 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Social Outcomes and Priorities centered (SOP) Framework for AI policy
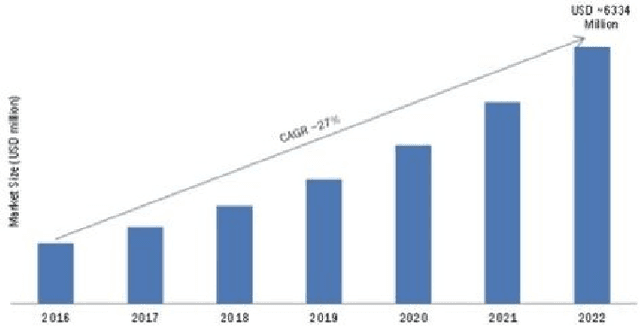
Nov 12, 2024Rapid developments in AI and its adoption across various domains have necessitated a need to build robust guardrails and risk containment plans while ensuring equitable benefits for the betterment of society. The current technology-centered approach has resulted in a fragmented, reactive, and ineffective policy apparatus. This paper highlights the immediate and urgent need to pivot to a society-centered approach to develop comprehensive, coherent, forward-looking AI policy. To this end, we present a Social Outcomes and Priorities centered (SOP) framework for AI policy along with proposals on implementation of its various components. While the SOP framework is presented from a US-centric view, the takeaways are general and applicable globally.
A Survey on Proactive Customer Care: Enabling Science and Steps to Realize it
Oct 11, 2021

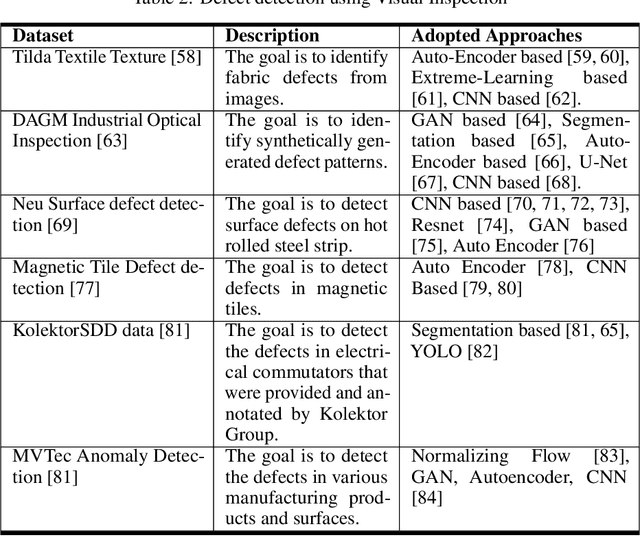
In recent times, advances in artificial intelligence (AI) and IoT have enabled seamless and viable maintenance of appliances in home and building environments. Several studies have shown that AI has the potential to provide personalized customer support which could predict and avoid errors more reliably than ever before. In this paper, we have analyzed the various building blocks needed to enable a successful AI-driven predictive maintenance use-case. Unlike, existing surveys which mostly provide a deep dive into the recent AI algorithms for Predictive Maintenance (PdM), our survey provides the complete view; starting from business impact to recent technology advancements in algorithms as well as systems research and model deployment. Furthermore, we provide exemplar use-cases on predictive maintenance of appliances using publicly available data sets. Our survey can serve as a template needed to design a successful predictive maintenance use-case. Finally, we touch upon existing public data sources and provide a step-wise breakdown of an AI-driven proactive customer care (PCC) use-case, starting from generic anomaly detection to fault prediction and finally root-cause analysis. We highlight how such a step-wise approach can be advantageous for accurate model building and helpful for gaining insights into predictive maintenance of electromechanical appliances.
Evolving GANs: When Contradictions Turn into Compliance
Jun 18, 2021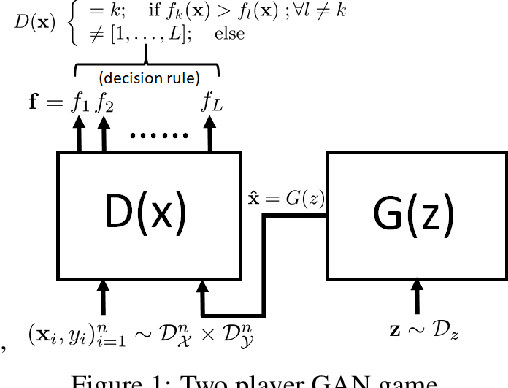
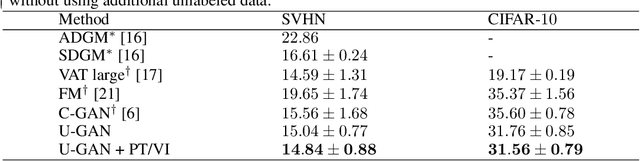
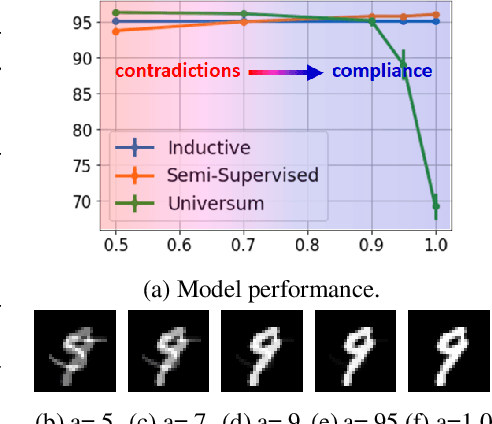

Limited availability of labeled-data makes any supervised learning problem challenging. Alternative learning settings like semi-supervised and universum learning alleviate the dependency on labeled data, but still require a large amount of unlabeled data, which may be unavailable or expensive to acquire. GAN-based synthetic data generation methods have recently shown promise by generating synthetic samples to improve task at hand. However, these samples cannot be used for other purposes. In this paper, we propose a GAN game which provides improved discriminator accuracy under limited data settings, while generating realistic synthetic data. This provides the added advantage that now the generated data can be used for other similar tasks. We provide the theoretical guarantees and empirical results in support of our approach.
Stochastic Whitening Batch Normalization
Jun 03, 2021
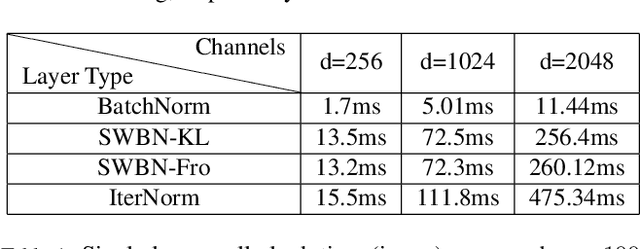

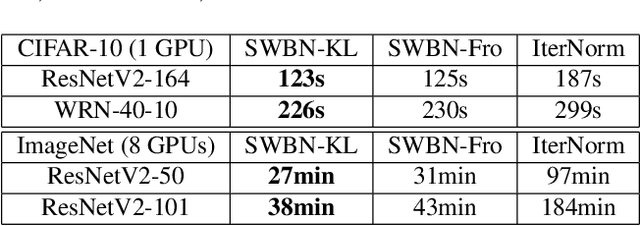
Batch Normalization (BN) is a popular technique for training Deep Neural Networks (DNNs). BN uses scaling and shifting to normalize activations of mini-batches to accelerate convergence and improve generalization. The recently proposed Iterative Normalization (IterNorm) method improves these properties by whitening the activations iteratively using Newton's method. However, since Newton's method initializes the whitening matrix independently at each training step, no information is shared between consecutive steps. In this work, instead of exact computation of whitening matrix at each time step, we estimate it gradually during training in an online fashion, using our proposed Stochastic Whitening Batch Normalization (SWBN) algorithm. We show that while SWBN improves the convergence rate and generalization of DNNs, its computational overhead is less than that of IterNorm. Due to the high efficiency of the proposed method, it can be easily employed in most DNN architectures with a large number of layers. We provide comprehensive experiments and comparisons between BN, IterNorm, and SWBN layers to demonstrate the effectiveness of the proposed technique in conventional (many-shot) image classification and few-shot classification tasks.
Stabilizing Bi-Level Hyperparameter Optimization using Moreau-Yosida Regularization
Jul 27, 2020
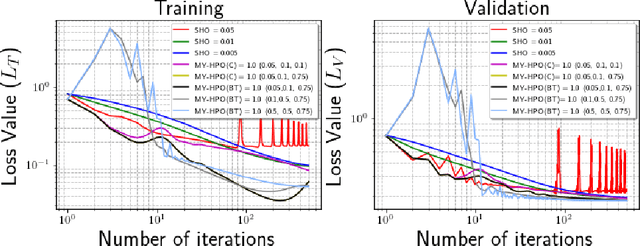
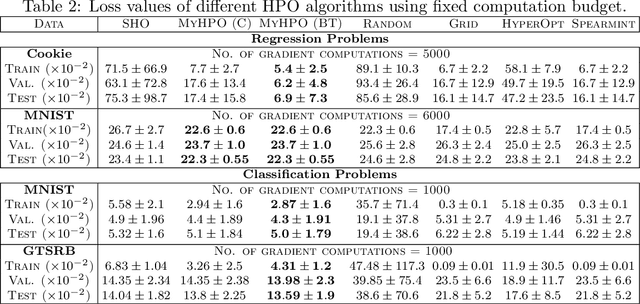
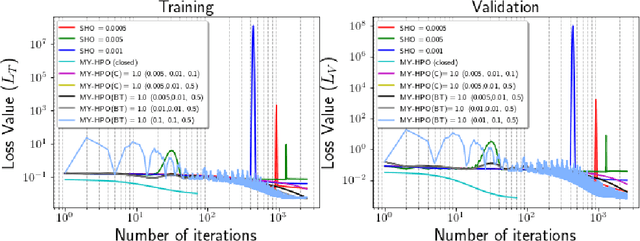
This research proposes to use the Moreau-Yosida envelope to stabilize the convergence behavior of bi-level Hyperparameter optimization solvers, and introduces the new algorithm called Moreau-Yosida regularized Hyperparameter Optimization (MY-HPO) algorithm. Theoretical analysis on the correctness of the MY-HPO solution and initial convergence analysis is also provided. Our empirical results show significant improvement in loss values for a fixed computation budget, compared to the state-of-art bi-level HPO solvers.
Pruning Algorithms to Accelerate Convolutional Neural Networks for Edge Applications: A Survey
May 08, 2020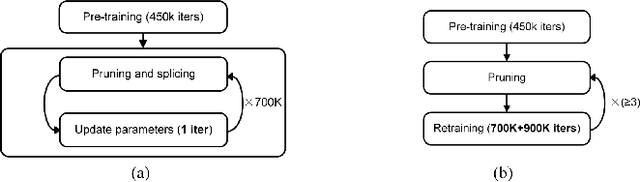
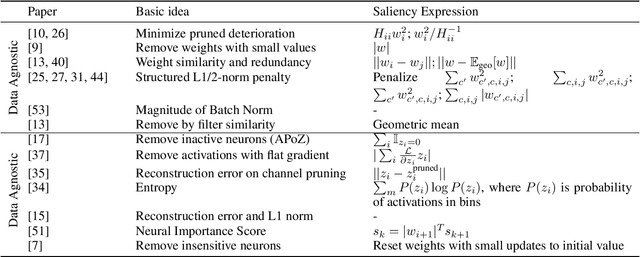
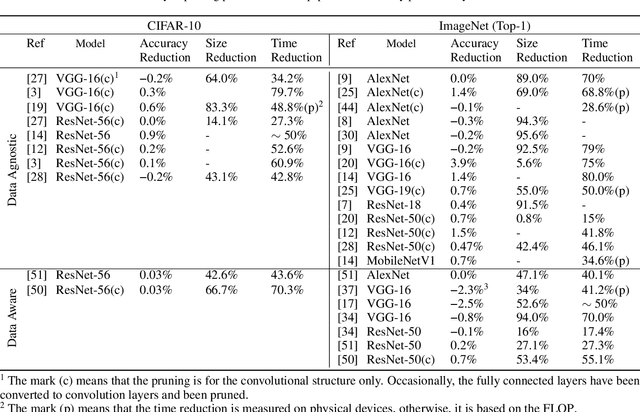
With the general trend of increasing Convolutional Neural Network (CNN) model sizes, model compression and acceleration techniques have become critical for the deployment of these models on edge devices. In this paper, we provide a comprehensive survey on Pruning, a major compression strategy that removes non-critical or redundant neurons from a CNN model. The survey covers the overarching motivation for pruning, different strategies and criteria, their advantages and drawbacks, along with a compilation of major pruning techniques. We conclude the survey with a discussion on alternatives to pruning and current challenges for the model compression community.
Auptimizer -- an Extensible, Open-Source Framework for Hyperparameter Tuning
Nov 06, 2019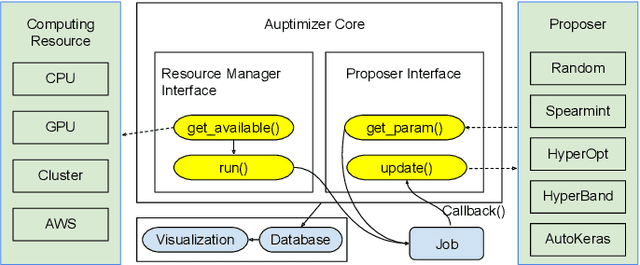

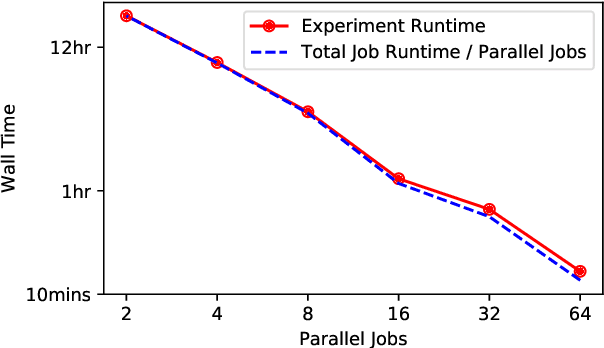
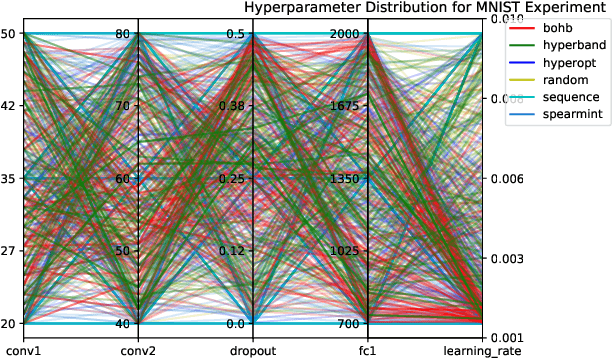
Tuning machine learning models at scale, especially finding the right hyperparameter values, can be difficult and time-consuming. In addition to the computational effort required, this process also requires some ancillary efforts including engineering tasks (e.g., job scheduling) as well as more mundane tasks (e.g., keeping track of the various parameters and associated results). We present Auptimizer, a general Hyperparameter Optimization (HPO) framework to help data scientists speed up model tuning and bookkeeping. With Auptimizer, users can use all available computing resources in distributed settings for model training. The user-friendly system design simplifies creating, controlling, and tracking of a typical machine learning project. The design also allows researchers to integrate new HPO algorithms. To demonstrate its flexibility, we show how Auptimizer integrates a few major HPO techniques (from random search to neural architecture search). The code is available at https://github.com/LGE-ARC-AdvancedAI/auptimizer.
On-Device Machine Learning: An Algorithms and Learning Theory Perspective
Nov 02, 2019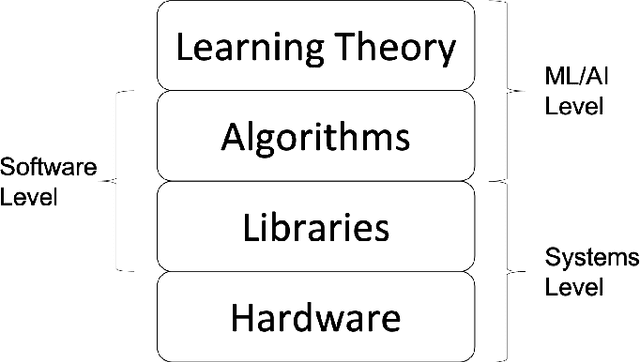

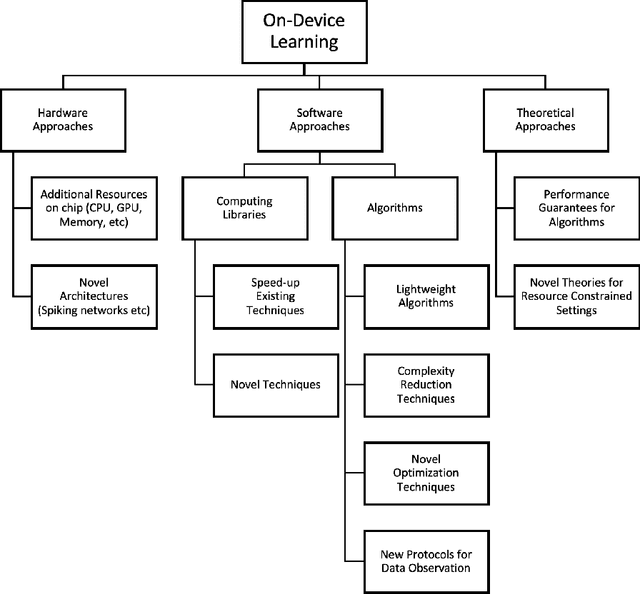
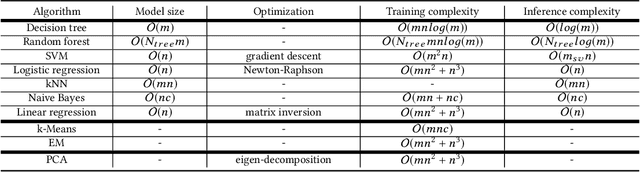
The current paradigm for using machine learning models on a device is to train a model in the cloud and perform inference using the trained model on the device. However, with the increasing number of smart devices and improved hardware, there is interest in performing model training on the device. Given this surge in interest, a comprehensive survey of the field from a device-agnostic perspective sets the stage for both understanding the state-of-the-art and for identifying open challenges and future avenues of research. Since on-device learning is an expansive field with connections to a large number of related topics in AI and machine learning (including online learning, model adaptation, one/few-shot learning, etc), covering such a large number of topics in a single survey is impractical. Instead, this survey finds a middle ground by reformulating the problem of on-device learning as resource constrained learning where the resources are compute and memory. This reformulation allows tools, techniques, and algorithms from a wide variety of research areas to be compared equitably. In addition to summarizing the state of the art, the survey also identifies a number of challenges and next steps for both the algorithmic and theoretical aspects of on-device learning.
Variable Metric Proximal Gradient Method with Diagonal Barzilai-Borwein Stepsize
Oct 15, 2019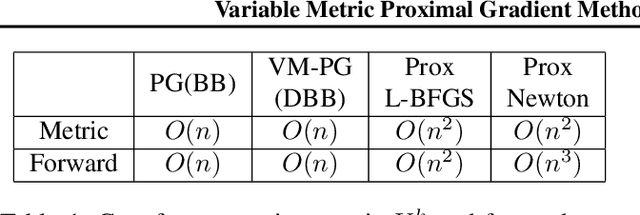
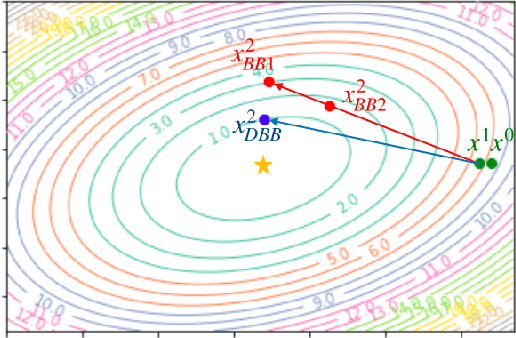

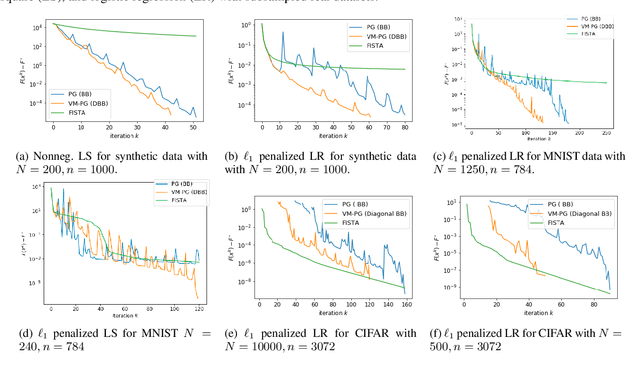
Variable metric proximal gradient (VM-PG) is a widely used class of convex optimization method. Lately, there has been a lot of research on the theoretical guarantees of VM-PG with different metric selections. However, most such metric selections are dependent on (an expensive) Hessian, or limited to scalar stepsizes like the Barzilai-Borwein (BB) stepsize with lots of safeguarding. Instead, in this paper we propose an adaptive metric selection strategy called the diagonal Barzilai-Borwein (BB) stepsize. The proposed diagonal selection better captures the local geometry of the problem while keeping per-step computation cost similar to the scalar BB stepsize i.e. $O(n)$. Under this metric selection for VM-PG, the theoretical convergence is analyzed. Our empirical studies illustrate the improved convergence results under the proposed diagonal BB stepsize, specifically for ill-conditioned machine learning problems for both synthetic and real-world datasets.
Robust Neural Network Training using Periodic Sampling over Model Weights
May 14, 2019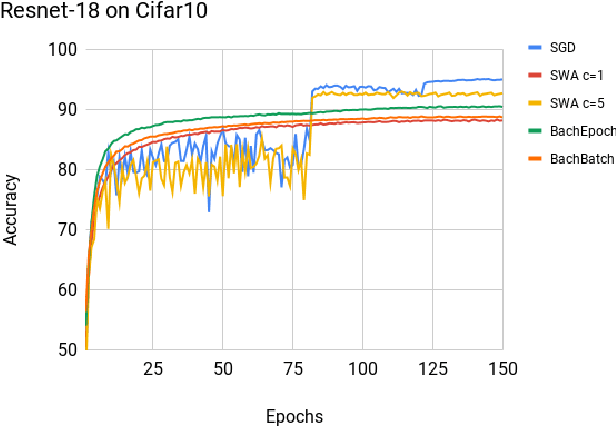
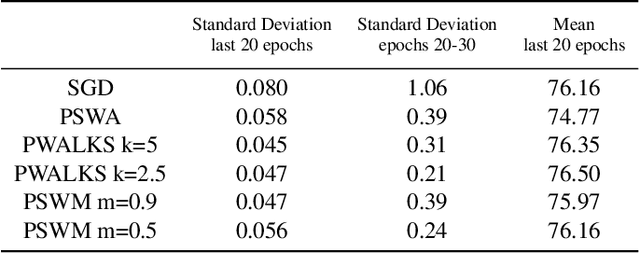
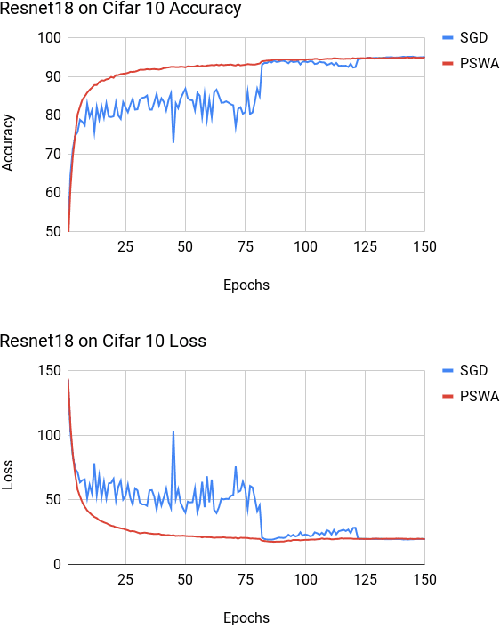
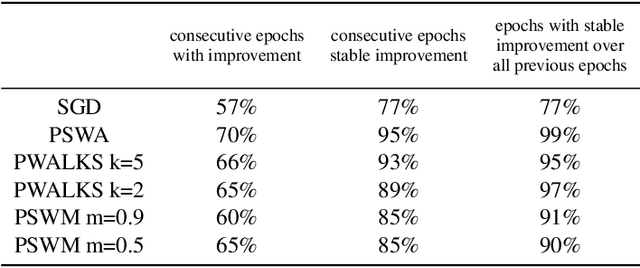
Deep neural networks provide best-in-class performance for a number of computer vision problems. However, training these networks is computationally intensive and requires fine-tuning various hyperparameters. In addition, performance swings widely as the network converges making it hard to decide when to stop training. In this paper, we introduce a trio of techniques (PSWA, PWALKS, and PSWM) centered around periodic sampling of model weights that provide consistent and more robust convergence on a variety of vision problems (classification, detection, segmentation) and gradient update methods (vanilla SGD, Momentum, Adam) with marginal additional computation time. Our techniques use existing optimal training policies but converge in a less volatile fashion with performance improvements that are approximately monotonic. Our analysis of the loss surface shows that these techniques also produce minima that are deeper and wider than those found by SGD.