 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Achievement of Higher Flexibility in Multiple Choice-based Tests Using Image Classification Techniques
Paper and Code
Aug 04, 2018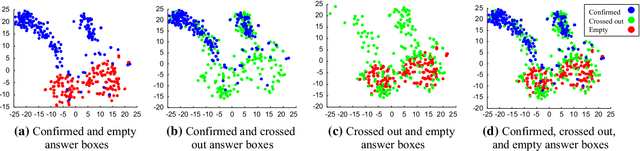
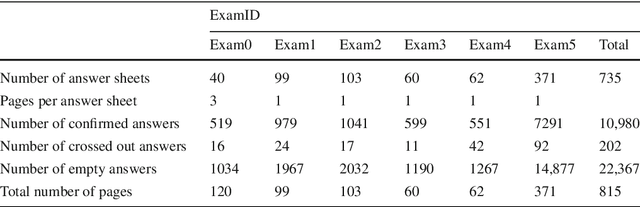
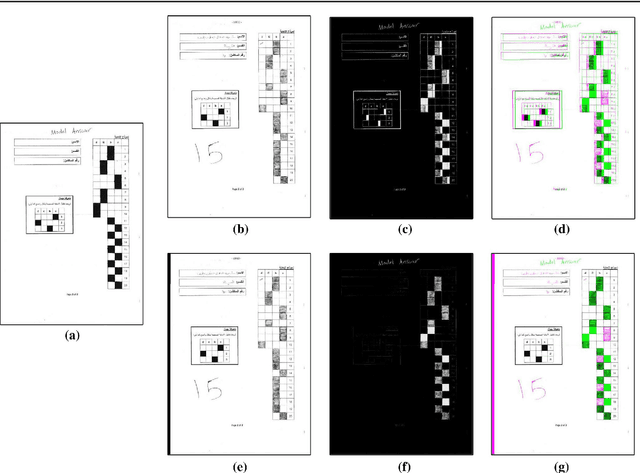
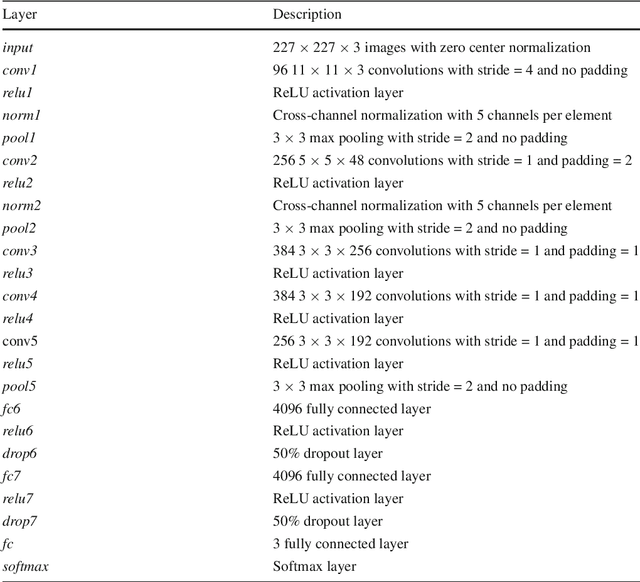
In spite of the high accuracy of the existing optical mark reading (OMR) systems and devices, a few restrictions remain existent. In this work, we aim to reduce the restrictions of multiple choice questions (MCQ) within tests. We use an image registration technique to extract the answer boxes from the answer sheets. Unlike other systems that rely on simple image processing steps to recognize the extracted answer boxes, we address the problem from another perspective by training a classifier to recognize the class of each answer box (i.e., confirmed, crossed out, and blank answer). This gives us the ability to deal with a variety of shading and mark patterns, and distinguish between chosen and canceled answers. All existing machine learning techniques require a large number of examples in order to train the classifier, therefore we present a dataset that consists of six real MCQ assessments that have different answer sheet templates. We evaluate two strategies of classification: a straight-forward approach and a two-stage classifier approach. We test two handcrafted feature methods and a convolutional neural network. At the end, we present an easy-to-use graphical user interface of the proposed system. Compared with existing OMR systems, the proposed system has a higher accuracy and the least constraints. We believe that the presented work will further direct the development of OMR systems towards reducing the restrictions of the MCQ tests.