 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Shifted Augmentations (NSA): compact distributions for robust self-supervised Anomaly Detection
Mar 19, 2022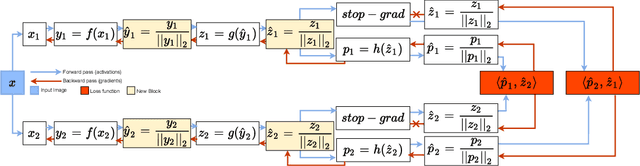
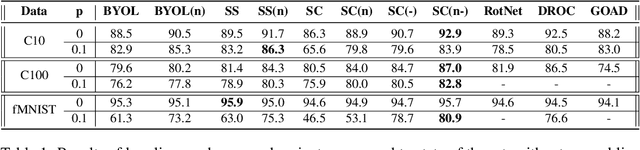
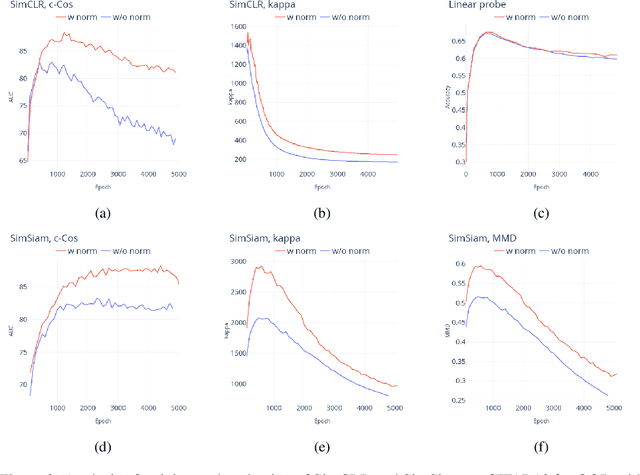
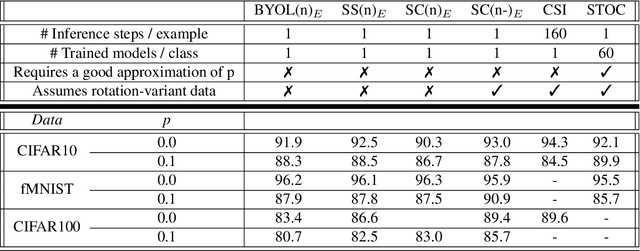
Unsupervised Anomaly detection (AD) requires building a notion of normalcy, distinguishing in-distribution (ID) and out-of-distribution (OOD) data, using only available ID samples. Recently, large gains were made on this task for the domain of natural images using self-supervised contrastive feature learning as a first step followed by kNN or traditional one-class classifiers for feature scoring. Learned representations that are non-uniformly distributed on the unit hypersphere have been shown to be beneficial for this task. We go a step further and investigate how the \emph {geometrical compactness} of the ID feature distribution makes isolating and detecting outliers easier, especially in the realistic situation when ID training data is polluted (i.e. ID data contains some OOD data that is used for learning the feature extractor parameters). We propose novel architectural modifications to the self-supervised feature learning step, that enable such compact distributions for ID data to be learned. We show that the proposed modifications can be effectively applied to most existing self-supervised objectives, with large gains in performance. Furthermore, this improved OOD performance is obtained without resorting to tricks such as using strongly augmented ID images (e.g. by 90 degree rotations) as proxies for the unseen OOD data, as these impose overly prescriptive assumptions about ID data and its invariances. We perform extensive studies on benchmark datasets for one-class OOD detection and show state-of-the-art performance in the presence of pollution in the ID data, and comparable performance otherwise. We also propose and extensively evaluate a novel feature scoring technique based on the angular Mahalanobis distance, and propose a simple and novel technique for feature ensembling during evaluation that enables a big boost in performance at nearly zero run-time cost.
Evolving GANs: When Contradictions Turn into Compliance
Jun 18, 2021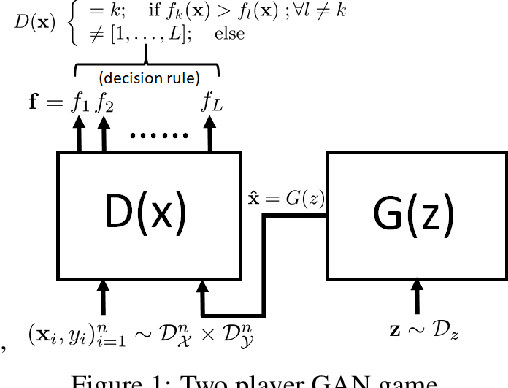
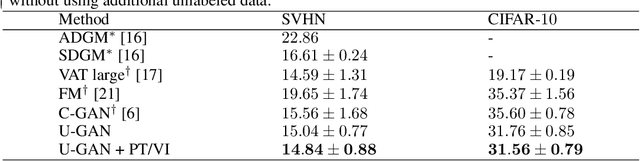
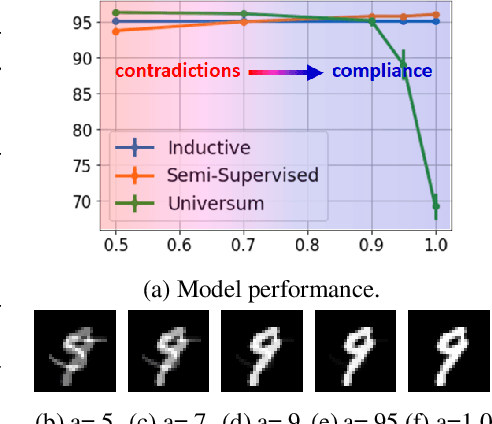

Limited availability of labeled-data makes any supervised learning problem challenging. Alternative learning settings like semi-supervised and universum learning alleviate the dependency on labeled data, but still require a large amount of unlabeled data, which may be unavailable or expensive to acquire. GAN-based synthetic data generation methods have recently shown promise by generating synthetic samples to improve task at hand. However, these samples cannot be used for other purposes. In this paper, we propose a GAN game which provides improved discriminator accuracy under limited data settings, while generating realistic synthetic data. This provides the added advantage that now the generated data can be used for other similar tasks. We provide the theoretical guarantees and empirical results in support of our approach.
Stabilizing Bi-Level Hyperparameter Optimization using Moreau-Yosida Regularization
Jul 27, 2020
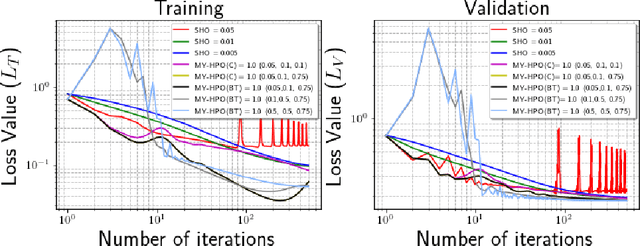
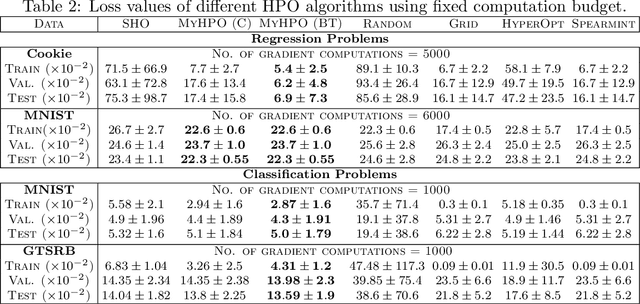
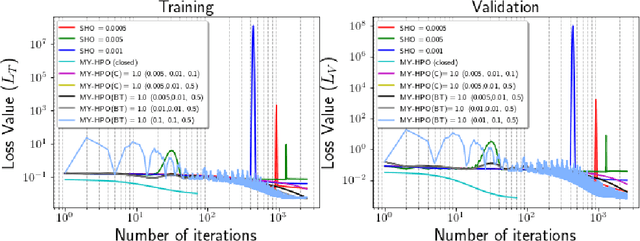
This research proposes to use the Moreau-Yosida envelope to stabilize the convergence behavior of bi-level Hyperparameter optimization solvers, and introduces the new algorithm called Moreau-Yosida regularized Hyperparameter Optimization (MY-HPO) algorithm. Theoretical analysis on the correctness of the MY-HPO solution and initial convergence analysis is also provided. Our empirical results show significant improvement in loss values for a fixed computation budget, compared to the state-of-art bi-level HPO solvers.
Pruning Algorithms to Accelerate Convolutional Neural Networks for Edge Applications: A Survey
May 08, 2020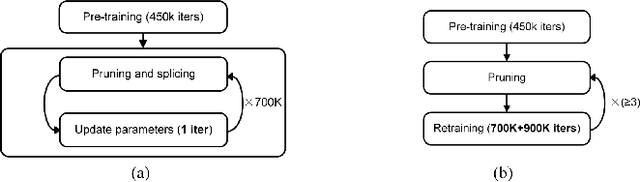
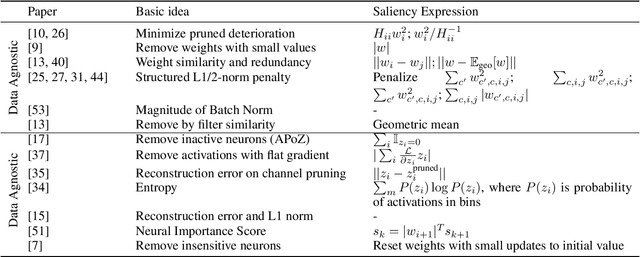
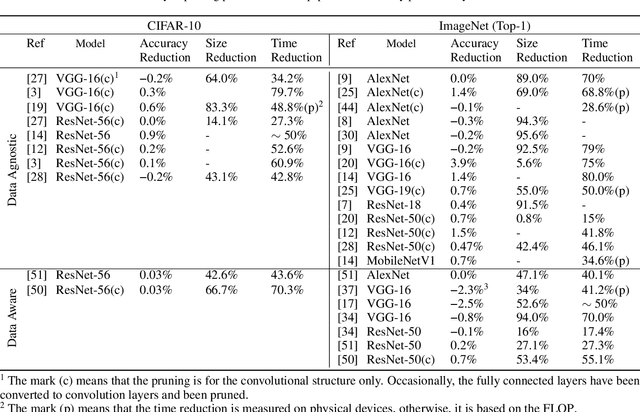
With the general trend of increasing Convolutional Neural Network (CNN) model sizes, model compression and acceleration techniques have become critical for the deployment of these models on edge devices. In this paper, we provide a comprehensive survey on Pruning, a major compression strategy that removes non-critical or redundant neurons from a CNN model. The survey covers the overarching motivation for pruning, different strategies and criteria, their advantages and drawbacks, along with a compilation of major pruning techniques. We conclude the survey with a discussion on alternatives to pruning and current challenges for the model compression community.
Auptimizer -- an Extensible, Open-Source Framework for Hyperparameter Tuning
Nov 06, 2019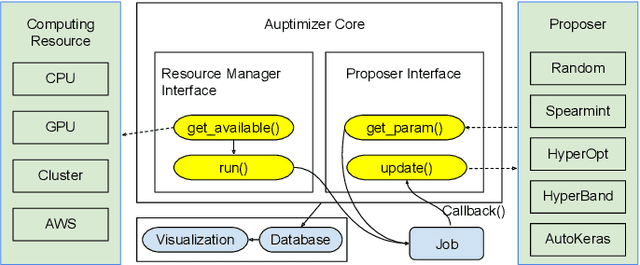

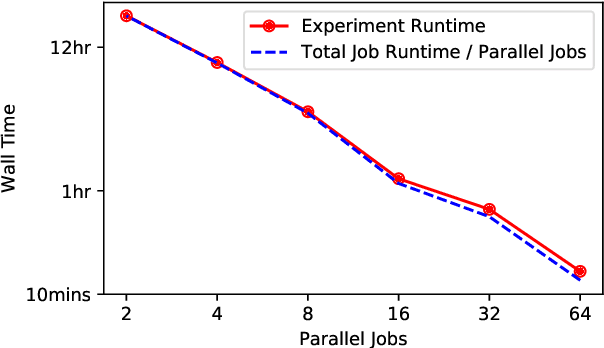
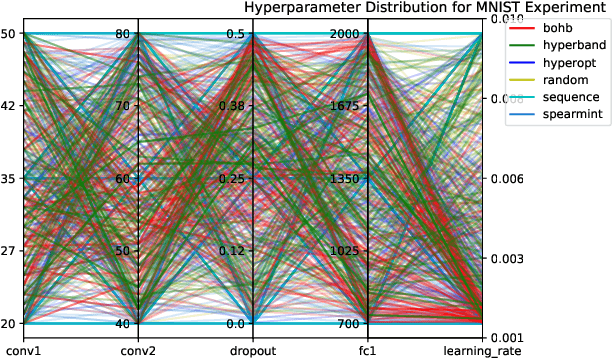
Tuning machine learning models at scale, especially finding the right hyperparameter values, can be difficult and time-consuming. In addition to the computational effort required, this process also requires some ancillary efforts including engineering tasks (e.g., job scheduling) as well as more mundane tasks (e.g., keeping track of the various parameters and associated results). We present Auptimizer, a general Hyperparameter Optimization (HPO) framework to help data scientists speed up model tuning and bookkeeping. With Auptimizer, users can use all available computing resources in distributed settings for model training. The user-friendly system design simplifies creating, controlling, and tracking of a typical machine learning project. The design also allows researchers to integrate new HPO algorithms. To demonstrate its flexibility, we show how Auptimizer integrates a few major HPO techniques (from random search to neural architecture search). The code is available at https://github.com/LGE-ARC-AdvancedAI/auptimizer.
On-Device Machine Learning: An Algorithms and Learning Theory Perspective
Nov 02, 2019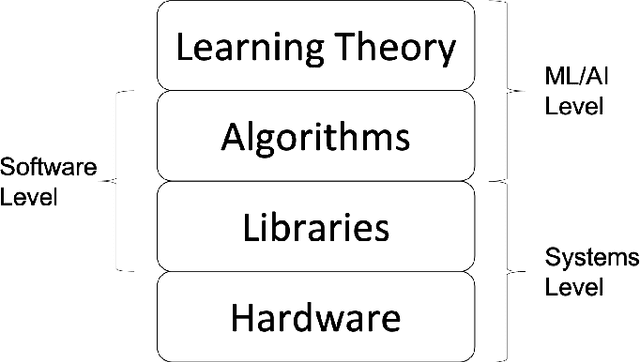

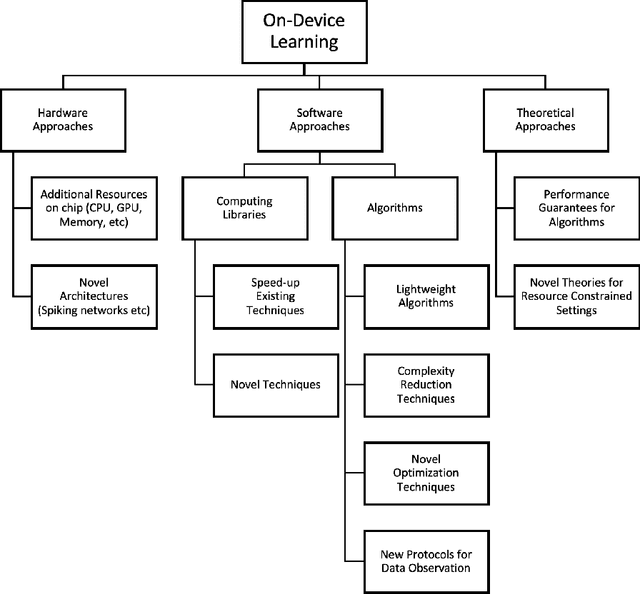
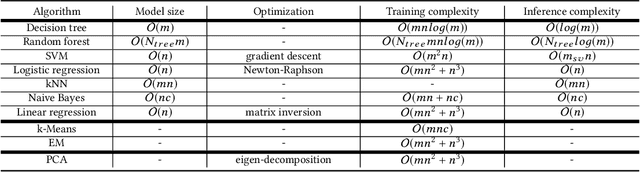
The current paradigm for using machine learning models on a device is to train a model in the cloud and perform inference using the trained model on the device. However, with the increasing number of smart devices and improved hardware, there is interest in performing model training on the device. Given this surge in interest, a comprehensive survey of the field from a device-agnostic perspective sets the stage for both understanding the state-of-the-art and for identifying open challenges and future avenues of research. Since on-device learning is an expansive field with connections to a large number of related topics in AI and machine learning (including online learning, model adaptation, one/few-shot learning, etc), covering such a large number of topics in a single survey is impractical. Instead, this survey finds a middle ground by reformulating the problem of on-device learning as resource constrained learning where the resources are compute and memory. This reformulation allows tools, techniques, and algorithms from a wide variety of research areas to be compared equitably. In addition to summarizing the state of the art, the survey also identifies a number of challenges and next steps for both the algorithmic and theoretical aspects of on-device learning.
Robust Neural Network Training using Periodic Sampling over Model Weights
May 14, 2019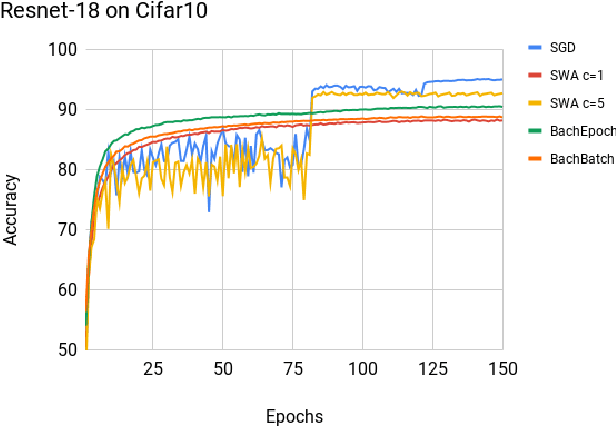
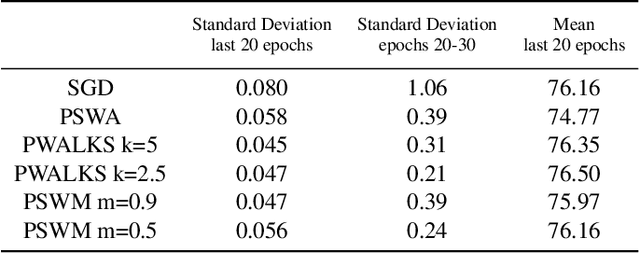
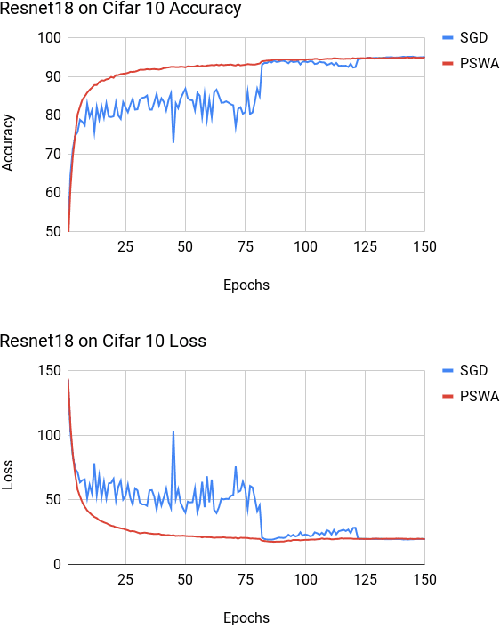
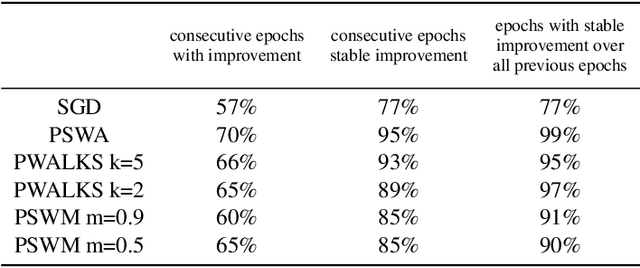
Deep neural networks provide best-in-class performance for a number of computer vision problems. However, training these networks is computationally intensive and requires fine-tuning various hyperparameters. In addition, performance swings widely as the network converges making it hard to decide when to stop training. In this paper, we introduce a trio of techniques (PSWA, PWALKS, and PSWM) centered around periodic sampling of model weights that provide consistent and more robust convergence on a variety of vision problems (classification, detection, segmentation) and gradient update methods (vanilla SGD, Momentum, Adam) with marginal additional computation time. Our techniques use existing optimal training policies but converge in a less volatile fashion with performance improvements that are approximately monotonic. Our analysis of the loss surface shows that these techniques also produce minima that are deeper and wider than those found by SGD.
Is it Safe to Drive? An Overview of Factors, Challenges, and Datasets for Driveability Assessment in Autonomous Driving
Nov 27, 2018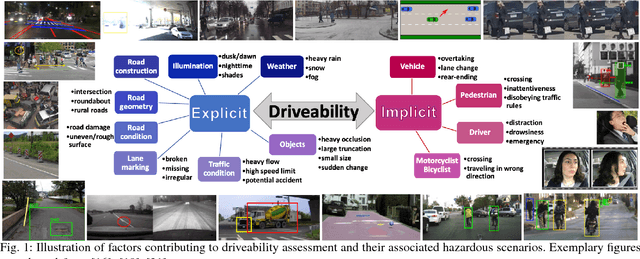



With recent advances in learning algorithms and hardware development, autonomous cars have shown promise when operating in structured environments under good driving conditions. However, for complex, cluttered and unseen environments with high uncertainty, autonomous driving systems still frequently demonstrate erroneous or unexpected behaviors, that could lead to catastrophic outcomes. Autonomous vehicles should ideally adapt to driving conditions; while this can be achieved through multiple routes, it would be beneficial as a first step to be able to characterize Driveability in some quantified form. To this end, this paper aims to create a framework for investigating different factors that can impact driveability. Also, one of the main mechanisms to adapt autonomous driving systems to any driving condition is to be able to learn and generalize from representative scenarios. The machine learning algorithms that currently do so learn predominantly in a supervised manner and consequently need sufficient data for robust and efficient learning. Therefore, we also perform a comparative overview of 45 public driving datasets that enable learning and publish this dataset index at https://sites.google.com/view/driveability-survey-datasets. Specifically, we categorize the datasets according to use cases, and highlight the datasets that capture complicated and hazardous driving conditions which can be better used for training robust driving models. Furthermore, by discussions of what driving scenarios are not covered by existing public datasets and what driveability factors need more investigation and data acquisition, this paper aims to encourage both targeted dataset collection and the proposal of novel driveability metrics that enhance the robustness of autonomous cars in adverse environments.
Make (Nearly) Every Neural Network Better: Generating Neural Network Ensembles by Weight Parameter Resampling
Jul 02, 2018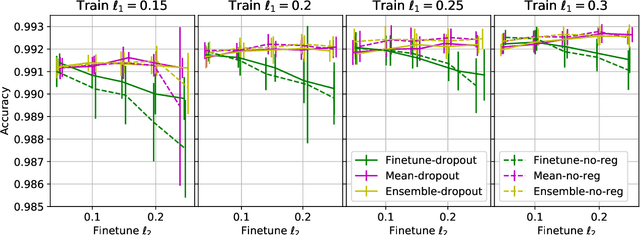
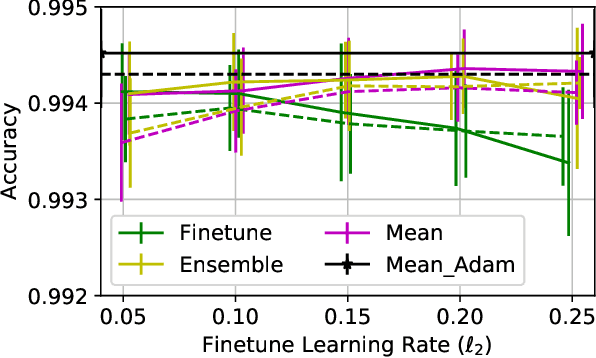
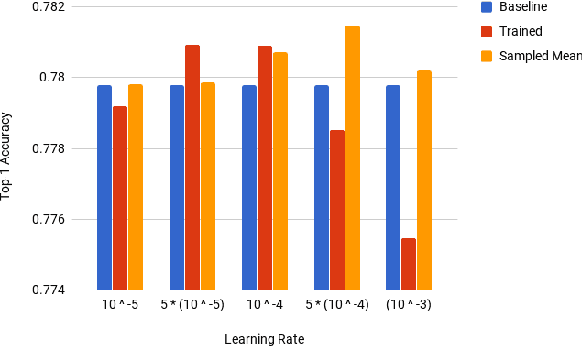
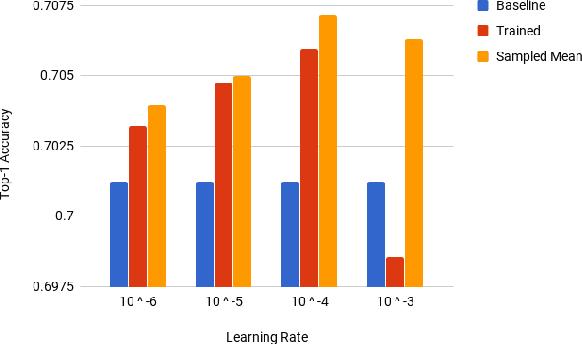
Deep Neural Networks (DNNs) have become increasingly popular in computer vision, natural language processing, and other areas. However, training and fine-tuning a deep learning model is computationally intensive and time-consuming. We propose a new method to improve the performance of nearly every model including pre-trained models. The proposed method uses an ensemble approach where the networks in the ensemble are constructed by reassigning model parameter values based on the probabilistic distribution of these parameters, calculated towards the end of the training process. For pre-trained models, this approach results in an additional training step (usually less than one epoch). We perform a variety of analysis using the MNIST dataset and validate the approach with a number of DNN models using pre-trained models on the ImageNet dataset.
Effective Building Block Design for Deep Convolutional Neural Networks using Search
Jan 25, 2018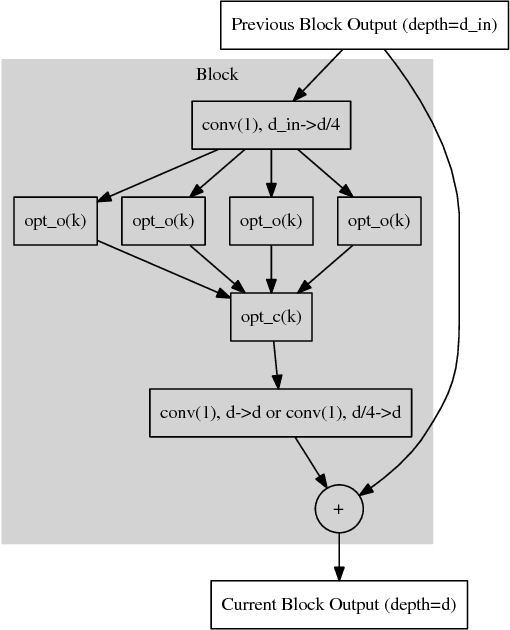

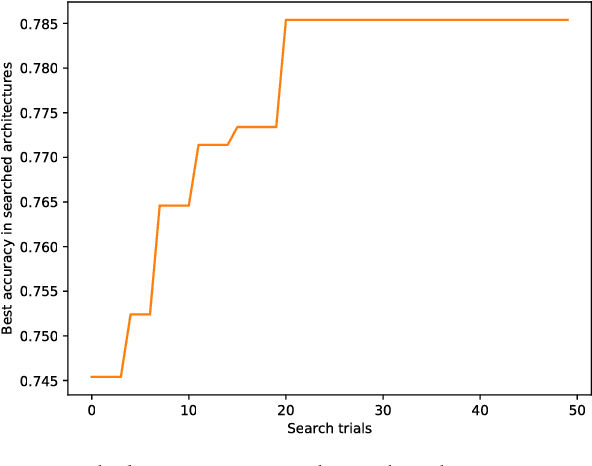
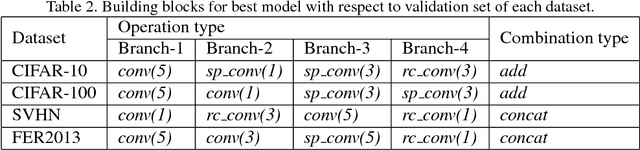
Deep learning has shown promising results on many machine learning tasks but DL models are often complex networks with large number of neurons and layers, and recently, complex layer structures known as building blocks. Finding the best deep model requires a combination of finding both the right architecture and the correct set of parameters appropriate for that architecture. In addition, this complexity (in terms of layer types, number of neurons, and number of layers) also present problems with generalization since larger networks are easier to overfit to the data. In this paper, we propose a search framework for finding effective architectural building blocks for convolutional neural networks (CNN). Our approach is much faster at finding models that are close to state-of-the-art in performance. In addition, the models discovered by our approach are also smaller than models discovered by similar techniques. We achieve these twin advantages by designing our search space in such a way that it searches over a reduced set of state-of-the-art building blocks for CNNs including residual block, inception block, inception-residual block, ResNeXt block and many others. We apply this technique to generate models for multiple image datasets and show that these models achieve performance comparable to state-of-the-art (and even surpassing the state-of-the-art in one case). We also show that learned models are transferable between datasets.