 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation using Neural Feature Regression
Jun 01, 2022
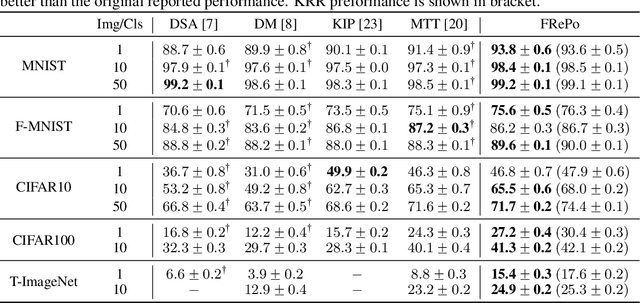
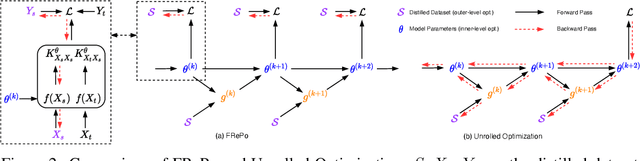

Dataset distillation aims to learn a small synthetic dataset that preserves most of the information from the original dataset. Dataset distillation can be formulated as a bi-level meta-learning problem where the outer loop optimizes the meta-dataset and the inner loop trains a model on the distilled data. Meta-gradient computation is one of the key challenges in this formulation, as differentiating through the inner loop learning procedure introduces significant computation and memory costs. In this paper, we address these challenges using neural Feature Regression with Pooling (FRePo), achieving the state-of-the-art performance with an order of magnitude less memory requirement and two orders of magnitude faster training than previous methods. The proposed algorithm is analogous to truncated backpropagation through time with a pool of models to alleviate various types of overfitting in dataset distillation. FRePo significantly outperforms the previous methods on CIFAR100, Tiny ImageNet, and ImageNet-1K. Furthermore, we show that high-quality distilled data can greatly improve various downstream applications, such as continual learning and membership inference defense.
Stochastic Whitening Batch Normalization
Jun 03, 2021
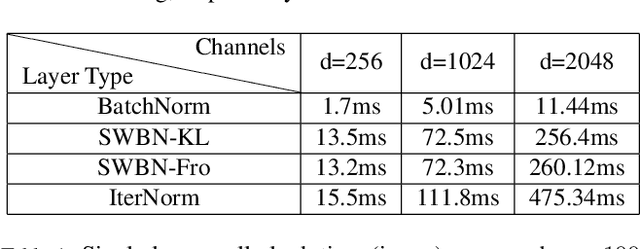

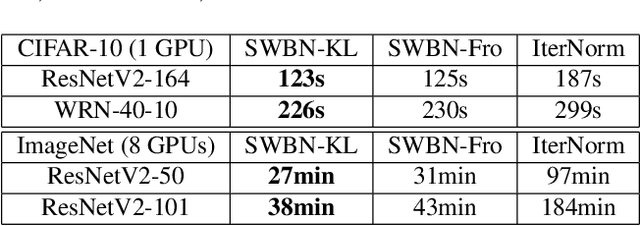
Batch Normalization (BN) is a popular technique for training Deep Neural Networks (DNNs). BN uses scaling and shifting to normalize activations of mini-batches to accelerate convergence and improve generalization. The recently proposed Iterative Normalization (IterNorm) method improves these properties by whitening the activations iteratively using Newton's method. However, since Newton's method initializes the whitening matrix independently at each training step, no information is shared between consecutive steps. In this work, instead of exact computation of whitening matrix at each time step, we estimate it gradually during training in an online fashion, using our proposed Stochastic Whitening Batch Normalization (SWBN) algorithm. We show that while SWBN improves the convergence rate and generalization of DNNs, its computational overhead is less than that of IterNorm. Due to the high efficiency of the proposed method, it can be easily employed in most DNN architectures with a large number of layers. We provide comprehensive experiments and comparisons between BN, IterNorm, and SWBN layers to demonstrate the effectiveness of the proposed technique in conventional (many-shot) image classification and few-shot classification tasks.
BoxNet: A Deep Learning Method for 2D Bounding Box Estimation from Bird's-Eye View Point Cloud
Aug 19, 2019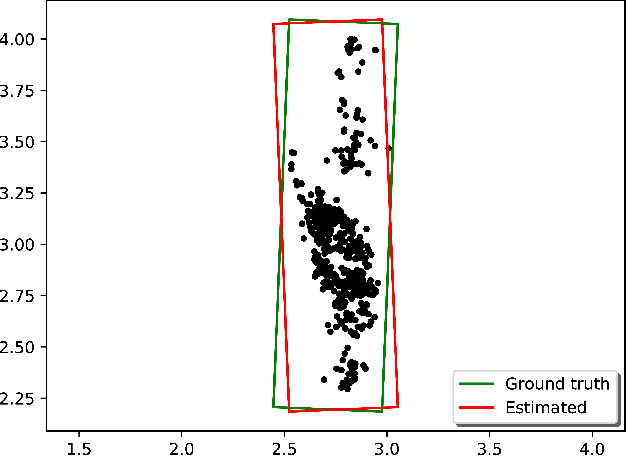
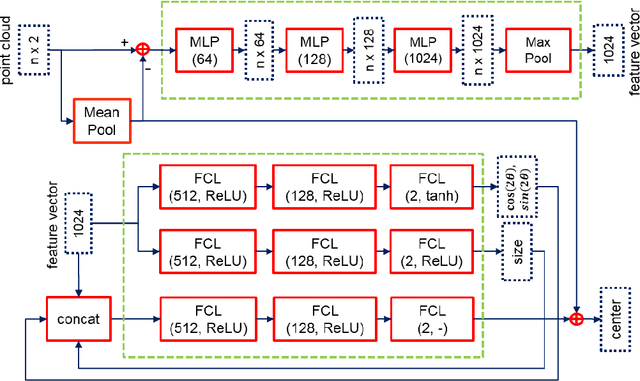
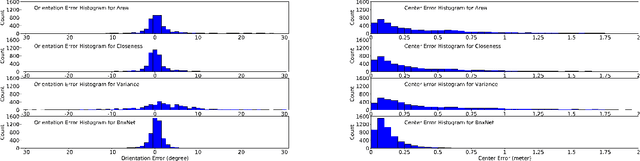
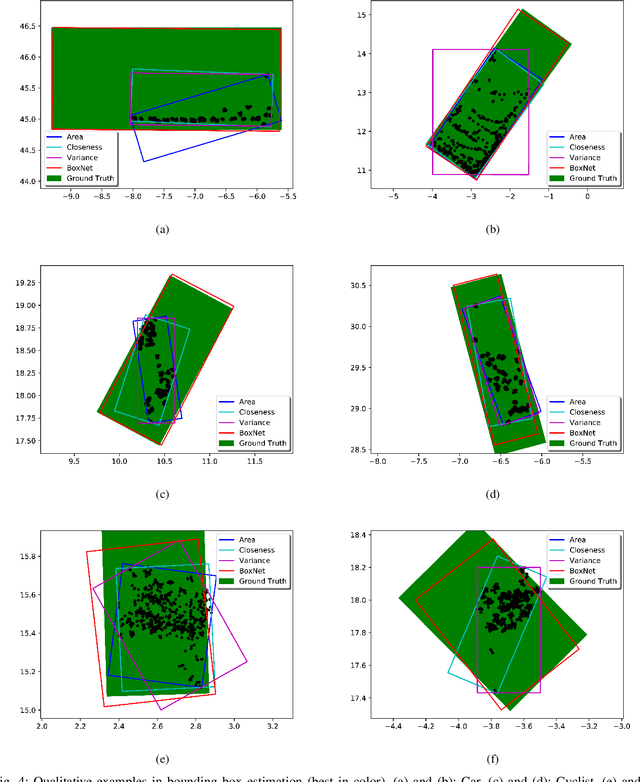
We present a learning-based method to estimate the object bounding box from its 2D bird's-eye view (BEV) LiDAR points. Our method, entitled BoxNet, exploits a simple deep neural network that can efficiently handle unordered points. The method takes as input the 2D coordinates of all the points and the output is a vector consisting of both the box pose (position and orientation in LiDAR coordinate system) and its size (width and length). In order to deal with the angle discontinuity problem, we propose to estimate the double-angle sinusoidal values rather than the angle itself. We also predict the center relative to the point cloud mean to boost the performance of estimating the location of the box. The proposed method does not rely on the ordering of points as in many existing approaches, and can accurately predict the actual size of the bounding box based on the prior information that is obtained from the training data. BoxNet is validated using the KITTI 3D object dataset, with significant improvement compared with the state-of-the-art non-learning based methods
Adaptive Hierarchical Down-Sampling for Point Cloud Classification
Apr 11, 2019
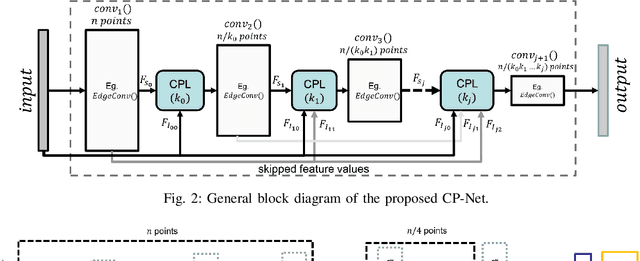


While several convolution-like operators have recently been proposed for extracting features out of point clouds, down-sampling an unordered point cloud in a deep neural network has not been rigorously studied. Existing methods down-sample the points regardless of their importance for the output. As a result, some important points in the point cloud may be removed, while less valuable points may be passed to the next layers. In contrast, adaptive down-sampling methods sample the points by taking into account the importance of each point, which varies based on the application, task and training data. In this paper, we propose a permutation-invariant learning-based adaptive down-sampling layer, called Critical Points Layer (CPL), which reduces the number of points in an unordered point cloud while retaining the important points. Unlike most graph-based point cloud down-sampling methods that use $k$-NN search algorithm to find the neighbouring points, CPL is a global down-sampling method, rendering it computationally very efficient. The proposed layer can be used along with any graph-based point cloud convolution layer to form a convolutional neural network, dubbed CP-Net in this paper. We introduce a CP-Net for $3$D object classification that achieves the best accuracy for the ModelNet$40$ dataset among point cloud-based methods, which validates the effectiveness of the CPL.
Sparse Representation-based Image Quality Assessment
Jun 12, 2013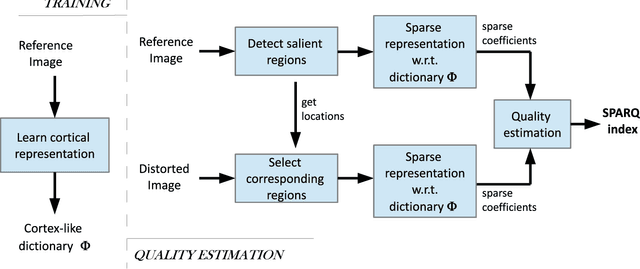

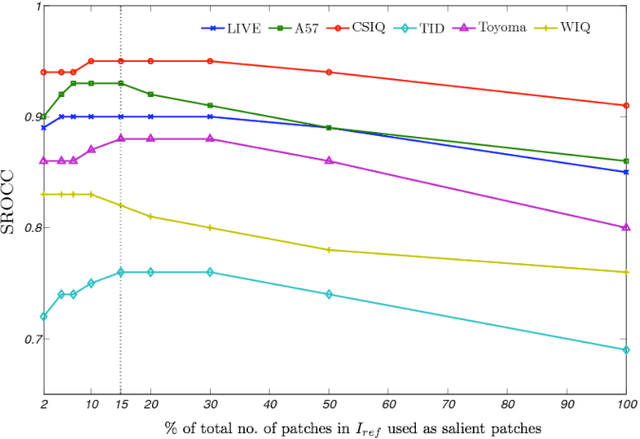
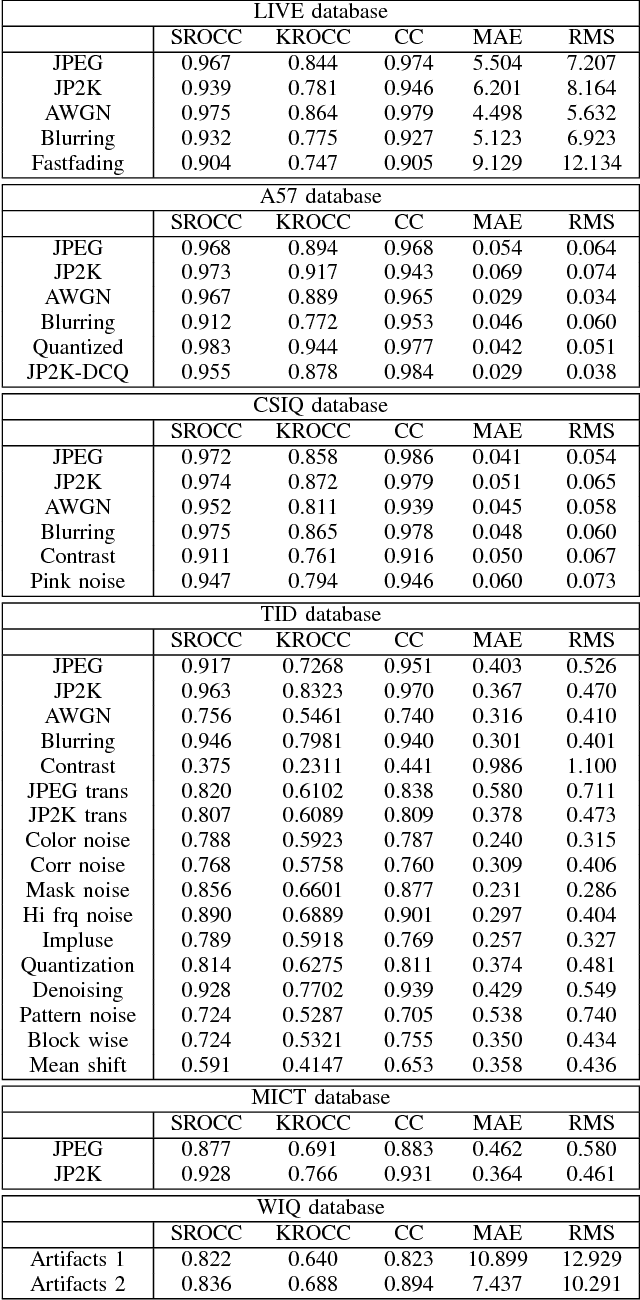
A successful approach to image quality assessment involves comparing the structural information between a distorted and its reference image. However, extracting structural information that is perceptually important to our visual system is a challenging task. This paper addresses this issue by employing a sparse representation-based approach and proposes a new metric called the \emph{sparse representation-based quality} (SPARQ) \emph{index}. The proposed method learns the inherent structures of the reference image as a set of basis vectors, such that any structure in the image can be represented by a linear combination of only a few of those basis vectors. This sparse strategy is employed because it is known to generate basis vectors that are qualitatively similar to the receptive field of the simple cells present in the mammalian primary visual cortex. The visual quality of the distorted image is estimated by comparing the structures of the reference and the distorted images in terms of the learnt basis vectors resembling cortical cells. Our approach is evaluated on six publicly available subject-rated image quality assessment datasets. The proposed SPARQ index consistently exhibits high correlation with the subjective ratings on all datasets and performs better or at par with the state-of-the-art.