 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing image captioning with depth information using a Transformer-based framework
Jul 24, 2023Captioning images is a challenging scene-understanding task that connects computer vision and natural language processing. While image captioning models have been successful in producing excellent descriptions, the field has primarily focused on generating a single sentence for 2D images. This paper investigates whether integrating depth information with RGB images can enhance the captioning task and generate better descriptions. For this purpose, we propose a Transformer-based encoder-decoder framework for generating a multi-sentence description of a 3D scene. The RGB image and its corresponding depth map are provided as inputs to our framework, which combines them to produce a better understanding of the input scene. Depth maps could be ground truth or estimated, which makes our framework widely applicable to any RGB captioning dataset. We explored different fusion approaches to fuse RGB and depth images. The experiments are performed on the NYU-v2 dataset and the Stanford image paragraph captioning dataset. During our work with the NYU-v2 dataset, we found inconsistent labeling that prevents the benefit of using depth information to enhance the captioning task. The results were even worse than using RGB images only. As a result, we propose a cleaned version of the NYU-v2 dataset that is more consistent and informative. Our results on both datasets demonstrate that the proposed framework effectively benefits from depth information, whether it is ground truth or estimated, and generates better captions. Code, pre-trained models, and the cleaned version of the NYU-v2 dataset will be made publically available.
Accurate, Data-Efficient, Unconstrained Text Recognition with Convolutional Neural Networks
Dec 31, 2018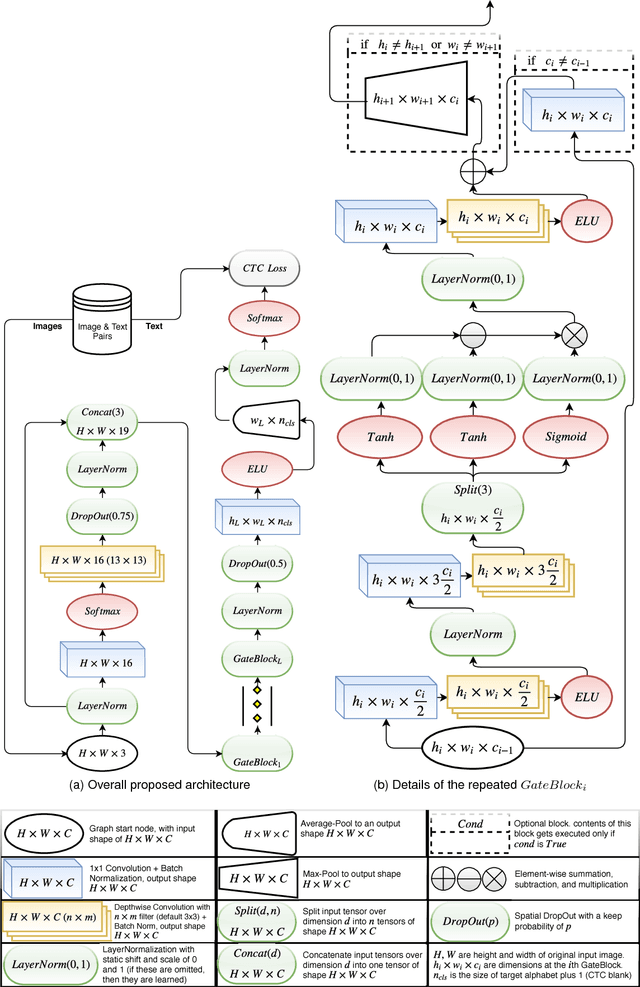
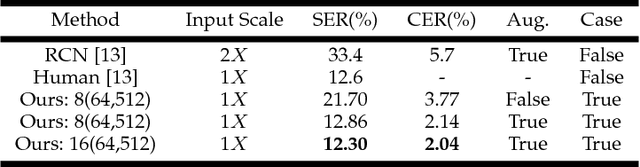
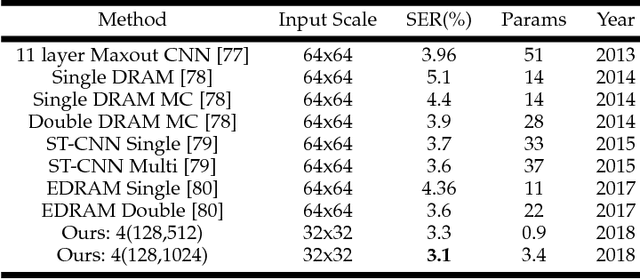
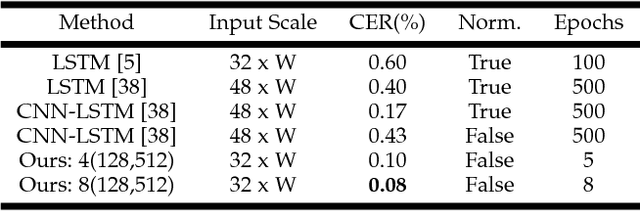
Unconstrained text recognition is an important computer vision task, featuring a wide variety of different sub-tasks, each with its own set of challenges. One of the biggest promises of deep neural networks has been the convergence and automation of feature extractors from input raw signals, allowing for the highest possible performance with minimum required domain knowledge. To this end, we propose a data-efficient, end-to-end neural network model for generic, unconstrained text recognition. In our proposed architecture we strive for simplicity and efficiency without sacrificing recognition accuracy. Our proposed architecture is a fully convolutional network without any recurrent connections trained with the CTC loss function. Thus it operates on arbitrary input sizes and produces strings of arbitrary length in a very efficient and parallelizable manner. We show the generality and superiority of our proposed text recognition architecture by achieving state of the art results on seven public benchmark datasets, covering a wide spectrum of text recognition tasks, namely: Handwriting Recognition, CAPTCHA recognition, OCR, License Plate Recognition, and Scene Text Recognition. Our proposed architecture has won the ICFHR2018 Competition on Automated Text Recognition on a READ Dataset.
The Achievement of Higher Flexibility in Multiple Choice-based Tests Using Image Classification Techniques
Aug 04, 2018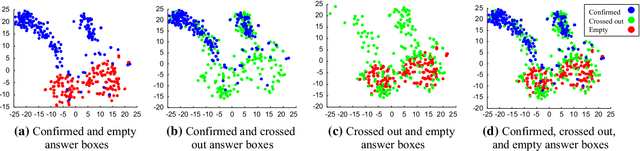
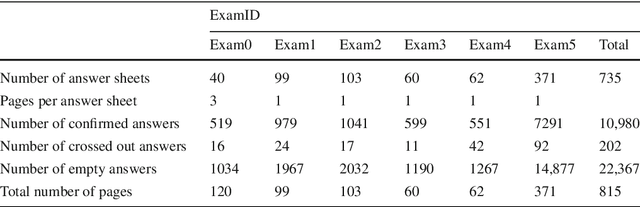
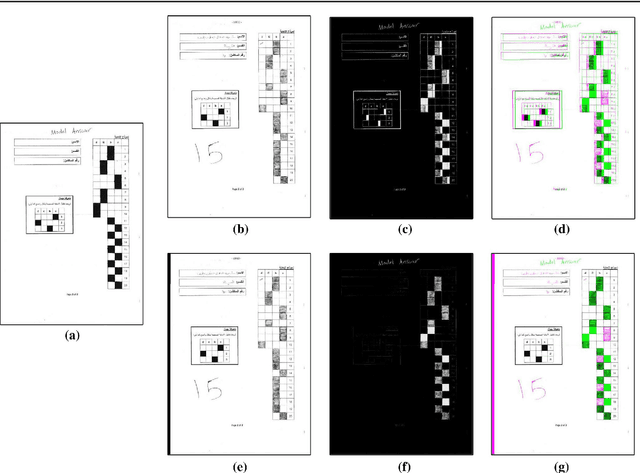
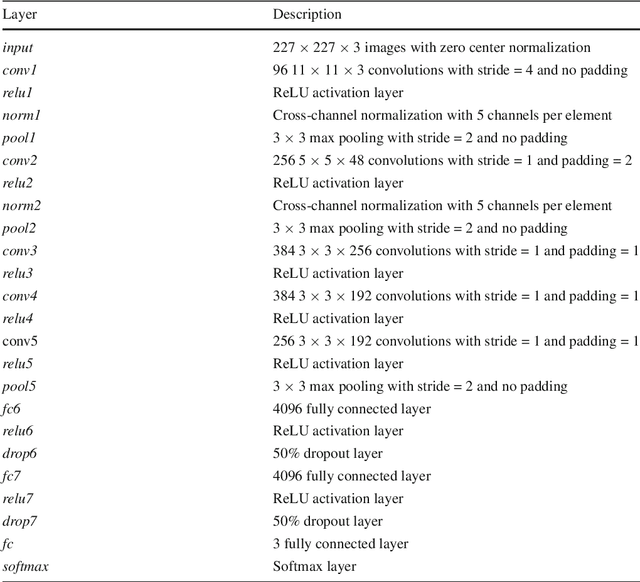
In spite of the high accuracy of the existing optical mark reading (OMR) systems and devices, a few restrictions remain existent. In this work, we aim to reduce the restrictions of multiple choice questions (MCQ) within tests. We use an image registration technique to extract the answer boxes from the answer sheets. Unlike other systems that rely on simple image processing steps to recognize the extracted answer boxes, we address the problem from another perspective by training a classifier to recognize the class of each answer box (i.e., confirmed, crossed out, and blank answer). This gives us the ability to deal with a variety of shading and mark patterns, and distinguish between chosen and canceled answers. All existing machine learning techniques require a large number of examples in order to train the classifier, therefore we present a dataset that consists of six real MCQ assessments that have different answer sheet templates. We evaluate two strategies of classification: a straight-forward approach and a two-stage classifier approach. We test two handcrafted feature methods and a convolutional neural network. At the end, we present an easy-to-use graphical user interface of the proposed system. Compared with existing OMR systems, the proposed system has a higher accuracy and the least constraints. We believe that the presented work will further direct the development of OMR systems towards reducing the restrictions of the MCQ tests.