 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin transformers make strong contextual encoders for VHR image road extraction
Paper and Code
Jan 10, 2022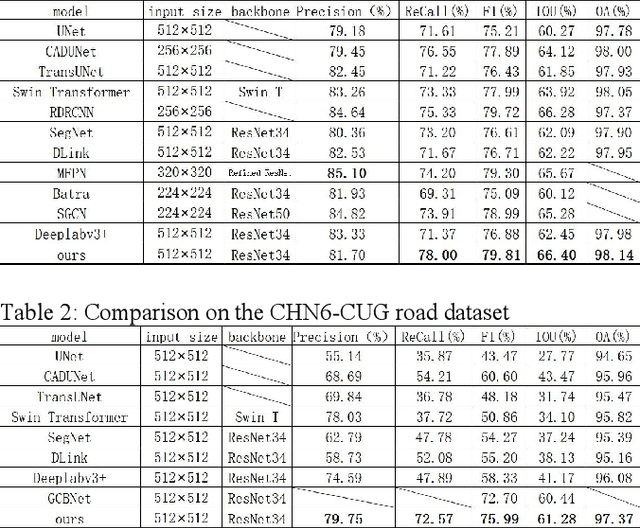

Significant progress has been made in automatic road extra-ction or segmentation based on deep learning, but there are still margins to improve in terms of the completeness and connectivity of the results. This is mainly due to the challenges of large intra-class variances, ambiguous inter-class distinctions, and occlusions from shadows, trees, and buildings. Therefore, being able to perceive global context and model geometric information is essential to further improve the accuracy of road segmentation. In this paper, we design a novel dual-branch encoding block CoSwin which exploits the capability of global context modeling of Swin Transformer and that of local feature extraction of ResNet. Furthermore, we also propose a context-guided filter block named CFilter, which can filter out context-independent noisy features for better reconstructing of the details. We use CoSwin and CFilter in a U-shaped network architecture. Experiments on Massachusetts and CHN6-CUG datasets show that the proposed method outperforms other state-of-the-art methods on the metrics of F1, IoU, and OA. Further analysis reveals that the improvement in accuracy comes from better integrity and connectivity of segmented roads.