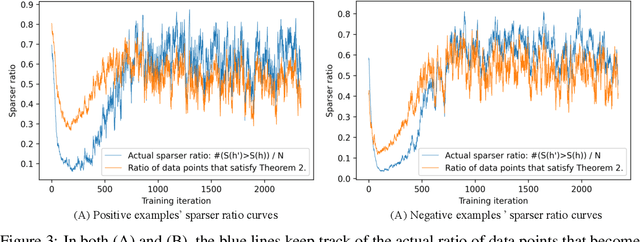
This report explores the theory that explains the high sparsity phenomenon \citep{tosato2023emergent} observed in the forward-forward algorithm \citep{hinton2022forward}. The two theorems proposed predict the sparsity changes of a single data point's activation in two cases: Theorem \ref{theorem:1}: Decrease the goodness of the whole batch. Theorem \ref{theorem:2}: Apply the complete forward forward algorithm to decrease the goodness for negative data and increase the goodness for positive data. The theory aligns well with the experiments tested on the MNIST dataset.
Synaptic Dynamics Realize First-order Adaptive Learning and Weight Symmetry
Dec 01, 2022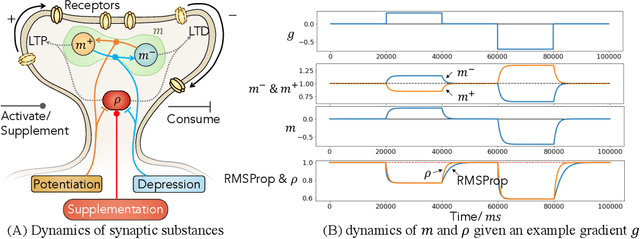
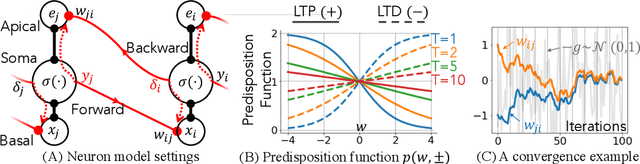
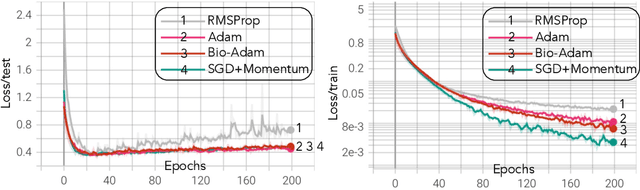
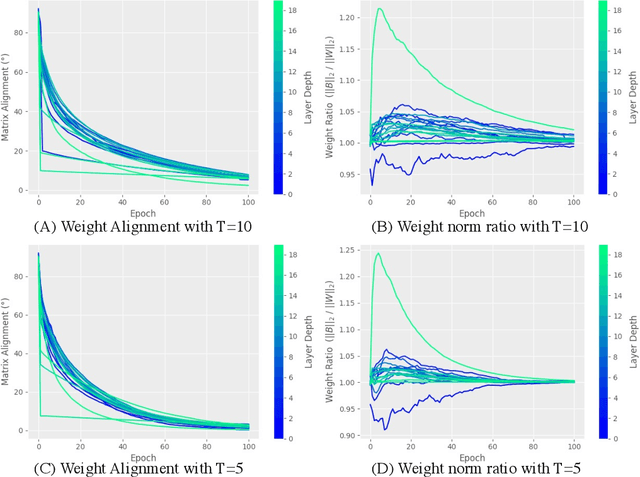
Gradient-based first-order adaptive optimization methods such as the Adam optimizer are prevalent in training artificial networks, achieving the state-of-the-art results. This work attempts to answer the question whether it is viable for biological neural systems to adopt such optimization methods. To this end, we demonstrate a realization of the Adam optimizer using biologically-plausible mechanisms in synapses. The proposed learning rule has clear biological correspondence, runs continuously in time, and achieves performance to comparable Adam's. In addition, we present a new approach, inspired by the predisposition property of synapses observed in neuroscience, to circumvent the biological implausibility of the weight transport problem in backpropagation (BP). With only local information and no separate training phases, this method establishes and maintains weight symmetry in the forward and backward signaling paths, and is applicable to the proposed biologically plausible Adam learning rule. These mechanisms may shed light on the way in which biological synaptic dynamics facilitate learning.
A Computational Framework of Cortical Microcircuits Approximates Sign-concordant Random Backpropagation
May 19, 2022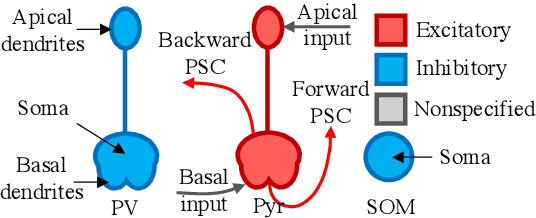
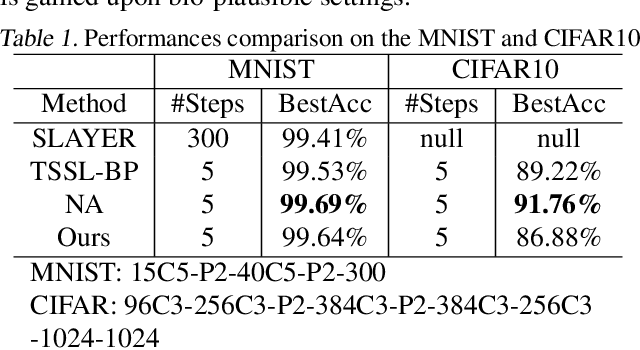
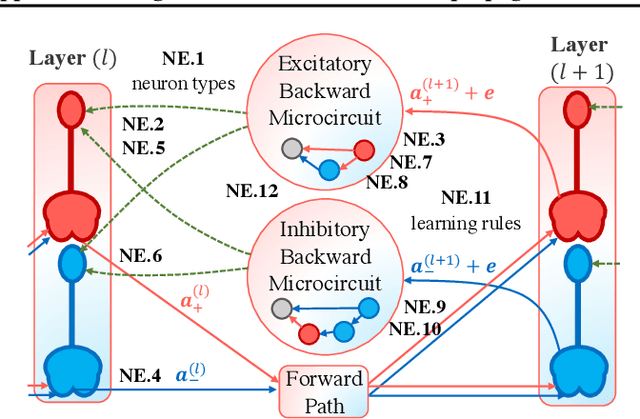
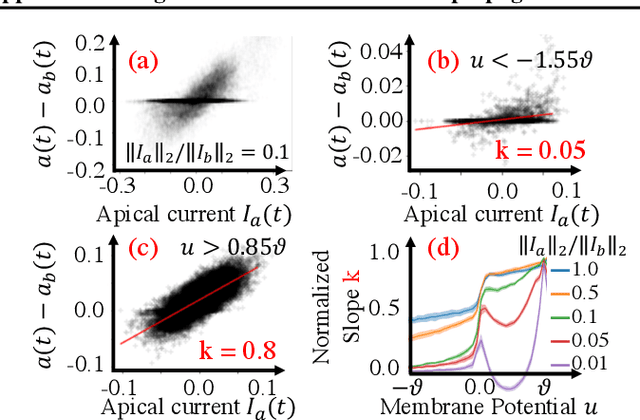
Several recent studies attempt to address the biological implausibility of the well-known backpropagation (BP) method. While promising methods such as feedback alignment, direct feedback alignment, and their variants like sign-concordant feedback alignment tackle BP's weight transport problem, their validity remains controversial owing to a set of other unsolved issues. In this work, we answer the question of whether it is possible to realize random backpropagation solely based on mechanisms observed in neuroscience. We propose a hypothetical framework consisting of a new microcircuit architecture and its supporting Hebbian learning rules. Comprising three types of cells and two types of synaptic connectivity, the proposed microcircuit architecture computes and propagates error signals through local feedback connections and supports the training of multi-layered spiking neural networks with a globally defined spiking error function. We employ the Hebbian rule operating in local compartments to update synaptic weights and achieve supervised learning in a biologically plausible manner. Finally, we interpret the proposed framework from an optimization point of view and show its equivalence to sign-concordant feedback alignment. The proposed framework is benchmarked on several datasets including MNIST and CIFAR10, demonstrating promising BP-comparable accuracy.
Agreement or Disagreement in Noise-tolerant Mutual Learning?
Mar 29, 2022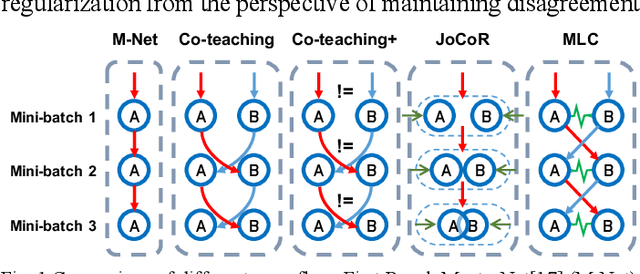
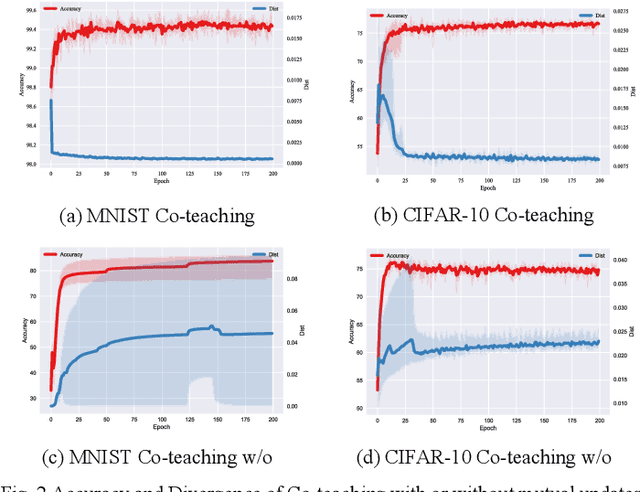
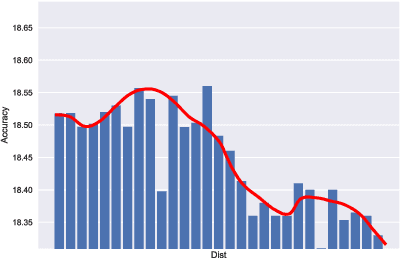
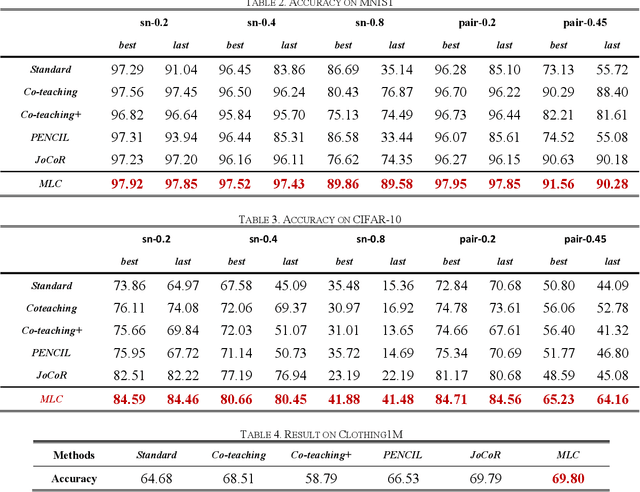
Deep learning has made many remarkable achievements in many fields but suffers from noisy labels in datasets. The state-of-the-art learning with noisy label method Co-teaching and Co-teaching+ confronts the noisy label by mutual-information between dual-network. However, the dual network always tends to convergent which would weaken the dual-network mechanism to resist the noisy labels. In this paper, we proposed a noise-tolerant framework named MLC in an end-to-end manner. It adjusts the dual-network with divergent regularization to ensure the effectiveness of the mechanism. In addition, we correct the label distribution according to the agreement between dual-networks. The proposed method can utilize the noisy data to improve the accuracy, generalization, and robustness of the network. We test the proposed method on the simulate noisy dataset MNIST, CIFAR-10, and the real-world noisy dataset Clothing1M. The experimental result shows that our method outperforms the previous state-of-the-art method. Besides, our method is network-free thus it is applicable to many tasks.
BioLeaF: A Bio-plausible Learning Framework for Training of Spiking Neural Networks
Nov 14, 2021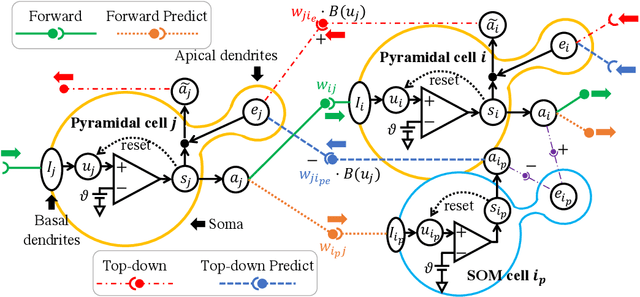
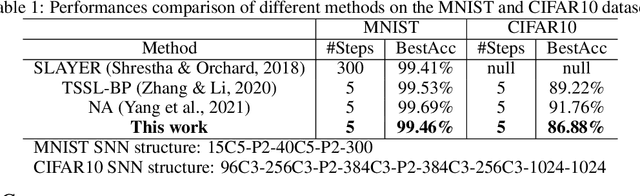
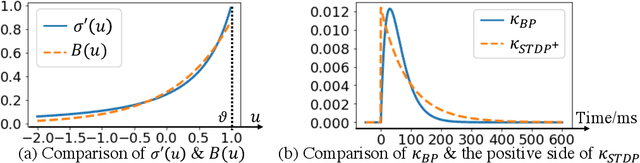
Our brain consists of biological neurons encoding information through accurate spike timing, yet both the architecture and learning rules of our brain remain largely unknown. Comparing to the recent development of backpropagation-based (BP-based) methods that are able to train spiking neural networks (SNNs) with high accuracy, biologically plausible methods are still in their infancy. In this work, we wish to answer the question of whether it is possible to attain comparable accuracy of SNNs trained by BP-based rules with bio-plausible mechanisms. We propose a new bio-plausible learning framework, consisting of two components: a new architecture, and its supporting learning rules. With two types of cells and four types of synaptic connections, the proposed local microcircuit architecture can compute and propagate error signals through local feedback connections and support training of multi-layers SNNs with a globally defined spiking error function. Under our microcircuit architecture, we employ the Spike-Timing-Dependent-Plasticity (STDP) rule operating in local compartments to update synaptic weights and achieve supervised learning in a biologically plausible manner. Finally, We interpret the proposed framework from an optimization point of view and show the equivalence between it and the BP-based rules under a special circumstance. Our experiments show that the proposed framework demonstrates learning accuracy comparable to BP-based rules and may provide new insights on how learning is orchestrated in biological systems.
Backpropagated Neighborhood Aggregation for Accurate Training of Spiking Neural Networks
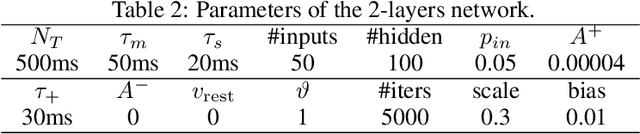
Jun 22, 2021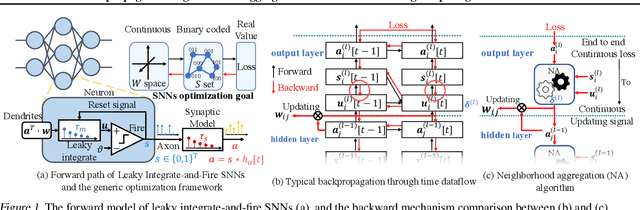

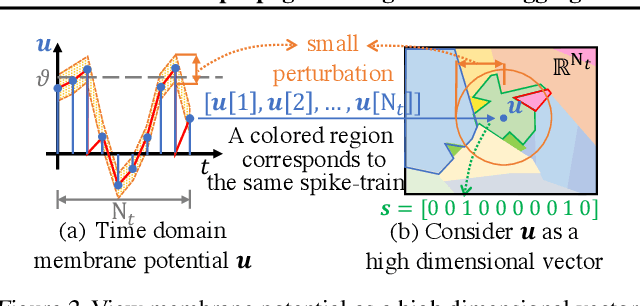
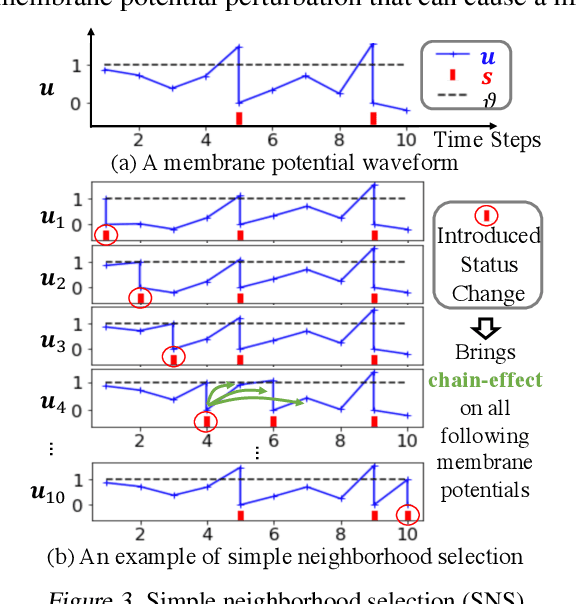
While backpropagation (BP) has been applied to spiking neural networks (SNNs) achieving encouraging results, a key challenge involved is to backpropagate a continuous-valued loss over layers of spiking neurons exhibiting discontinuous all-or-none firing activities. Existing methods deal with this difficulty by introducing compromises that come with their own limitations, leading to potential performance degradation. We propose a novel BP-like method, called neighborhood aggregation (NA), which computes accurate error gradients guiding weight updates that may lead to discontinuous modifications of firing activities. NA achieves this goal by aggregating finite differences of the loss over multiple perturbed membrane potential waveforms in the neighborhood of the present membrane potential of each neuron while utilizing a new membrane potential distance function. Our experiments show that the proposed NA algorithm delivers the state-of-the-art performance for SNN training on several datasets.
Temporal Surrogate Back-propagation for Spiking Neural Networks
Nov 18, 2020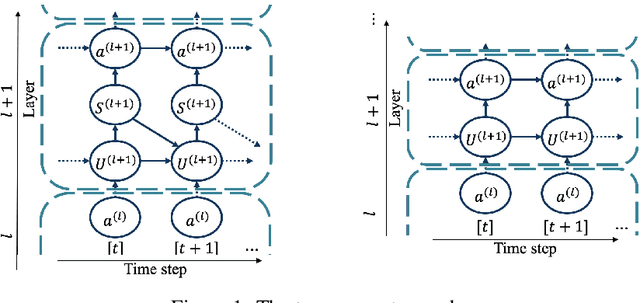

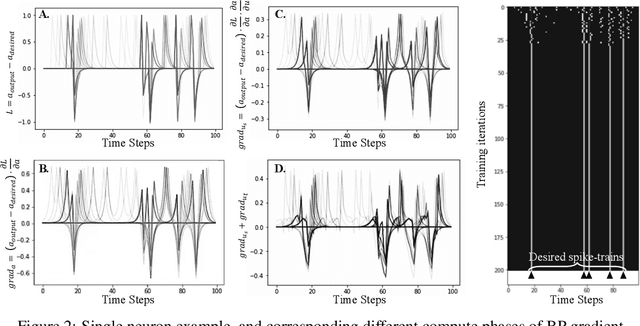
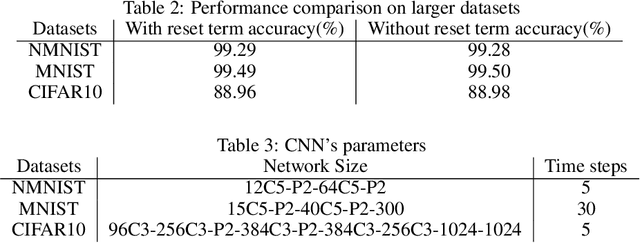
Spiking neural networks (SNN) are usually more energy-efficient as compared to Artificial neural networks (ANN), and the way they work has a great similarity with our brain. Back-propagation (BP) has shown its strong power in training ANN in recent years. However, since spike behavior is non-differentiable, BP cannot be applied to SNN directly. Although prior works demonstrated several ways to approximate the BP-gradient in both spatial and temporal directions either through surrogate gradient or randomness, they omitted the temporal dependency introduced by the reset mechanism between each step. In this article, we target on theoretical completion and investigate the effect of the missing term thoroughly. By adding the temporal dependency of the reset mechanism, the new algorithm is more robust to learning-rate adjustments on a toy dataset but does not show much improvement on larger learning tasks like CIFAR-10. Empirically speaking, the benefits of the missing term are not worth the additional computational overhead. In many cases, the missing term can be ignored.