 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-Level 3D Gaussian Vehicle Generation with Joint and Hinge Axis Estimation
Apr 06, 2026Simulation is essential for autonomous driving, yet current frameworks often model vehicles as rigid assets and fail to capture part-level articulation. With perception algorithms increasingly leveraging dynamics such as wheel steering or door opening, realistic simulation requires animatable vehicle representations. Existing CAD-based pipelines are limited by library coverage and fixed templates, preventing faithful reconstruction of in-the-wild instances. We propose a generative framework that, from a single image or sparse multi-view input, synthesizes an animatable 3D Gaussian vehicle. Our method addresses two challenges: (i) large 3D asset generators are optimized for static quality but not articulation, leading to distortions at part boundaries when animated; and (ii) segmentation alone cannot provide the kinematic parameters required for motion. To overcome this, we introduce a part-edge refinement module that enforces exclusive Gaussian ownership and a kinematic reasoning head that predicts joint positions and hinge axes of movable parts. Together, these components enable faithful part-aware simulation, bridging the gap between static generation and animatable vehicle models.
UniScale: Unified Scale-Aware 3D Reconstruction for Multi-View Understanding via Prior Injection for Robotic Perception
Feb 26, 2026We present UniScale, a unified, scale-aware multi-view 3D reconstruction framework for robotic applications that flexibly integrates geometric priors through a modular, semantically informed design. In vision-based robotic navigation, the accurate extraction of environmental structure from raw image sequences is critical for downstream tasks. UniScale addresses this challenge with a single feed-forward network that jointly estimates camera intrinsics and extrinsics, scale-invariant depth and point maps, and the metric scale of a scene from multi-view images, while optionally incorporating auxiliary geometric priors when available. By combining global contextual reasoning with camera-aware feature representations, UniScale is able to recover the metric-scale of the scene. In robotic settings where camera intrinsics are known, they can be easily incorporated to improve performance, with additional gains obtained when camera poses are also available. This co-design enables robust, metric-aware 3D reconstruction within a single unified model. Importantly, UniScale does not require training from scratch, and leverages world priors exhibited in pre-existing models without geometric encoding strategies, making it particularly suitable for resource-constrained robotic teams. We evaluate UniScale on multiple benchmarks, demonstrating strong generalization and consistent performance across diverse environments. We will release our implementation upon acceptance.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
Binary Weight Multi-Bit Activation Quantization for Compute-in-Memory CNN Accelerators
Aug 29, 2025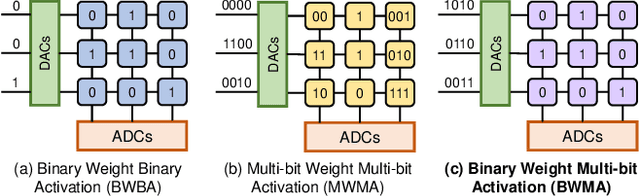
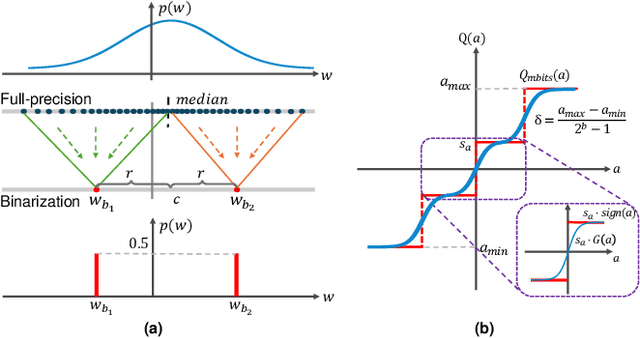
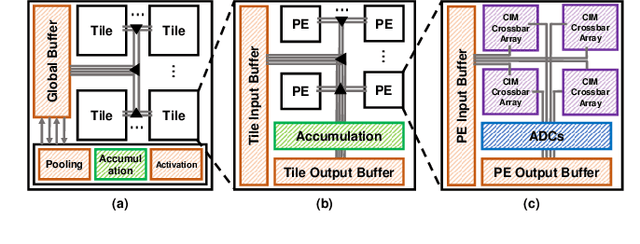
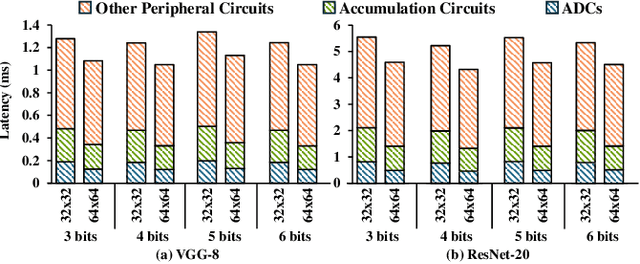
Compute-in-memory (CIM) accelerators have emerged as a promising way for enhancing the energy efficiency of convolutional neural networks (CNNs). Deploying CNNs on CIM platforms generally requires quantization of network weights and activations to meet hardware constraints. However, existing approaches either prioritize hardware efficiency with binary weight and activation quantization at the cost of accuracy, or utilize multi-bit weights and activations for greater accuracy but limited efficiency. In this paper, we introduce a novel binary weight multi-bit activation (BWMA) method for CNNs on CIM-based accelerators. Our contributions include: deriving closed-form solutions for weight quantization in each layer, significantly improving the representational capabilities of binarized weights; and developing a differentiable function for activation quantization, approximating the ideal multi-bit function while bypassing the extensive search for optimal settings. Through comprehensive experiments on CIFAR-10 and ImageNet datasets, we show that BWMA achieves notable accuracy improvements over existing methods, registering gains of 1.44\%-5.46\% and 0.35\%-5.37\% on respective datasets. Moreover, hardware simulation results indicate that 4-bit activation quantization strikes the optimal balance between hardware cost and model performance.
UniGaussian: Driving Scene Reconstruction from Multiple Camera Models via Unified Gaussian Representations
Nov 22, 2024



Urban scene reconstruction is crucial for real-world autonomous driving simulators. Although existing methods have achieved photorealistic reconstruction, they mostly focus on pinhole cameras and neglect fisheye cameras. In fact, how to effectively simulate fisheye cameras in driving scene remains an unsolved problem. In this work, we propose UniGaussian, a novel approach that learns a unified 3D Gaussian representation from multiple camera models for urban scene reconstruction in autonomous driving. Our contributions are two-fold. First, we propose a new differentiable rendering method that distorts 3D Gaussians using a series of affine transformations tailored to fisheye camera models. This addresses the compatibility issue of 3D Gaussian splatting with fisheye cameras, which is hindered by light ray distortion caused by lenses or mirrors. Besides, our method maintains real-time rendering while ensuring differentiability. Second, built on the differentiable rendering method, we design a new framework that learns a unified Gaussian representation from multiple camera models. By applying affine transformations to adapt different camera models and regularizing the shared Gaussians with supervision from different modalities, our framework learns a unified 3D Gaussian representation with input data from multiple sources and achieves holistic driving scene understanding. As a result, our approach models multiple sensors (pinhole and fisheye cameras) and modalities (depth, semantic, normal and LiDAR point clouds). Our experiments show that our method achieves superior rendering quality and fast rendering speed for driving scene simulation.
3DArticCyclists: Generating Simulated Dynamic 3D Cyclists for Human-Object Interaction (HOI) and Autonomous Driving Applications
Oct 14, 2024



Human-object interaction (HOI) and human-scene interaction (HSI) are crucial for human-centric scene understanding applications in Embodied Artificial Intelligence (EAI), robotics, and augmented reality (AR). A common limitation faced in these research areas is the data scarcity problem: insufficient labeled human-scene object pairs on the input images, and limited interaction complexity and granularity between them. Recent HOI and HSI methods have addressed this issue by generating dynamic interactions with rigid objects. But more complex dynamic interactions such as a human rider pedaling an articulated bicycle have been unexplored. To address this limitation, and to enable research on complex dynamic human-articulated object interactions, in this paper we propose a method to generate simulated 3D dynamic cyclist assets and interactions. We designed a methodology for creating a new part-based multi-view articulated synthetic 3D bicycle dataset that we call 3DArticBikes that can be used to train NeRF and 3DGS-based 3D reconstruction methods. We then propose a 3DGS-based parametric bicycle composition model to assemble 8-DoF pose-controllable 3D bicycles. Finally, using dynamic information from cyclist videos, we build a complete synthetic dynamic 3D cyclist (rider pedaling a bicycle) by re-posing a selectable synthetic 3D person while automatically placing the rider onto one of our new articulated 3D bicycles using a proposed 3D Keypoint optimization-based Inverse Kinematics pose refinement. We present both, qualitative and quantitative results where we compare our generated cyclists against those from a recent stable diffusion-based method.
Uplifting Range-View-based 3D Semantic Segmentation in Real-Time with Multi-Sensor Fusion
Jul 12, 2024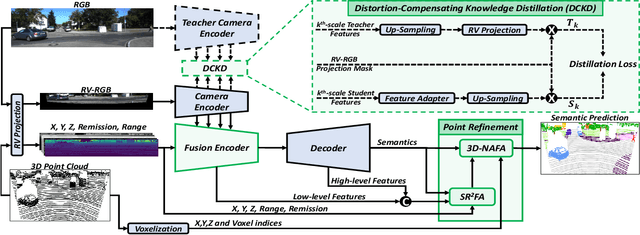
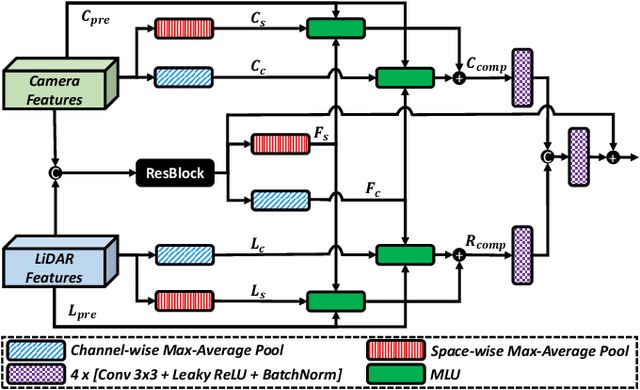
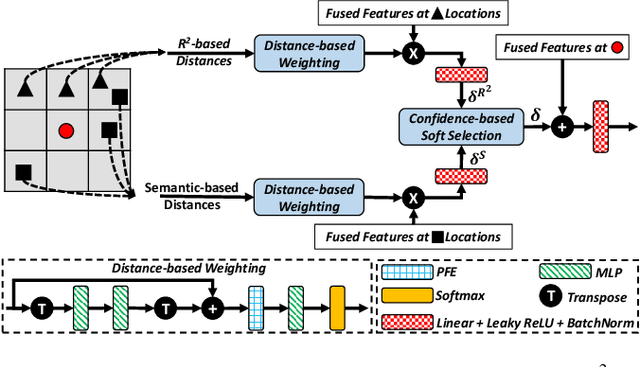
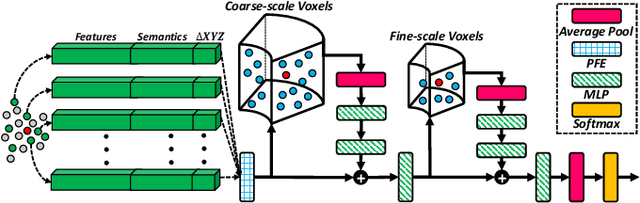
Range-View(RV)-based 3D point cloud segmentation is widely adopted due to its compact data form. However, RV-based methods fall short in providing robust segmentation for the occluded points and suffer from distortion of projected RGB images due to the sparse nature of 3D point clouds. To alleviate these problems, we propose a new LiDAR and Camera Range-view-based 3D point cloud semantic segmentation method (LaCRange). Specifically, a distortion-compensating knowledge distillation (DCKD) strategy is designed to remedy the adverse effect of RV projection of RGB images. Moreover, a context-based feature fusion module is introduced for robust and preservative sensor fusion. Finally, in order to address the limited resolution of RV and its insufficiency of 3D topology, a new point refinement scheme is devised for proper aggregation of features in 2D and augmentation of point features in 3D. We evaluated the proposed method on large-scale autonomous driving datasets \ie SemanticKITTI and nuScenes. In addition to being real-time, the proposed method achieves state-of-the-art results on nuScenes benchmark
VQA-Diff: Exploiting VQA and Diffusion for Zero-Shot Image-to-3D Vehicle Asset Generation in Autonomous Driving
Jul 10, 2024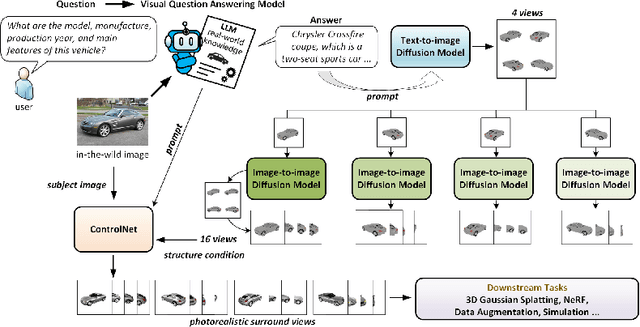
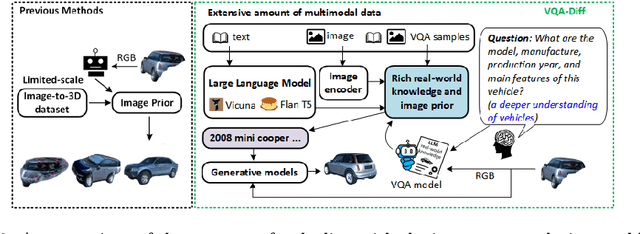
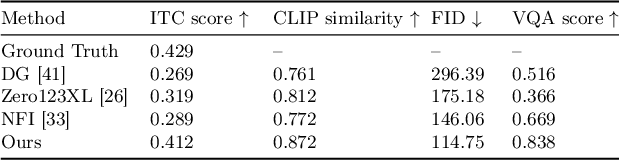
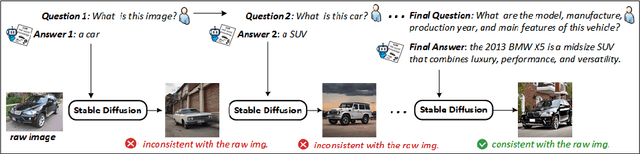
Generating 3D vehicle assets from in-the-wild observations is crucial to autonomous driving. Existing image-to-3D methods cannot well address this problem because they learn generation merely from image RGB information without a deeper understanding of in-the-wild vehicles (such as car models, manufacturers, etc.). This leads to their poor zero-shot prediction capability to handle real-world observations with occlusion or tricky viewing angles. To solve this problem, in this work, we propose VQA-Diff, a novel framework that leverages in-the-wild vehicle images to create photorealistic 3D vehicle assets for autonomous driving. VQA-Diff exploits the real-world knowledge inherited from the Large Language Model in the Visual Question Answering (VQA) model for robust zero-shot prediction and the rich image prior knowledge in the Diffusion model for structure and appearance generation. In particular, we utilize a multi-expert Diffusion Models strategy to generate the structure information and employ a subject-driven structure-controlled generation mechanism to model appearance information. As a result, without the necessity to learn from a large-scale image-to-3D vehicle dataset collected from the real world, VQA-Diff still has a robust zero-shot image-to-novel-view generation ability. We conduct experiments on various datasets, including Pascal 3D+, Waymo, and Objaverse, to demonstrate that VQA-Diff outperforms existing state-of-the-art methods both qualitatively and quantitatively.
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
Jul 02, 2024



Realistic scene reconstruction and view synthesis are essential for advancing autonomous driving systems by simulating safety-critical scenarios. 3D Gaussian Splatting excels in real-time rendering and static scene reconstructions but struggles with modeling driving scenarios due to complex backgrounds, dynamic objects, and sparse views. We propose AutoSplat, a framework employing Gaussian splatting to achieve highly realistic reconstructions of autonomous driving scenes. By imposing geometric constraints on Gaussians representing the road and sky regions, our method enables multi-view consistent simulation of challenging scenarios including lane changes. Leveraging 3D templates, we introduce a reflected Gaussian consistency constraint to supervise both the visible and unseen side of foreground objects. Moreover, to model the dynamic appearance of foreground objects, we estimate residual spherical harmonics for each foreground Gaussian. Extensive experiments on Pandaset and KITTI demonstrate that AutoSplat outperforms state-of-the-art methods in scene reconstruction and novel view synthesis across diverse driving scenarios. Visit our $\href{https://autosplat.github.io/}{\text{project page}}$.
Outlier-Aware Training for Low-Bit Quantization of Structural Re-Parameterized Networks
Feb 11, 2024



Lightweight design of Convolutional Neural Networks (CNNs) requires co-design efforts in the model architectures and compression techniques. As a novel design paradigm that separates training and inference, a structural re-parameterized (SR) network such as the representative RepVGG revitalizes the simple VGG-like network with a high accuracy comparable to advanced and often more complicated networks. However, the merging process in SR networks introduces outliers into weights, making their distribution distinct from conventional networks and thus heightening difficulties in quantization. To address this, we propose an operator-level improvement for training called Outlier Aware Batch Normalization (OABN). Additionally, to meet the demands of limited bitwidths while upkeeping the inference accuracy, we develop a clustering-based non-uniform quantization framework for Quantization-Aware Training (QAT) named ClusterQAT. Integrating OABN with ClusterQAT, the quantized performance of RepVGG is largely enhanced, particularly when the bitwidth falls below 8.