 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


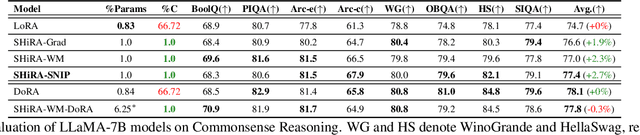
In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
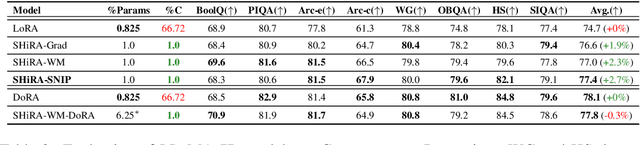
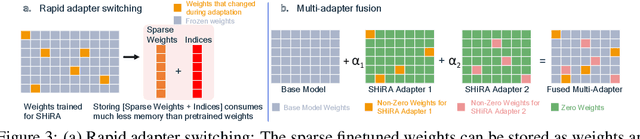
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FouRA: Fourier Low Rank Adaptation
Jun 13, 2024



While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on the GLUE benchmark.
DONNAv2 -- Lightweight Neural Architecture Search for Vision tasks
Sep 26, 2023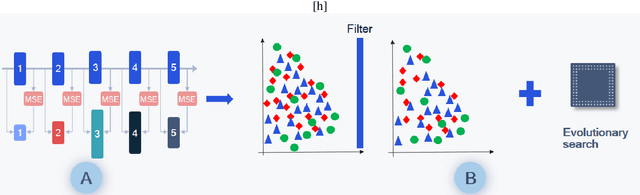

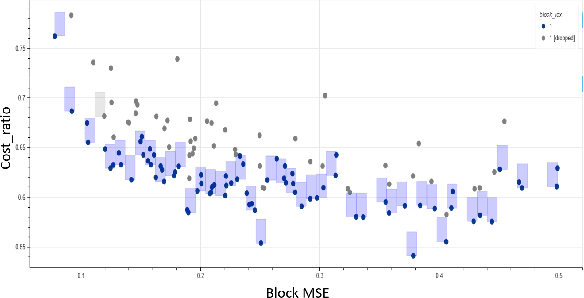

With the growing demand for vision applications and deployment across edge devices, the development of hardware-friendly architectures that maintain performance during device deployment becomes crucial. Neural architecture search (NAS) techniques explore various approaches to discover efficient architectures for diverse learning tasks in a computationally efficient manner. In this paper, we present the next-generation neural architecture design for computationally efficient neural architecture distillation - DONNAv2 . Conventional NAS algorithms rely on a computationally extensive stage where an accuracy predictor is learned to estimate model performance within search space. This building of accuracy predictors helps them predict the performance of models that are not being finetuned. Here, we have developed an elegant approach to eliminate building the accuracy predictor and extend DONNA to a computationally efficient setting. The loss metric of individual blocks forming the network serves as the surrogate performance measure for the sampled models in the NAS search stage. To validate the performance of DONNAv2 we have performed extensive experiments involving a range of diverse vision tasks including classification, object detection, image denoising, super-resolution, and panoptic perception network (YOLOP). The hardware-in-the-loop experiments were carried out using the Samsung Galaxy S10 mobile platform. Notably, DONNAv2 reduces the computational cost of DONNA by 10x for the larger datasets. Furthermore, to improve the quality of NAS search space, DONNAv2 leverages a block knowledge distillation filter to remove blocks with high inference costs.
Reinforcement Learning-Based Coverage Path Planning with Implicit Cellular Decomposition
Oct 18, 2021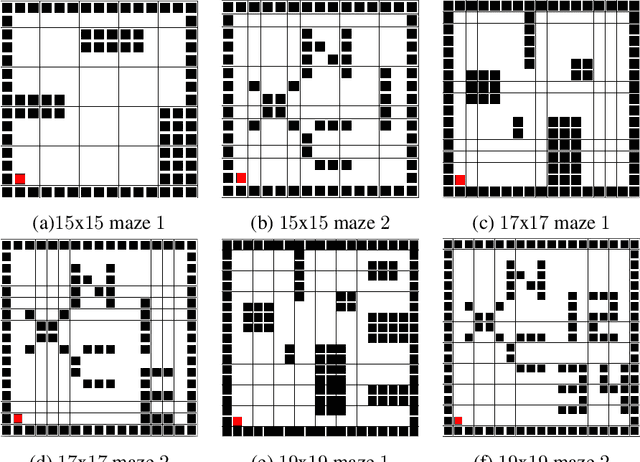
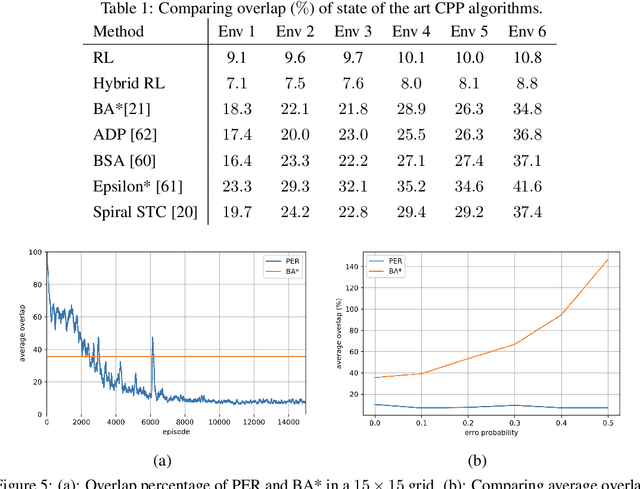
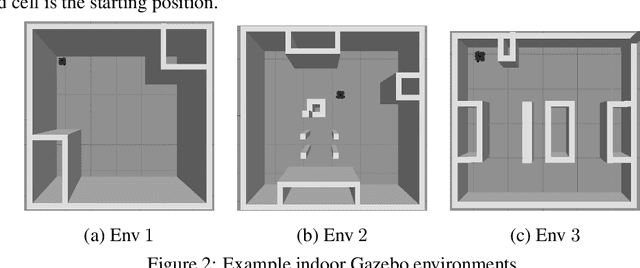
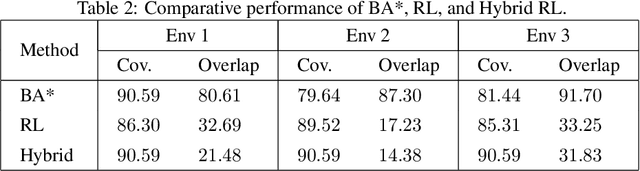
Coverage path planning in a generic known environment is shown to be NP-hard. When the environment is unknown, it becomes more challenging as the robot is required to rely on its online map information built during coverage for planning its path. A significant research effort focuses on designing heuristic or approximate algorithms that achieve reasonable performance. Such algorithms have sub-optimal performance in terms of covering the area or the cost of coverage, e.g., coverage time or energy consumption. In this paper, we provide a systematic analysis of the coverage problem and formulate it as an optimal stopping time problem, where the trade-off between coverage performance and its cost is explicitly accounted for. Next, we demonstrate that reinforcement learning (RL) techniques can be leveraged to solve the problem computationally. To this end, we provide some technical and practical considerations to facilitate the application of the RL algorithms and improve the efficiency of the solutions. Finally, through experiments in grid world environments and Gazebo simulator, we show that reinforcement learning-based algorithms efficiently cover realistic unknown indoor environments, and outperform the current state of the art.
A Survey on Proactive Customer Care: Enabling Science and Steps to Realize it
Oct 11, 2021

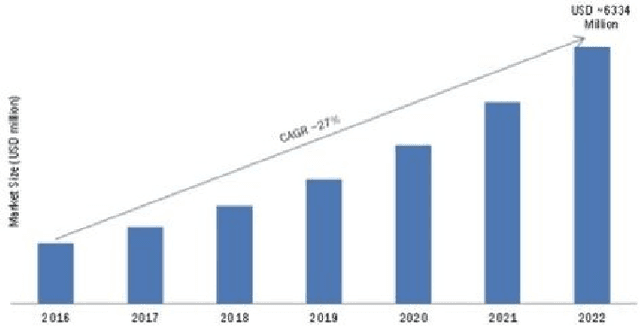
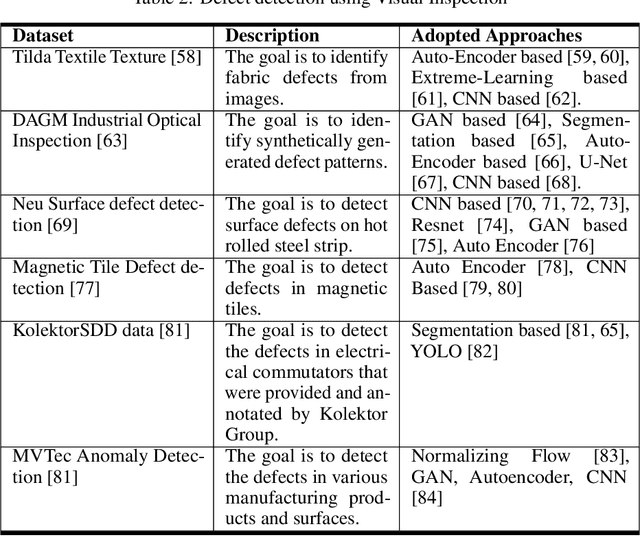
In recent times, advances in artificial intelligence (AI) and IoT have enabled seamless and viable maintenance of appliances in home and building environments. Several studies have shown that AI has the potential to provide personalized customer support which could predict and avoid errors more reliably than ever before. In this paper, we have analyzed the various building blocks needed to enable a successful AI-driven predictive maintenance use-case. Unlike, existing surveys which mostly provide a deep dive into the recent AI algorithms for Predictive Maintenance (PdM), our survey provides the complete view; starting from business impact to recent technology advancements in algorithms as well as systems research and model deployment. Furthermore, we provide exemplar use-cases on predictive maintenance of appliances using publicly available data sets. Our survey can serve as a template needed to design a successful predictive maintenance use-case. Finally, we touch upon existing public data sources and provide a step-wise breakdown of an AI-driven proactive customer care (PCC) use-case, starting from generic anomaly detection to fault prediction and finally root-cause analysis. We highlight how such a step-wise approach can be advantageous for accurate model building and helpful for gaining insights into predictive maintenance of electromechanical appliances.