 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-S3Net: Graph-based Panoptic Sparse Semantic Segmentation Network
Aug 18, 2021



Panoptic segmentation as an integrated task of both static environmental understanding and dynamic object identification, has recently begun to receive broad research interest. In this paper, we propose a new computationally efficient LiDAR based panoptic segmentation framework, called GP-S3Net. GP-S3Net is a proposal-free approach in which no object proposals are needed to identify the objects in contrast to conventional two-stage panoptic systems, where a detection network is incorporated for capturing instance information. Our new design consists of a novel instance-level network to process the semantic results by constructing a graph convolutional network to identify objects (foreground), which later on are fused with the background classes. Through the fine-grained clusters of the foreground objects from the semantic segmentation backbone, over-segmentation priors are generated and subsequently processed by 3D sparse convolution to embed each cluster. Each cluster is treated as a node in the graph and its corresponding embedding is used as its node feature. Then a GCNN predicts whether edges exist between each cluster pair. We utilize the instance label to generate ground truth edge labels for each constructed graph in order to supervise the learning. Extensive experiments demonstrate that GP-S3Net outperforms the current state-of-the-art approaches, by a significant margin across available datasets such as, nuScenes and SemanticPOSS, ranking first on the competitive public SemanticKITTI leaderboard upon publication.
Lite-HDSeg: LiDAR Semantic Segmentation Using Lite Harmonic Dense Convolutions
Mar 16, 2021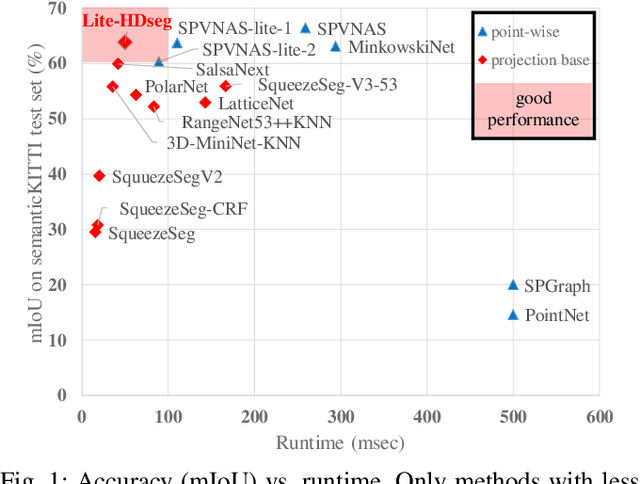
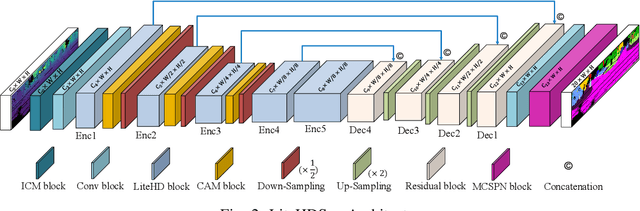
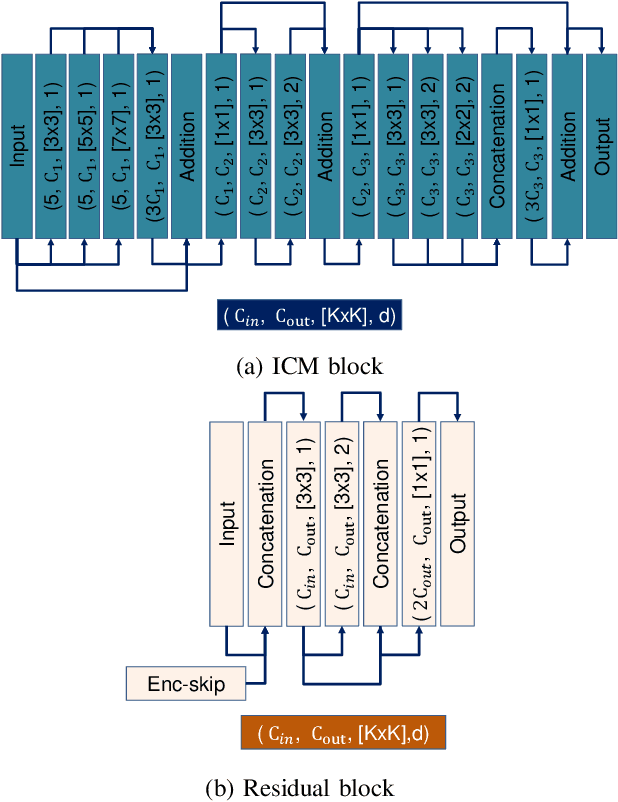
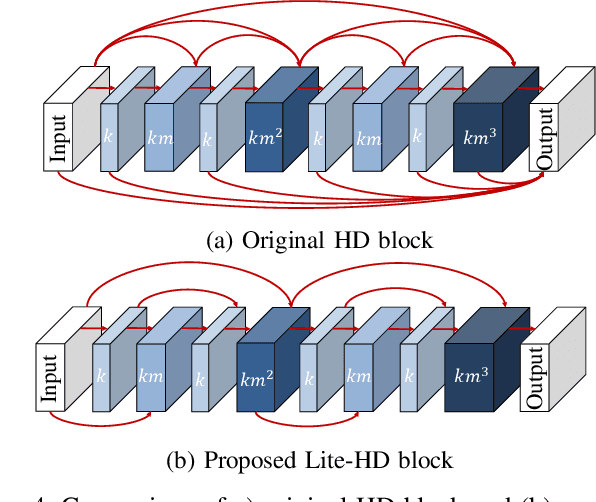
Autonomous driving vehicles and robotic systems rely on accurate perception of their surroundings. Scene understanding is one of the crucial components of perception modules. Among all available sensors, LiDARs are one of the essential sensing modalities of autonomous driving systems due to their active sensing nature with high resolution of sensor readings. Accurate and fast semantic segmentation methods are needed to fully utilize LiDAR sensors for scene understanding. In this paper, we present Lite-HDSeg, a novel real-time convolutional neural network for semantic segmentation of full $3$D LiDAR point clouds. Lite-HDSeg can achieve the best accuracy vs. computational complexity trade-off in SemanticKitti benchmark and is designed on the basis of a new encoder-decoder architecture with light-weight harmonic dense convolutions as its core. Moreover, we introduce ICM, an improved global contextual module to capture multi-scale contextual features, and MCSPN, a multi-class Spatial Propagation Network to further refine the semantic boundaries. Our experimental results show that the proposed method outperforms state-of-the-art semantic segmentation approaches which can run real-time, thus is suitable for robotic and autonomous driving applications.
(AF)2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network
Feb 08, 2021



Autonomous robotic systems and self driving cars rely on accurate perception of their surroundings as the safety of the passengers and pedestrians is the top priority. Semantic segmentation is one the essential components of environmental perception that provides semantic information of the scene. Recently, several methods have been introduced for 3D LiDAR semantic segmentation. While, they can lead to improved performance, they are either afflicted by high computational complexity, therefore are inefficient, or lack fine details of smaller instances. To alleviate this problem, we propose AF2-S3Net, an end-to-end encoder-decoder CNN network for 3D LiDAR semantic segmentation. We present a novel multi-branch attentive feature fusion module in the encoder and a unique adaptive feature selection module with feature map re-weighting in the decoder. Our AF2-S3Net fuses the voxel based learning and point-based learning into a single framework to effectively process the large 3D scene. Our experimental results show that the proposed method outperforms the state-of-the-art approaches on the large-scale SemanticKITTI benchmark, ranking 1st on the competitive public leaderboard competition upon publication.
TORNADO-Net: mulTiview tOtal vaRiatioN semAntic segmentation with Diamond inceptiOn module
Aug 24, 2020



Semantic segmentation of point clouds is a key component of scene understanding for robotics and autonomous driving. In this paper, we introduce TORNADO-Net - a neural network for 3D LiDAR point cloud semantic segmentation. We incorporate a multi-view (bird-eye and range) projection feature extraction with an encoder-decoder ResNet architecture with a novel diamond context block. Current projection-based methods do not take into account that neighboring points usually belong to the same class. To better utilize this local neighbourhood information and reduce noisy predictions, we introduce a combination of Total Variation, Lovasz-Softmax, and Weighted Cross-Entropy losses. We also take advantage of the fact that the LiDAR data encompasses 360 degrees field of view and uses circular padding. We demonstrate state-of-the-art results on the SemanticKITTI dataset and also provide thorough quantitative evaluations and ablation results.
Adaptive Hierarchical Down-Sampling for Point Cloud Classification
Apr 11, 2019
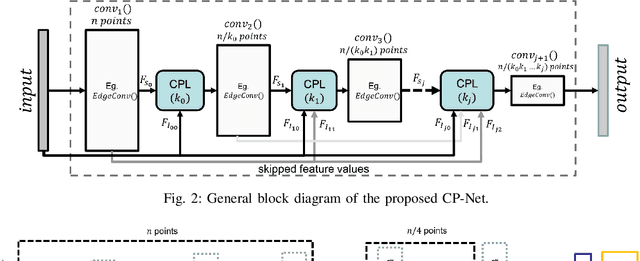


While several convolution-like operators have recently been proposed for extracting features out of point clouds, down-sampling an unordered point cloud in a deep neural network has not been rigorously studied. Existing methods down-sample the points regardless of their importance for the output. As a result, some important points in the point cloud may be removed, while less valuable points may be passed to the next layers. In contrast, adaptive down-sampling methods sample the points by taking into account the importance of each point, which varies based on the application, task and training data. In this paper, we propose a permutation-invariant learning-based adaptive down-sampling layer, called Critical Points Layer (CPL), which reduces the number of points in an unordered point cloud while retaining the important points. Unlike most graph-based point cloud down-sampling methods that use $k$-NN search algorithm to find the neighbouring points, CPL is a global down-sampling method, rendering it computationally very efficient. The proposed layer can be used along with any graph-based point cloud convolution layer to form a convolutional neural network, dubbed CP-Net in this paper. We introduce a CP-Net for $3$D object classification that achieves the best accuracy for the ModelNet$40$ dataset among point cloud-based methods, which validates the effectiveness of the CPL.