 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
3DArticCyclists: Generating Simulated Dynamic 3D Cyclists for Human-Object Interaction (HOI) and Autonomous Driving Applications
Oct 14, 2024



Human-object interaction (HOI) and human-scene interaction (HSI) are crucial for human-centric scene understanding applications in Embodied Artificial Intelligence (EAI), robotics, and augmented reality (AR). A common limitation faced in these research areas is the data scarcity problem: insufficient labeled human-scene object pairs on the input images, and limited interaction complexity and granularity between them. Recent HOI and HSI methods have addressed this issue by generating dynamic interactions with rigid objects. But more complex dynamic interactions such as a human rider pedaling an articulated bicycle have been unexplored. To address this limitation, and to enable research on complex dynamic human-articulated object interactions, in this paper we propose a method to generate simulated 3D dynamic cyclist assets and interactions. We designed a methodology for creating a new part-based multi-view articulated synthetic 3D bicycle dataset that we call 3DArticBikes that can be used to train NeRF and 3DGS-based 3D reconstruction methods. We then propose a 3DGS-based parametric bicycle composition model to assemble 8-DoF pose-controllable 3D bicycles. Finally, using dynamic information from cyclist videos, we build a complete synthetic dynamic 3D cyclist (rider pedaling a bicycle) by re-posing a selectable synthetic 3D person while automatically placing the rider onto one of our new articulated 3D bicycles using a proposed 3D Keypoint optimization-based Inverse Kinematics pose refinement. We present both, qualitative and quantitative results where we compare our generated cyclists against those from a recent stable diffusion-based method.
Improving LiDAR 3D Object Detection via Range-based Point Cloud Density Optimization
Jun 09, 2023In recent years, much progress has been made in LiDAR-based 3D object detection mainly due to advances in detector architecture designs and availability of large-scale LiDAR datasets. Existing 3D object detectors tend to perform well on the point cloud regions closer to the LiDAR sensor as opposed to on regions that are farther away. In this paper, we investigate this problem from the data perspective instead of detector architecture design. We observe that there is a learning bias in detection models towards the dense objects near the sensor and show that the detection performance can be improved by simply manipulating the input point cloud density at different distance ranges without modifying the detector architecture and without data augmentation. We propose a model-free point cloud density adjustment pre-processing mechanism that uses iterative MCMC optimization to estimate optimal parameters for altering the point density at different distance ranges. We conduct experiments using four state-of-the-art LiDAR 3D object detectors on two public LiDAR datasets, namely Waymo and ONCE. Our results demonstrate that our range-based point cloud density manipulation technique can improve the performance of the existing detectors, which in turn could potentially inspire future detector designs.
Domain Adaptation in 3D Object Detection with Gradual Batch Alternation Training
Oct 18, 2022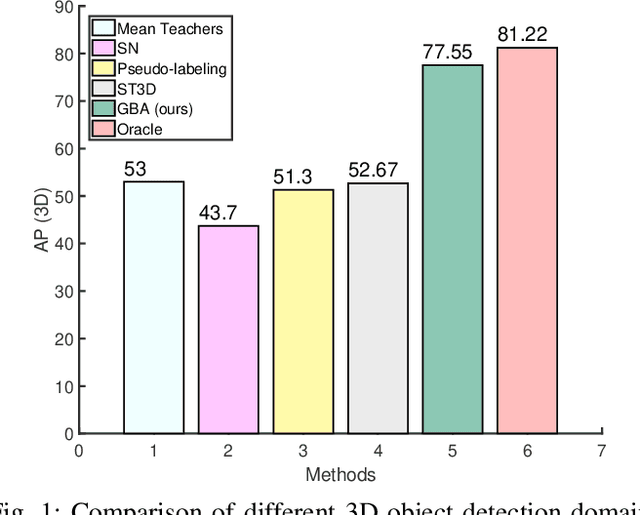
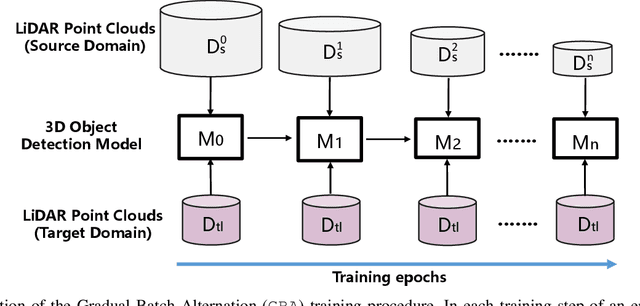
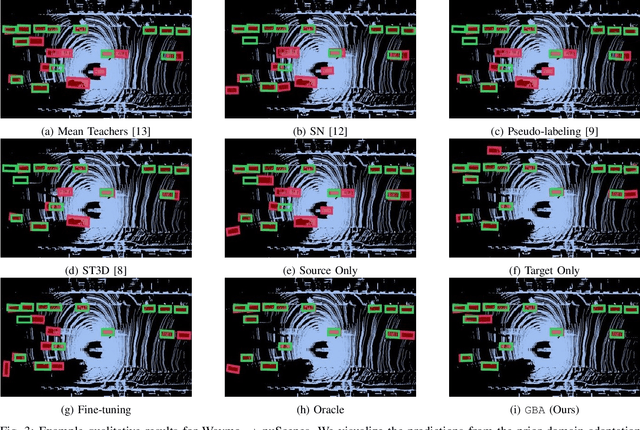
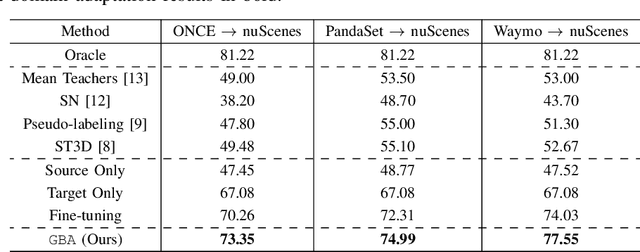
We consider the problem of domain adaptation in LiDAR-based 3D object detection. Towards this, we propose a simple yet effective training strategy called Gradual Batch Alternation that can adapt from a large labeled source domain to an insufficiently labeled target domain. The idea is to initiate the training with the batch of samples from the source and target domain data in an alternate fashion, but then gradually reduce the amount of the source domain data over time as the training progresses. This way the model slowly shifts towards the target domain and eventually better adapt to it. The domain adaptation experiments for 3D object detection on four benchmark autonomous driving datasets, namely ONCE, PandaSet, Waymo, and nuScenes, demonstrate significant performance gains over prior arts and strong baselines.
HYLDA: End-to-end Hybrid Learning Domain Adaptation for LiDAR Semantic Segmentation
Jan 14, 2022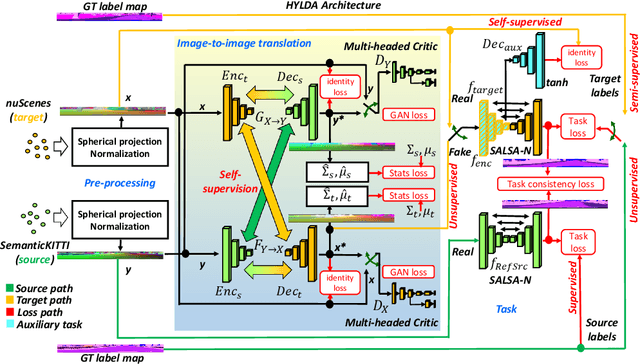
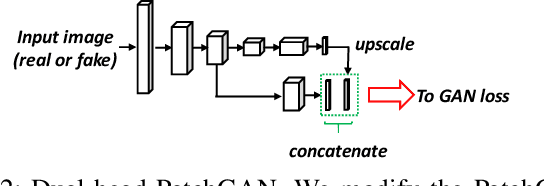

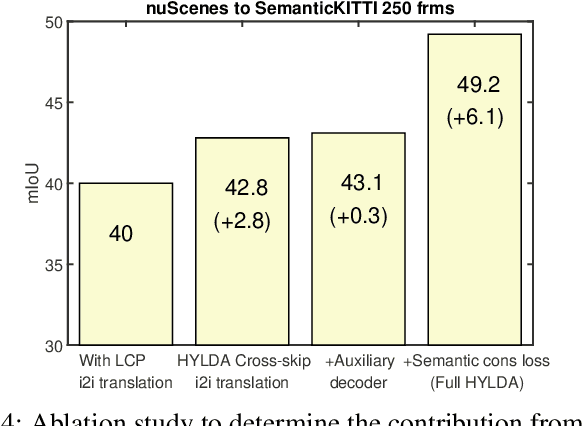
In this paper we address the problem of training a LiDAR semantic segmentation network using a fully-labeled source dataset and a target dataset that only has a small number of labels. To this end, we develop a novel image-to-image translation engine, and couple it with a LiDAR semantic segmentation network, resulting in an integrated domain adaptation architecture we call HYLDA. To train the system end-to-end, we adopt a diverse set of learning paradigms, including 1) self-supervision on a simple auxiliary reconstruction task, 2) semi-supervised training using a few available labeled target domain frames, and 3) unsupervised training on the fake translated images generated by the image-to-image translation stage, together with the labeled frames from the source domain. In the latter case, the semantic segmentation network participates in the updating of the image-to-image translation engine. We demonstrate experimentally that HYLDA effectively addresses the challenging problem of improving generalization on validation data from the target domain when only a few target labeled frames are available for training. We perform an extensive evaluation where we compare HYLDA against strong baseline methods using two publicly available LiDAR semantic segmentation datasets.
Unsupervised Domain Adaptation in LiDAR Semantic Segmentation with Self-Supervision and Gated Adapters
Jul 20, 2021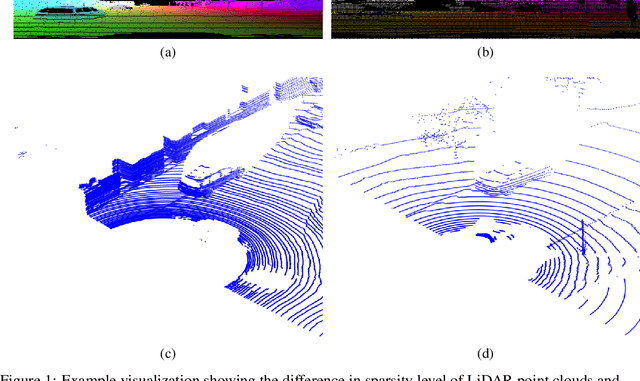
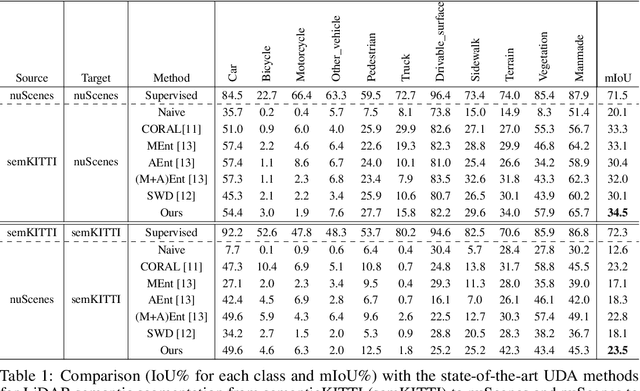
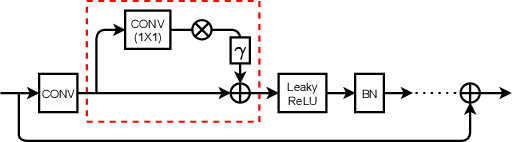
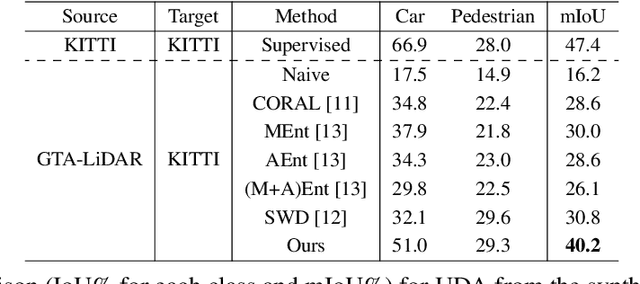
In this paper, we focus on a less explored, but more realistic and complex problem of domain adaptation in LiDAR semantic segmentation. There is a significant drop in performance of an existing segmentation model when training (source domain) and testing (target domain) data originate from different LiDAR sensors. To overcome this shortcoming, we propose an unsupervised domain adaptation framework that leverages unlabeled target domain data for self-supervision, coupled with an unpaired mask transfer strategy to mitigate the impact of domain shifts. Furthermore, we introduce gated adapter modules with a small number of parameters into the network to account for target domain-specific information. Experiments adapting from both real-to-real and synthetic-to-real LiDAR semantic segmentation benchmarks demonstrate the significant improvement over prior arts.