 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing image captioning with depth information using a Transformer-based framework
Jul 24, 2023Captioning images is a challenging scene-understanding task that connects computer vision and natural language processing. While image captioning models have been successful in producing excellent descriptions, the field has primarily focused on generating a single sentence for 2D images. This paper investigates whether integrating depth information with RGB images can enhance the captioning task and generate better descriptions. For this purpose, we propose a Transformer-based encoder-decoder framework for generating a multi-sentence description of a 3D scene. The RGB image and its corresponding depth map are provided as inputs to our framework, which combines them to produce a better understanding of the input scene. Depth maps could be ground truth or estimated, which makes our framework widely applicable to any RGB captioning dataset. We explored different fusion approaches to fuse RGB and depth images. The experiments are performed on the NYU-v2 dataset and the Stanford image paragraph captioning dataset. During our work with the NYU-v2 dataset, we found inconsistent labeling that prevents the benefit of using depth information to enhance the captioning task. The results were even worse than using RGB images only. As a result, we propose a cleaned version of the NYU-v2 dataset that is more consistent and informative. Our results on both datasets demonstrate that the proposed framework effectively benefits from depth information, whether it is ground truth or estimated, and generates better captions. Code, pre-trained models, and the cleaned version of the NYU-v2 dataset will be made publically available.
No Shifted Augmentations (NSA): compact distributions for robust self-supervised Anomaly Detection
Mar 19, 2022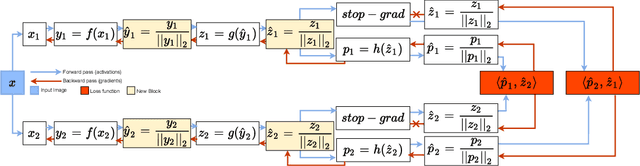
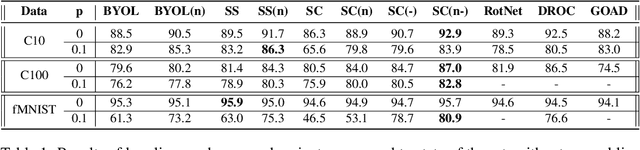
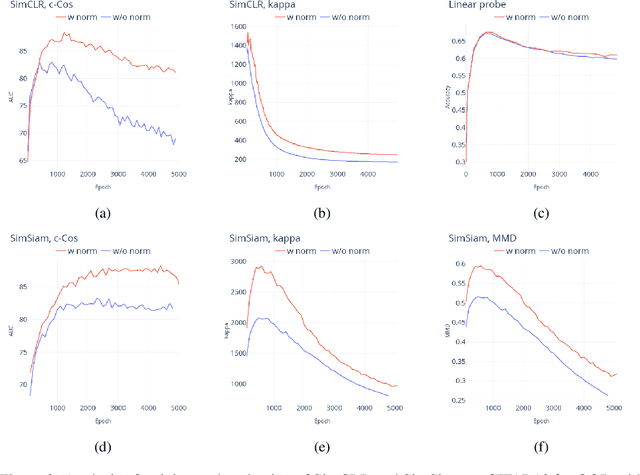
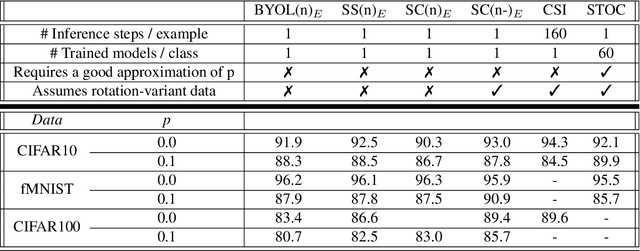
Unsupervised Anomaly detection (AD) requires building a notion of normalcy, distinguishing in-distribution (ID) and out-of-distribution (OOD) data, using only available ID samples. Recently, large gains were made on this task for the domain of natural images using self-supervised contrastive feature learning as a first step followed by kNN or traditional one-class classifiers for feature scoring. Learned representations that are non-uniformly distributed on the unit hypersphere have been shown to be beneficial for this task. We go a step further and investigate how the \emph {geometrical compactness} of the ID feature distribution makes isolating and detecting outliers easier, especially in the realistic situation when ID training data is polluted (i.e. ID data contains some OOD data that is used for learning the feature extractor parameters). We propose novel architectural modifications to the self-supervised feature learning step, that enable such compact distributions for ID data to be learned. We show that the proposed modifications can be effectively applied to most existing self-supervised objectives, with large gains in performance. Furthermore, this improved OOD performance is obtained without resorting to tricks such as using strongly augmented ID images (e.g. by 90 degree rotations) as proxies for the unseen OOD data, as these impose overly prescriptive assumptions about ID data and its invariances. We perform extensive studies on benchmark datasets for one-class OOD detection and show state-of-the-art performance in the presence of pollution in the ID data, and comparable performance otherwise. We also propose and extensively evaluate a novel feature scoring technique based on the angular Mahalanobis distance, and propose a simple and novel technique for feature ensembling during evaluation that enables a big boost in performance at nearly zero run-time cost.
OrigamiNet: Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by learning to unfold
Jun 12, 2020


Text recognition is a major computer vision task with a big set of associated challenges. One of those traditional challenges is the coupled nature of text recognition and segmentation. This problem has been progressively solved over the past decades, going from segmentation based recognition to segmentation free approaches, which proved more accurate and much cheaper to annotate data for. We take a step from segmentation-free single line recognition towards segmentation-free multi-line / full page recognition. We propose a novel and simple neural network module, termed \textbf{OrigamiNet}, that can augment any CTC-trained, fully convolutional single line text recognizer, to convert it into a multi-line version by providing the model with enough spatial capacity to be able to properly collapse a 2D input signal into 1D without losing information. Such modified networks can be trained using exactly their same simple original procedure, and using only \textbf{unsegmented} image and text pairs. We carry out a set of interpretability experiments that show that our trained models learn an accurate implicit line segmentation. We achieve state-of-the-art character error rate on both IAM \& ICDAR 2017 HTR benchmarks for handwriting recognition, surpassing all other methods in the literature. On IAM we even surpass single line methods that use accurate localization information during training. Our code is available online at \url{https://github.com/IntuitionMachines/OrigamiNet}.
Accurate, Data-Efficient, Unconstrained Text Recognition with Convolutional Neural Networks
Dec 31, 2018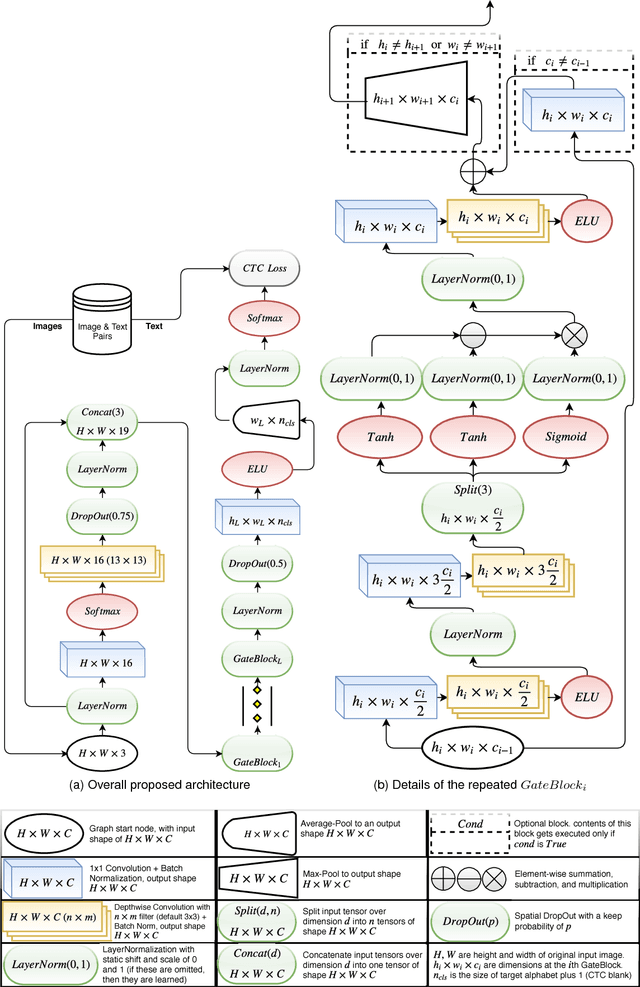
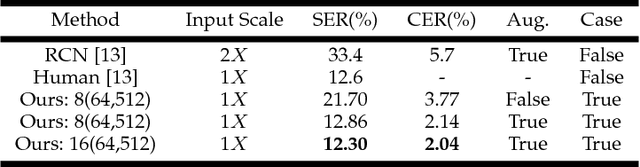
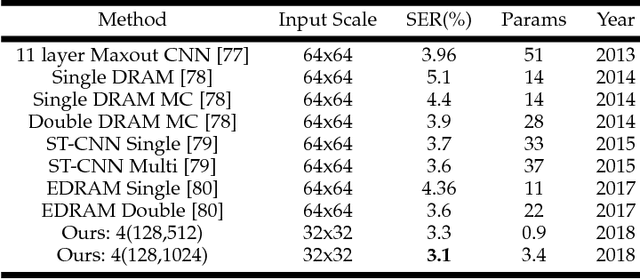
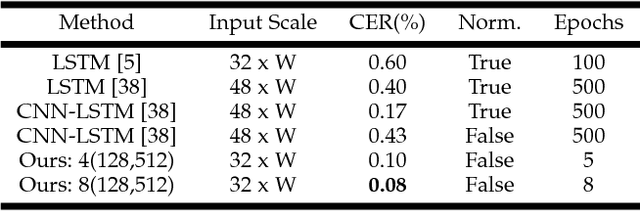
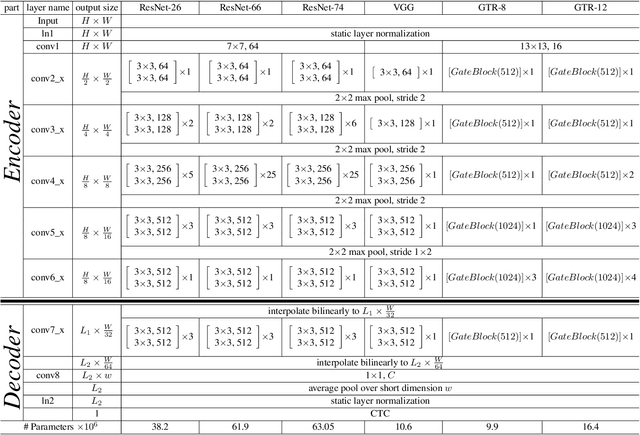
Unconstrained text recognition is an important computer vision task, featuring a wide variety of different sub-tasks, each with its own set of challenges. One of the biggest promises of deep neural networks has been the convergence and automation of feature extractors from input raw signals, allowing for the highest possible performance with minimum required domain knowledge. To this end, we propose a data-efficient, end-to-end neural network model for generic, unconstrained text recognition. In our proposed architecture we strive for simplicity and efficiency without sacrificing recognition accuracy. Our proposed architecture is a fully convolutional network without any recurrent connections trained with the CTC loss function. Thus it operates on arbitrary input sizes and produces strings of arbitrary length in a very efficient and parallelizable manner. We show the generality and superiority of our proposed text recognition architecture by achieving state of the art results on seven public benchmark datasets, covering a wide spectrum of text recognition tasks, namely: Handwriting Recognition, CAPTCHA recognition, OCR, License Plate Recognition, and Scene Text Recognition. Our proposed architecture has won the ICFHR2018 Competition on Automated Text Recognition on a READ Dataset.