 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTART: Token-based Architecture Transformer for Neural Network Performance Prediction
Jan 02, 2025



In the realm of neural architecture design, achieving high performance is largely reliant on the manual expertise of researchers. Despite the emergence of Neural Architecture Search (NAS) as a promising technique for automating this process, current NAS methods still require human input to expand the search space and cannot generate new architectures. This paper explores the potential of Transformers in comprehending neural architectures and their performance, with the objective of establishing the foundation for utilizing Transformers to generate novel networks. We propose the Token-based Architecture Transformer (TART), which predicts neural network performance without the need to train candidate networks. TART attains state-of-the-art performance on the DeepNets-1M dataset for performance prediction tasks without edge information, indicating the potential of Transformers to aid in discovering novel and high-performing neural architectures.
Improving LiDAR 3D Object Detection via Range-based Point Cloud Density Optimization
Jun 09, 2023In recent years, much progress has been made in LiDAR-based 3D object detection mainly due to advances in detector architecture designs and availability of large-scale LiDAR datasets. Existing 3D object detectors tend to perform well on the point cloud regions closer to the LiDAR sensor as opposed to on regions that are farther away. In this paper, we investigate this problem from the data perspective instead of detector architecture design. We observe that there is a learning bias in detection models towards the dense objects near the sensor and show that the detection performance can be improved by simply manipulating the input point cloud density at different distance ranges without modifying the detector architecture and without data augmentation. We propose a model-free point cloud density adjustment pre-processing mechanism that uses iterative MCMC optimization to estimate optimal parameters for altering the point density at different distance ranges. We conduct experiments using four state-of-the-art LiDAR 3D object detectors on two public LiDAR datasets, namely Waymo and ONCE. Our results demonstrate that our range-based point cloud density manipulation technique can improve the performance of the existing detectors, which in turn could potentially inspire future detector designs.
HYLDA: End-to-end Hybrid Learning Domain Adaptation for LiDAR Semantic Segmentation
Jan 14, 2022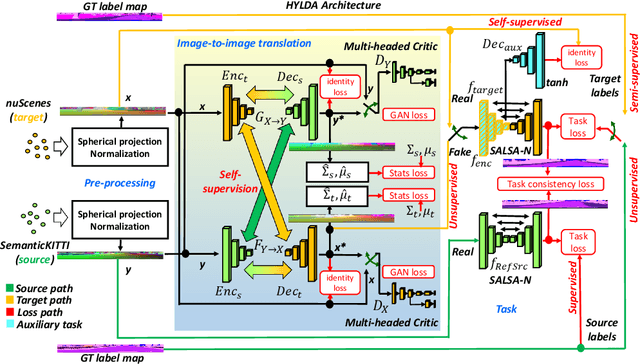
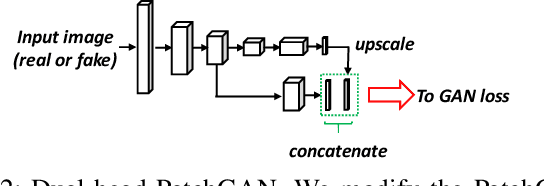

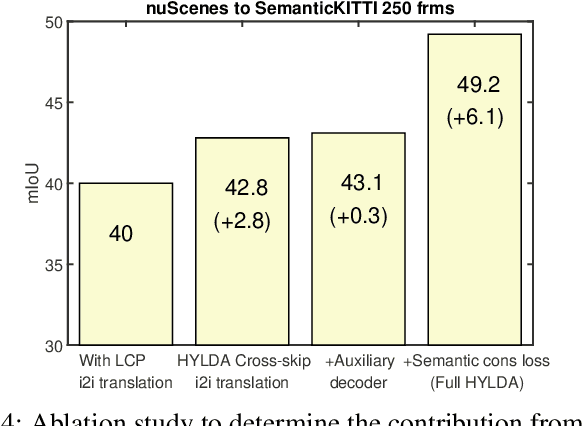
In this paper we address the problem of training a LiDAR semantic segmentation network using a fully-labeled source dataset and a target dataset that only has a small number of labels. To this end, we develop a novel image-to-image translation engine, and couple it with a LiDAR semantic segmentation network, resulting in an integrated domain adaptation architecture we call HYLDA. To train the system end-to-end, we adopt a diverse set of learning paradigms, including 1) self-supervision on a simple auxiliary reconstruction task, 2) semi-supervised training using a few available labeled target domain frames, and 3) unsupervised training on the fake translated images generated by the image-to-image translation stage, together with the labeled frames from the source domain. In the latter case, the semantic segmentation network participates in the updating of the image-to-image translation engine. We demonstrate experimentally that HYLDA effectively addresses the challenging problem of improving generalization on validation data from the target domain when only a few target labeled frames are available for training. We perform an extensive evaluation where we compare HYLDA against strong baseline methods using two publicly available LiDAR semantic segmentation datasets.