 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving GANs: When Contradictions Turn into Compliance
Jun 18, 2021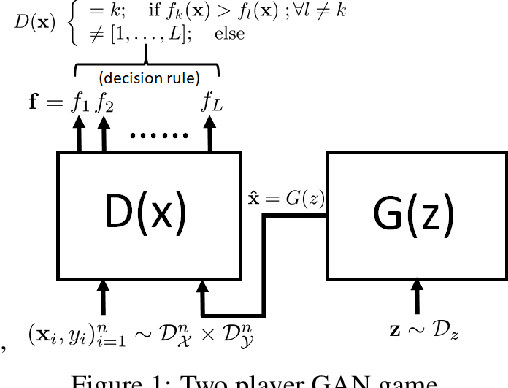
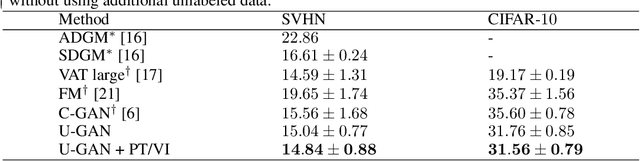
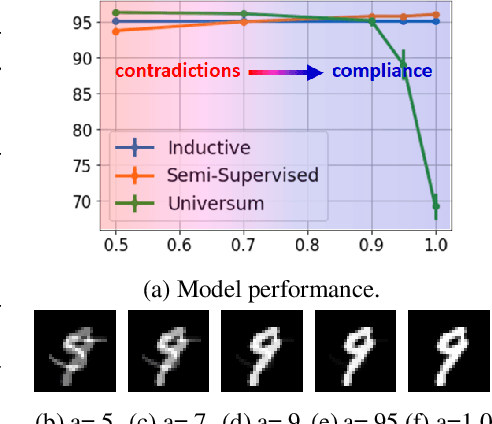

Limited availability of labeled-data makes any supervised learning problem challenging. Alternative learning settings like semi-supervised and universum learning alleviate the dependency on labeled data, but still require a large amount of unlabeled data, which may be unavailable or expensive to acquire. GAN-based synthetic data generation methods have recently shown promise by generating synthetic samples to improve task at hand. However, these samples cannot be used for other purposes. In this paper, we propose a GAN game which provides improved discriminator accuracy under limited data settings, while generating realistic synthetic data. This provides the added advantage that now the generated data can be used for other similar tasks. We provide the theoretical guarantees and empirical results in support of our approach.
Pruning Algorithms to Accelerate Convolutional Neural Networks for Edge Applications: A Survey
May 08, 2020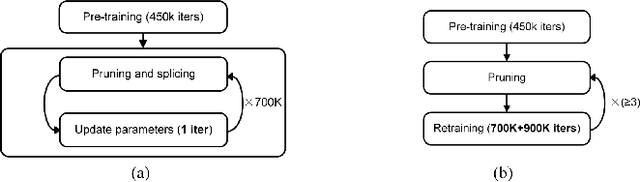
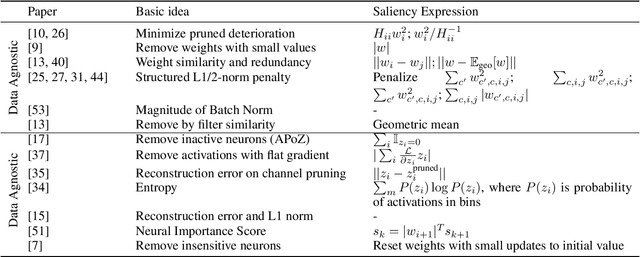
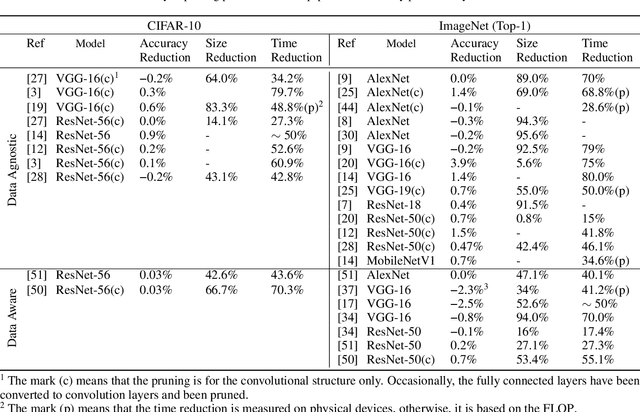
With the general trend of increasing Convolutional Neural Network (CNN) model sizes, model compression and acceleration techniques have become critical for the deployment of these models on edge devices. In this paper, we provide a comprehensive survey on Pruning, a major compression strategy that removes non-critical or redundant neurons from a CNN model. The survey covers the overarching motivation for pruning, different strategies and criteria, their advantages and drawbacks, along with a compilation of major pruning techniques. We conclude the survey with a discussion on alternatives to pruning and current challenges for the model compression community.
Auptimizer -- an Extensible, Open-Source Framework for Hyperparameter Tuning
Nov 06, 2019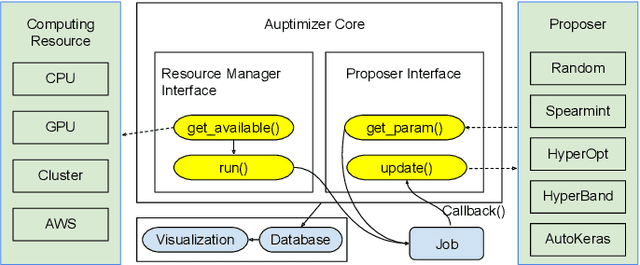

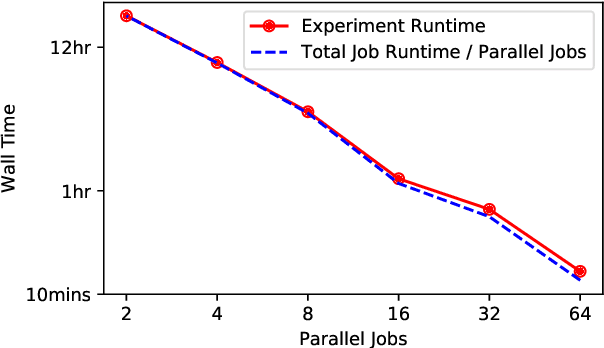
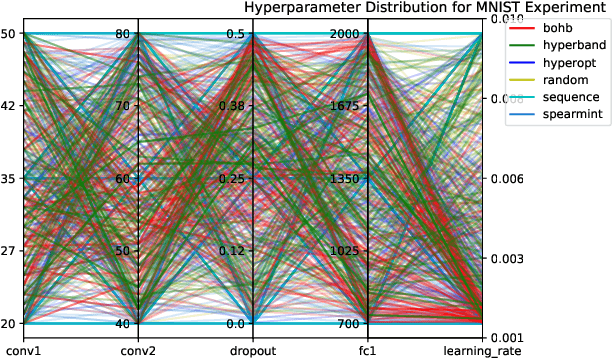
Tuning machine learning models at scale, especially finding the right hyperparameter values, can be difficult and time-consuming. In addition to the computational effort required, this process also requires some ancillary efforts including engineering tasks (e.g., job scheduling) as well as more mundane tasks (e.g., keeping track of the various parameters and associated results). We present Auptimizer, a general Hyperparameter Optimization (HPO) framework to help data scientists speed up model tuning and bookkeeping. With Auptimizer, users can use all available computing resources in distributed settings for model training. The user-friendly system design simplifies creating, controlling, and tracking of a typical machine learning project. The design also allows researchers to integrate new HPO algorithms. To demonstrate its flexibility, we show how Auptimizer integrates a few major HPO techniques (from random search to neural architecture search). The code is available at https://github.com/LGE-ARC-AdvancedAI/auptimizer.
On-Device Machine Learning: An Algorithms and Learning Theory Perspective
Nov 02, 2019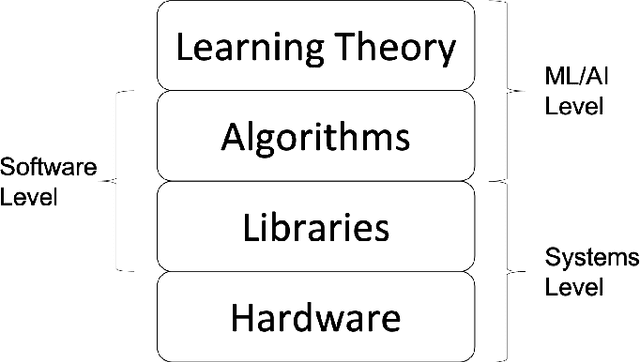

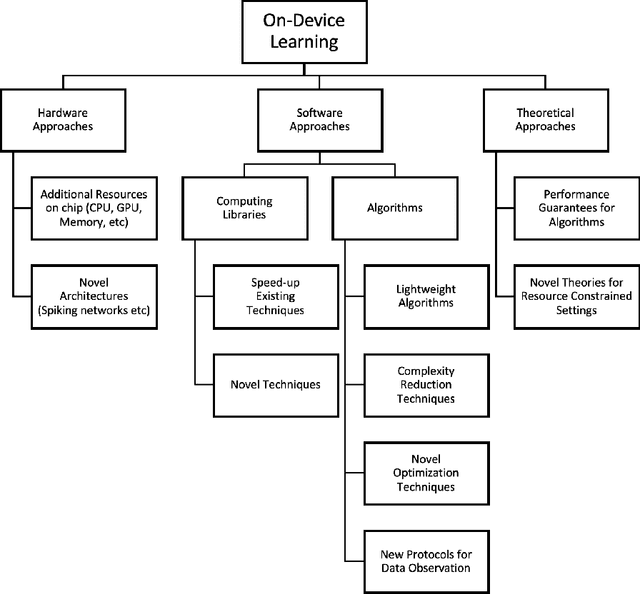
The current paradigm for using machine learning models on a device is to train a model in the cloud and perform inference using the trained model on the device. However, with the increasing number of smart devices and improved hardware, there is interest in performing model training on the device. Given this surge in interest, a comprehensive survey of the field from a device-agnostic perspective sets the stage for both understanding the state-of-the-art and for identifying open challenges and future avenues of research. Since on-device learning is an expansive field with connections to a large number of related topics in AI and machine learning (including online learning, model adaptation, one/few-shot learning, etc), covering such a large number of topics in a single survey is impractical. Instead, this survey finds a middle ground by reformulating the problem of on-device learning as resource constrained learning where the resources are compute and memory. This reformulation allows tools, techniques, and algorithms from a wide variety of research areas to be compared equitably. In addition to summarizing the state of the art, the survey also identifies a number of challenges and next steps for both the algorithmic and theoretical aspects of on-device learning.
Robust Neural Network Training using Periodic Sampling over Model Weights
May 14, 2019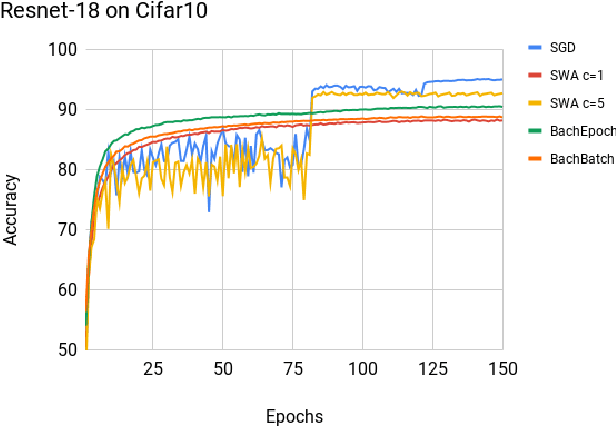
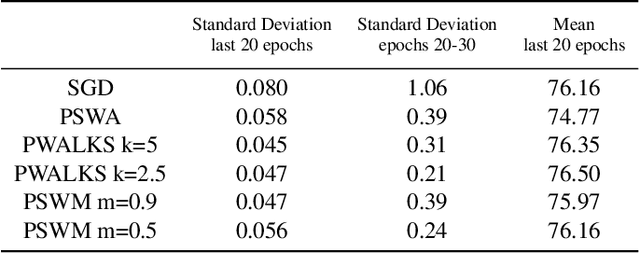
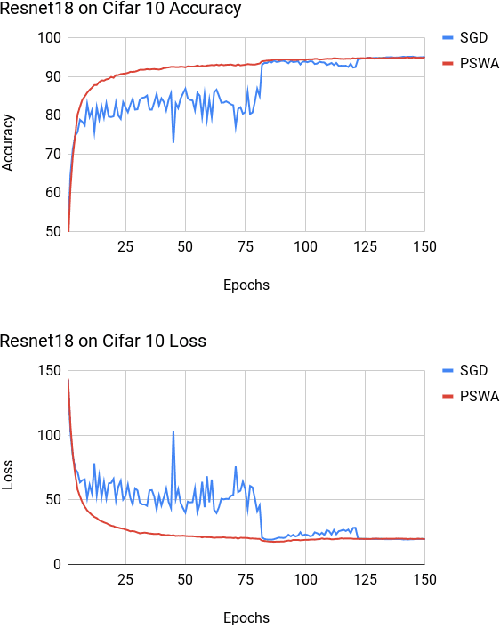
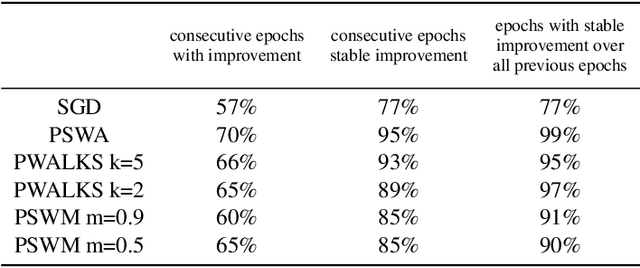
Deep neural networks provide best-in-class performance for a number of computer vision problems. However, training these networks is computationally intensive and requires fine-tuning various hyperparameters. In addition, performance swings widely as the network converges making it hard to decide when to stop training. In this paper, we introduce a trio of techniques (PSWA, PWALKS, and PSWM) centered around periodic sampling of model weights that provide consistent and more robust convergence on a variety of vision problems (classification, detection, segmentation) and gradient update methods (vanilla SGD, Momentum, Adam) with marginal additional computation time. Our techniques use existing optimal training policies but converge in a less volatile fashion with performance improvements that are approximately monotonic. Our analysis of the loss surface shows that these techniques also produce minima that are deeper and wider than those found by SGD.
Make (Nearly) Every Neural Network Better: Generating Neural Network Ensembles by Weight Parameter Resampling
Jul 02, 2018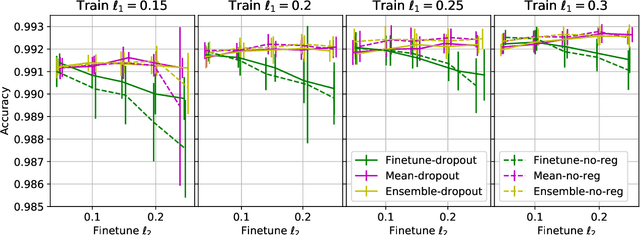
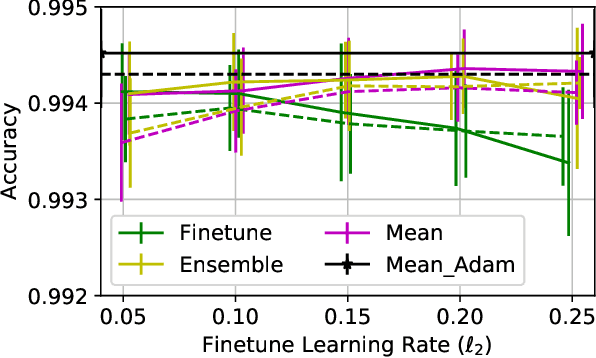
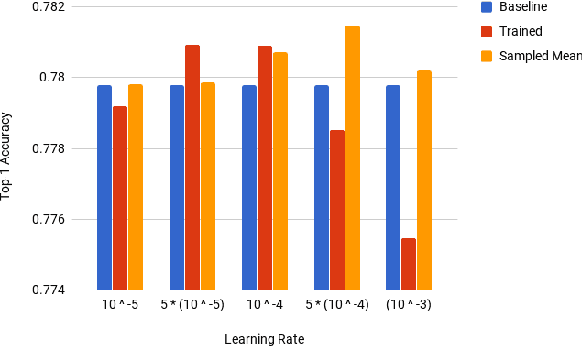
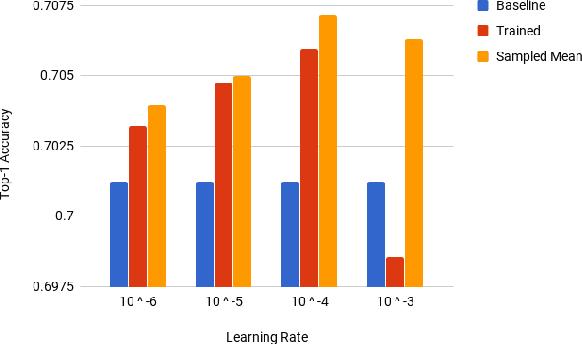
Deep Neural Networks (DNNs) have become increasingly popular in computer vision, natural language processing, and other areas. However, training and fine-tuning a deep learning model is computationally intensive and time-consuming. We propose a new method to improve the performance of nearly every model including pre-trained models. The proposed method uses an ensemble approach where the networks in the ensemble are constructed by reassigning model parameter values based on the probabilistic distribution of these parameters, calculated towards the end of the training process. For pre-trained models, this approach results in an additional training step (usually less than one epoch). We perform a variety of analysis using the MNIST dataset and validate the approach with a number of DNN models using pre-trained models on the ImageNet dataset.
Towards Deeper Generative Architectures for GANs using Dense connections
Apr 30, 2018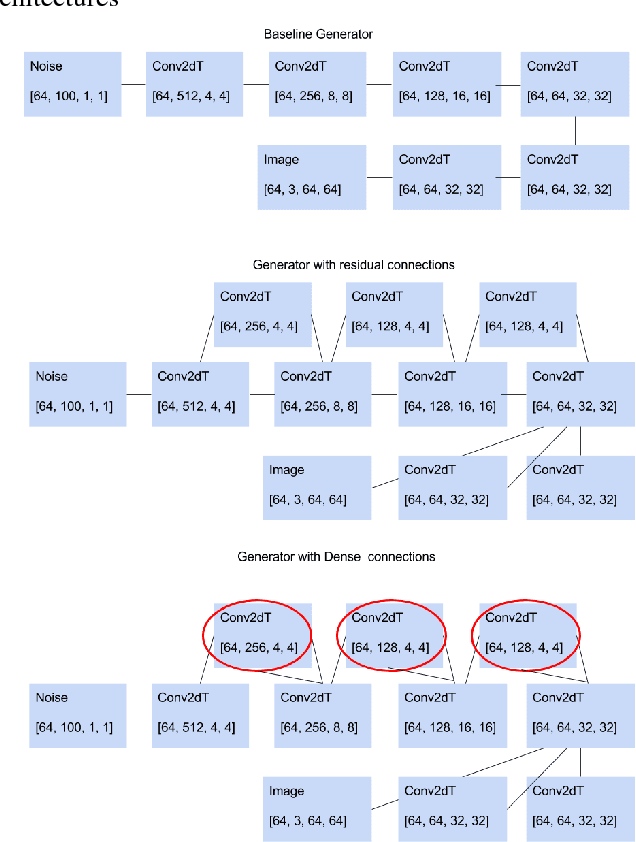
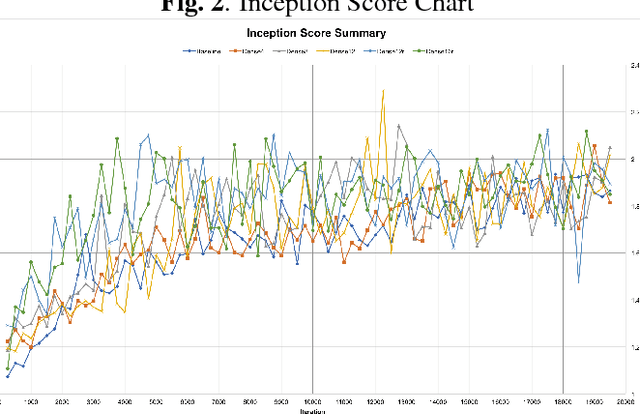

In this paper, we present the result of adopting skip connections and dense layers, previously used in image classification tasks, in the Fisher GAN implementation. We have experimented with different numbers of layers and inserting these connections in different sections of the network. Our findings suggests that networks implemented with the connections produce better images than the baseline, and the number of connections added has only slight effect on the result.
Multi-Modal Emotion recognition on IEMOCAP Dataset using Deep Learning
Apr 16, 2018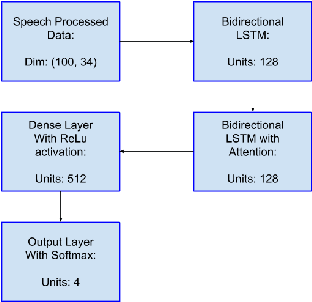
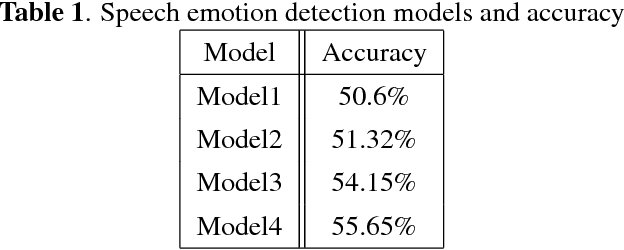
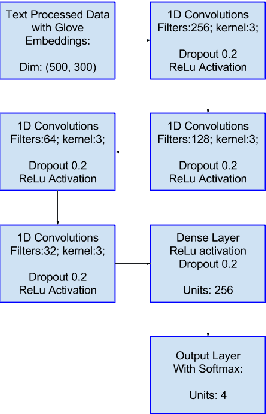
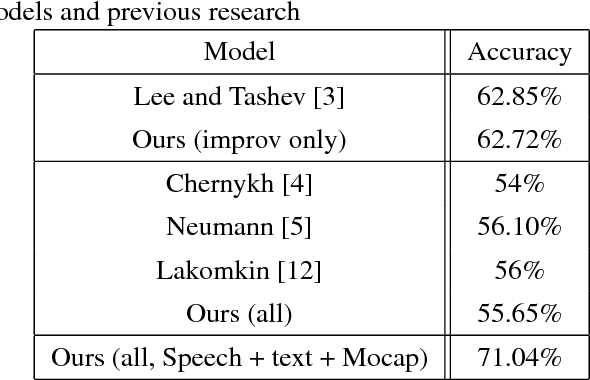
Emotion recognition has become an important field of research in Human Computer Interactions as we improve upon the techniques for modelling the various aspects of behaviour. With the advancement of technology our understanding of emotions are advancing, there is a growing need for automatic emotion recognition systems. One of the directions the research is heading is the use of Neural Networks which are adept at estimating complex functions that depend on a large number and diverse source of input data. In this paper we attempt to exploit this effectiveness of Neural networks to enable us to perform multimodal Emotion recognition on IEMOCAP dataset using data from Speech, Text, and Motion capture data from face expressions, rotation and hand movements. Prior research has concentrated on Emotion detection from Speech on the IEMOCAP dataset, but our approach is the first that uses the multiple modes of data offered by IEMOCAP for a more robust and accurate emotion detection.