 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTucker Bilinear Attention Network for Multi-scale Remote Sensing Object Detection
Mar 09, 2023Object detection on VHR remote sensing images plays a vital role in applications such as urban planning, land resource management, and rescue missions. The large-scale variation of the remote-sensing targets is one of the main challenges in VHR remote-sensing object detection. Existing methods improve the detection accuracy of high-resolution remote sensing objects by improving the structure of feature pyramids and adopting different attention modules. However, for small targets, there still be seriously missed detections due to the loss of key detail features. There is still room for improvement in the way of multiscale feature fusion and balance. To address this issue, this paper proposes two novel modules: Guided Attention and Tucker Bilinear Attention, which are applied to the stages of early fusion and late fusion respectively. The former can effectively retain clean key detail features, and the latter can better balance features through semantic-level correlation mining. Based on two modules, we build a new multi-scale remote sensing object detection framework. No bells and whistles. The proposed method largely improves the average precisions of small objects and achieves the highest mean average precisions compared with 9 state-of-the-art methods on DOTA, DIOR, and NWPU VHR-10.Code and models are available at https://github.com/Shinichict/GTNet.
Agreement or Disagreement in Noise-tolerant Mutual Learning?
Mar 29, 2022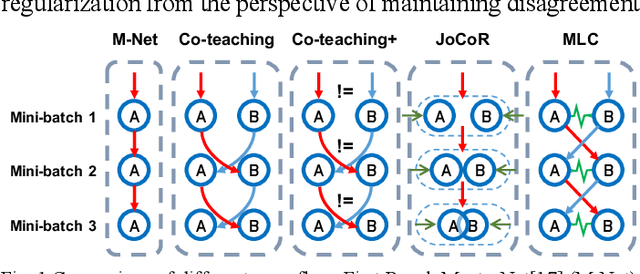
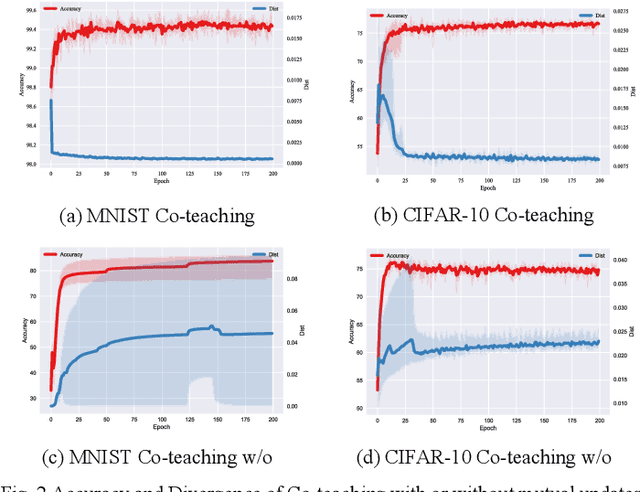
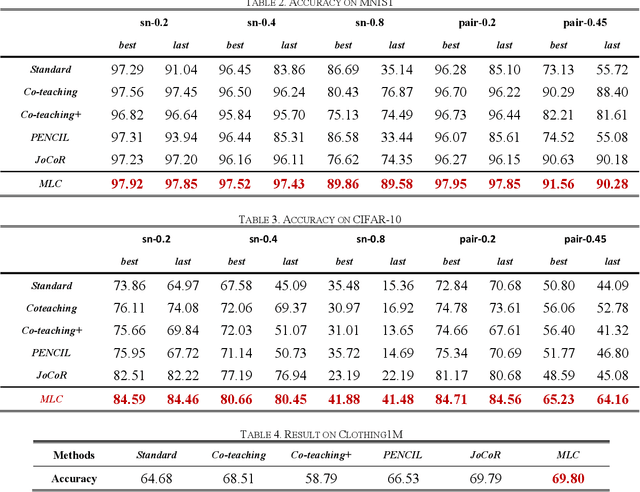
Deep learning has made many remarkable achievements in many fields but suffers from noisy labels in datasets. The state-of-the-art learning with noisy label method Co-teaching and Co-teaching+ confronts the noisy label by mutual-information between dual-network. However, the dual network always tends to convergent which would weaken the dual-network mechanism to resist the noisy labels. In this paper, we proposed a noise-tolerant framework named MLC in an end-to-end manner. It adjusts the dual-network with divergent regularization to ensure the effectiveness of the mechanism. In addition, we correct the label distribution according to the agreement between dual-networks. The proposed method can utilize the noisy data to improve the accuracy, generalization, and robustness of the network. We test the proposed method on the simulate noisy dataset MNIST, CIFAR-10, and the real-world noisy dataset Clothing1M. The experimental result shows that our method outperforms the previous state-of-the-art method. Besides, our method is network-free thus it is applicable to many tasks.
Swin transformers make strong contextual encoders for VHR image road extraction
Jan 10, 2022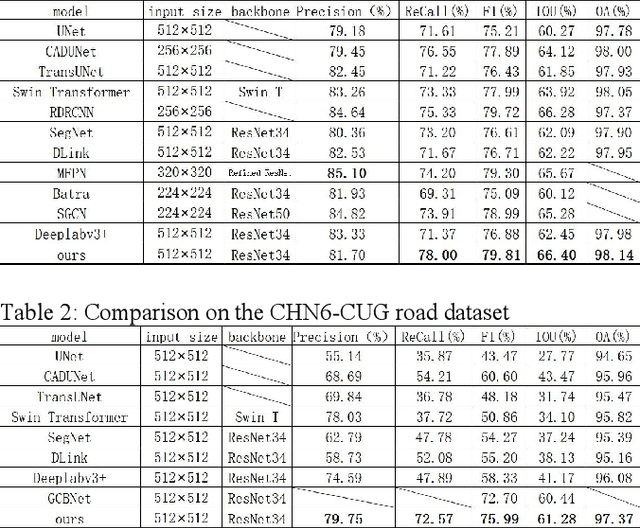

Significant progress has been made in automatic road extra-ction or segmentation based on deep learning, but there are still margins to improve in terms of the completeness and connectivity of the results. This is mainly due to the challenges of large intra-class variances, ambiguous inter-class distinctions, and occlusions from shadows, trees, and buildings. Therefore, being able to perceive global context and model geometric information is essential to further improve the accuracy of road segmentation. In this paper, we design a novel dual-branch encoding block CoSwin which exploits the capability of global context modeling of Swin Transformer and that of local feature extraction of ResNet. Furthermore, we also propose a context-guided filter block named CFilter, which can filter out context-independent noisy features for better reconstructing of the details. We use CoSwin and CFilter in a U-shaped network architecture. Experiments on Massachusetts and CHN6-CUG datasets show that the proposed method outperforms other state-of-the-art methods on the metrics of F1, IoU, and OA. Further analysis reveals that the improvement in accuracy comes from better integrity and connectivity of segmented roads.