 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DArticCyclists: Generating Simulated Dynamic 3D Cyclists for Human-Object Interaction (HOI) and Autonomous Driving Applications
Oct 14, 2024



Human-object interaction (HOI) and human-scene interaction (HSI) are crucial for human-centric scene understanding applications in Embodied Artificial Intelligence (EAI), robotics, and augmented reality (AR). A common limitation faced in these research areas is the data scarcity problem: insufficient labeled human-scene object pairs on the input images, and limited interaction complexity and granularity between them. Recent HOI and HSI methods have addressed this issue by generating dynamic interactions with rigid objects. But more complex dynamic interactions such as a human rider pedaling an articulated bicycle have been unexplored. To address this limitation, and to enable research on complex dynamic human-articulated object interactions, in this paper we propose a method to generate simulated 3D dynamic cyclist assets and interactions. We designed a methodology for creating a new part-based multi-view articulated synthetic 3D bicycle dataset that we call 3DArticBikes that can be used to train NeRF and 3DGS-based 3D reconstruction methods. We then propose a 3DGS-based parametric bicycle composition model to assemble 8-DoF pose-controllable 3D bicycles. Finally, using dynamic information from cyclist videos, we build a complete synthetic dynamic 3D cyclist (rider pedaling a bicycle) by re-posing a selectable synthetic 3D person while automatically placing the rider onto one of our new articulated 3D bicycles using a proposed 3D Keypoint optimization-based Inverse Kinematics pose refinement. We present both, qualitative and quantitative results where we compare our generated cyclists against those from a recent stable diffusion-based method.
GPA-3D: Geometry-aware Prototype Alignment for Unsupervised Domain Adaptive 3D Object Detection from Point Clouds
Aug 16, 2023



LiDAR-based 3D detection has made great progress in recent years. However, the performance of 3D detectors is considerably limited when deployed in unseen environments, owing to the severe domain gap problem. Existing domain adaptive 3D detection methods do not adequately consider the problem of the distributional discrepancy in feature space, thereby hindering generalization of detectors across domains. In this work, we propose a novel unsupervised domain adaptive \textbf{3D} detection framework, namely \textbf{G}eometry-aware \textbf{P}rototype \textbf{A}lignment (\textbf{GPA-3D}), which explicitly leverages the intrinsic geometric relationship from point cloud objects to reduce the feature discrepancy, thus facilitating cross-domain transferring. Specifically, GPA-3D assigns a series of tailored and learnable prototypes to point cloud objects with distinct geometric structures. Each prototype aligns BEV (bird's-eye-view) features derived from corresponding point cloud objects on source and target domains, reducing the distributional discrepancy and achieving better adaptation. The evaluation results obtained on various benchmarks, including Waymo, nuScenes and KITTI, demonstrate the superiority of our GPA-3D over the state-of-the-art approaches for different adaptation scenarios. The MindSpore version code will be publicly available at \url{https://github.com/Liz66666/GPA3D}.
HYLDA: End-to-end Hybrid Learning Domain Adaptation for LiDAR Semantic Segmentation
Jan 14, 2022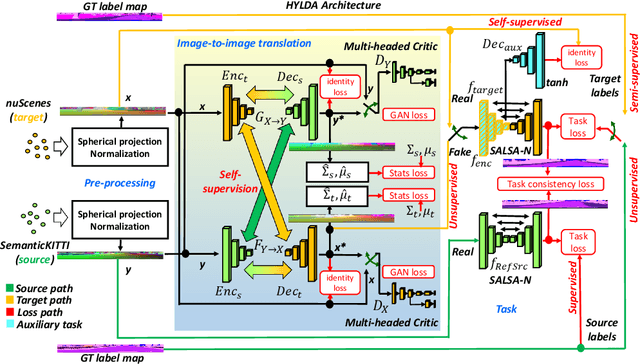
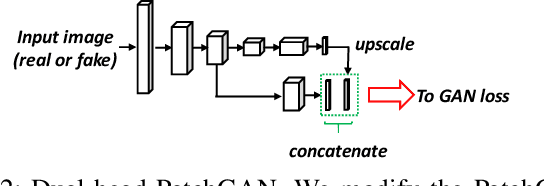

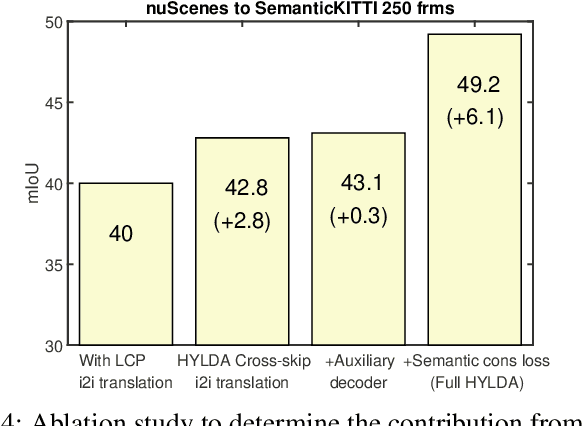
In this paper we address the problem of training a LiDAR semantic segmentation network using a fully-labeled source dataset and a target dataset that only has a small number of labels. To this end, we develop a novel image-to-image translation engine, and couple it with a LiDAR semantic segmentation network, resulting in an integrated domain adaptation architecture we call HYLDA. To train the system end-to-end, we adopt a diverse set of learning paradigms, including 1) self-supervision on a simple auxiliary reconstruction task, 2) semi-supervised training using a few available labeled target domain frames, and 3) unsupervised training on the fake translated images generated by the image-to-image translation stage, together with the labeled frames from the source domain. In the latter case, the semantic segmentation network participates in the updating of the image-to-image translation engine. We demonstrate experimentally that HYLDA effectively addresses the challenging problem of improving generalization on validation data from the target domain when only a few target labeled frames are available for training. We perform an extensive evaluation where we compare HYLDA against strong baseline methods using two publicly available LiDAR semantic segmentation datasets.
SMAC-Seg: LiDAR Panoptic Segmentation via Sparse Multi-directional Attention Clustering
Aug 31, 2021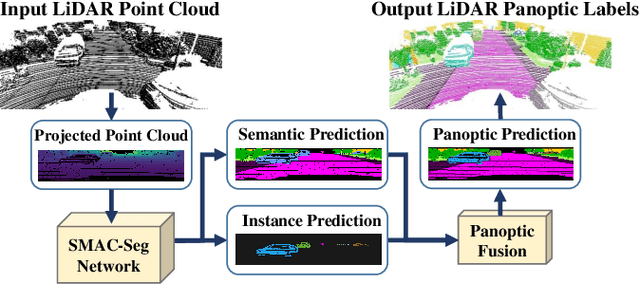
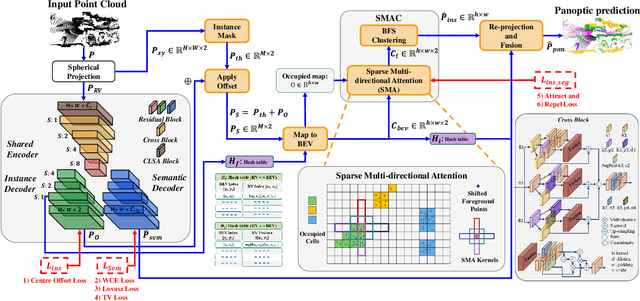
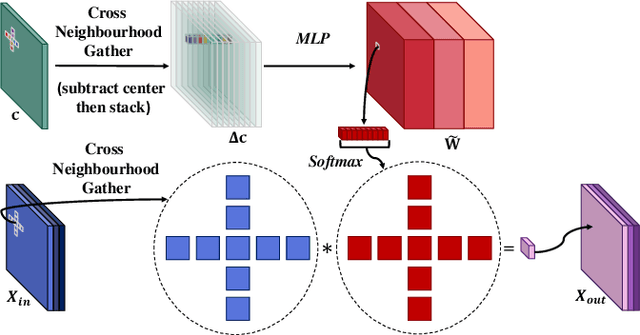
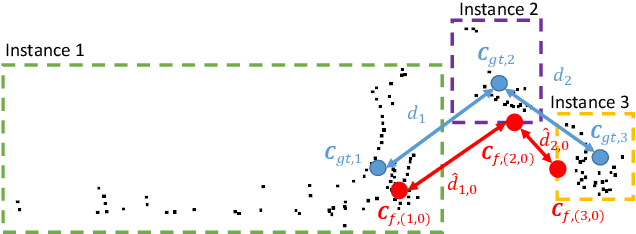
Panoptic segmentation aims to address semantic and instance segmentation simultaneously in a unified framework. However, an efficient solution of panoptic segmentation in applications like autonomous driving is still an open research problem. In this work, we propose a novel LiDAR-based panoptic system, called SMAC-Seg. We present a learnable sparse multi-directional attention clustering to segment multi-scale foreground instances. SMAC-Seg is a real-time clustering-based approach, which removes the complex proposal network to segment instances. Most existing clustering-based methods use the difference of the predicted and ground truth center offset as the only loss to supervise the instance centroid regression. However, this loss function only considers the centroid of the current object, but its relative position with respect to the neighbouring objects is not considered when learning to cluster. Thus, we propose to use a novel centroid-aware repel loss as an additional term to effectively supervise the network to differentiate each object cluster with its neighbours. Our experimental results show that SMAC-Seg achieves state-of-the-art performance among all real-time deployable networks on both large-scale public SemanticKITTI and nuScenes panoptic segmentation datasets.
GP-S3Net: Graph-based Panoptic Sparse Semantic Segmentation Network
Aug 18, 2021



Panoptic segmentation as an integrated task of both static environmental understanding and dynamic object identification, has recently begun to receive broad research interest. In this paper, we propose a new computationally efficient LiDAR based panoptic segmentation framework, called GP-S3Net. GP-S3Net is a proposal-free approach in which no object proposals are needed to identify the objects in contrast to conventional two-stage panoptic systems, where a detection network is incorporated for capturing instance information. Our new design consists of a novel instance-level network to process the semantic results by constructing a graph convolutional network to identify objects (foreground), which later on are fused with the background classes. Through the fine-grained clusters of the foreground objects from the semantic segmentation backbone, over-segmentation priors are generated and subsequently processed by 3D sparse convolution to embed each cluster. Each cluster is treated as a node in the graph and its corresponding embedding is used as its node feature. Then a GCNN predicts whether edges exist between each cluster pair. We utilize the instance label to generate ground truth edge labels for each constructed graph in order to supervise the learning. Extensive experiments demonstrate that GP-S3Net outperforms the current state-of-the-art approaches, by a significant margin across available datasets such as, nuScenes and SemanticPOSS, ranking first on the competitive public SemanticKITTI leaderboard upon publication.
Lite-HDSeg: LiDAR Semantic Segmentation Using Lite Harmonic Dense Convolutions
Mar 16, 2021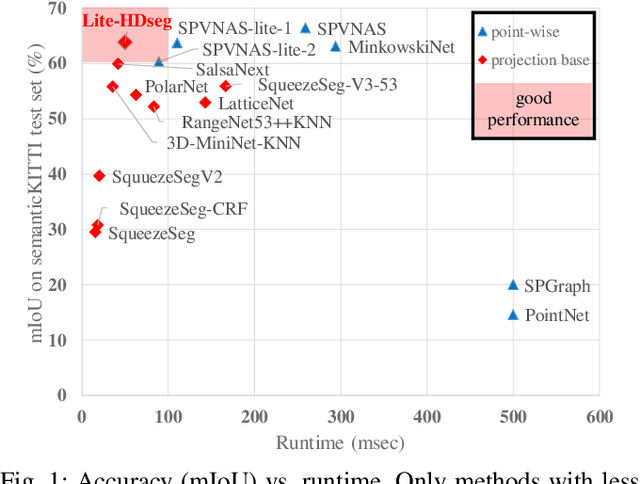
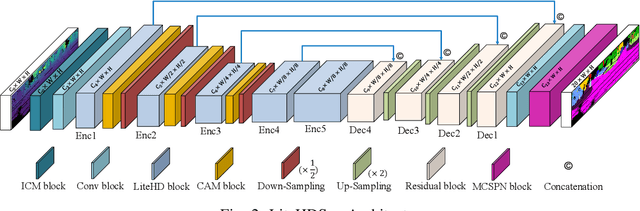
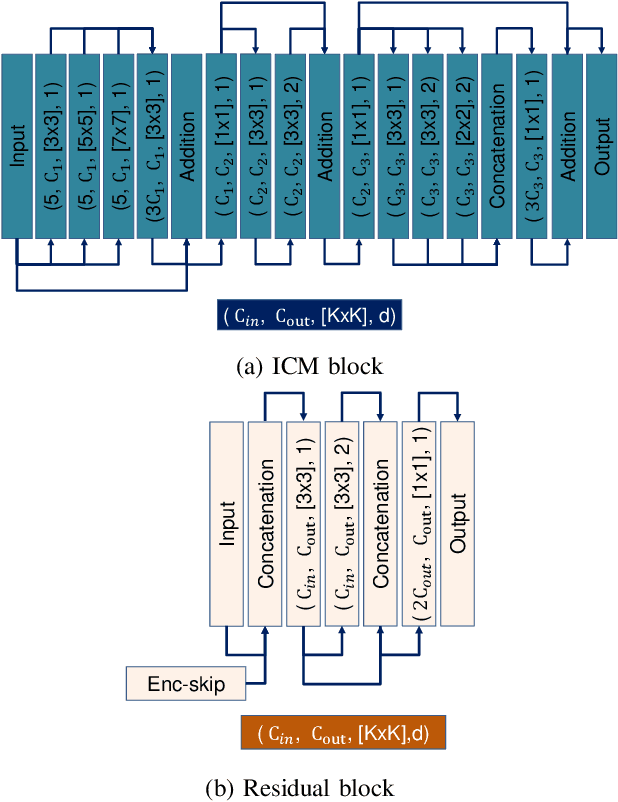
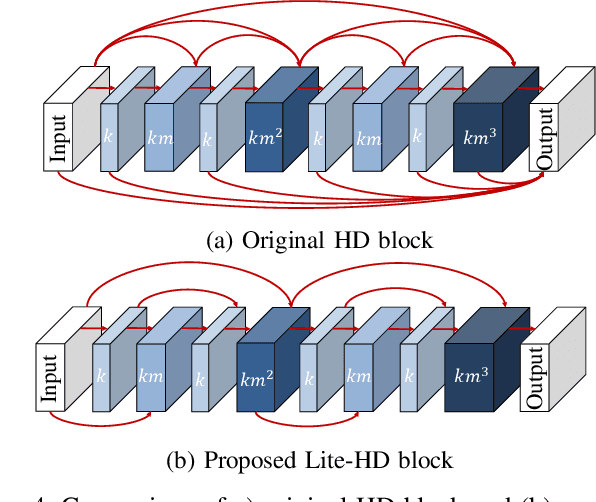
Autonomous driving vehicles and robotic systems rely on accurate perception of their surroundings. Scene understanding is one of the crucial components of perception modules. Among all available sensors, LiDARs are one of the essential sensing modalities of autonomous driving systems due to their active sensing nature with high resolution of sensor readings. Accurate and fast semantic segmentation methods are needed to fully utilize LiDAR sensors for scene understanding. In this paper, we present Lite-HDSeg, a novel real-time convolutional neural network for semantic segmentation of full $3$D LiDAR point clouds. Lite-HDSeg can achieve the best accuracy vs. computational complexity trade-off in SemanticKitti benchmark and is designed on the basis of a new encoder-decoder architecture with light-weight harmonic dense convolutions as its core. Moreover, we introduce ICM, an improved global contextual module to capture multi-scale contextual features, and MCSPN, a multi-class Spatial Propagation Network to further refine the semantic boundaries. Our experimental results show that the proposed method outperforms state-of-the-art semantic segmentation approaches which can run real-time, thus is suitable for robotic and autonomous driving applications.
S3Net: 3D LiDAR Sparse Semantic Segmentation Network
Mar 15, 2021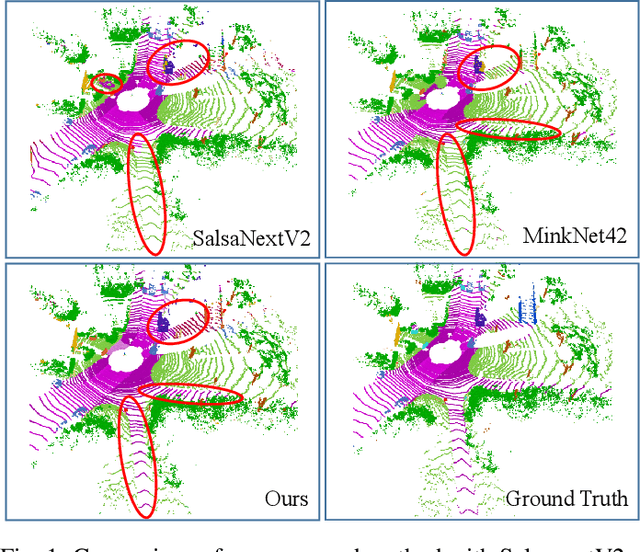

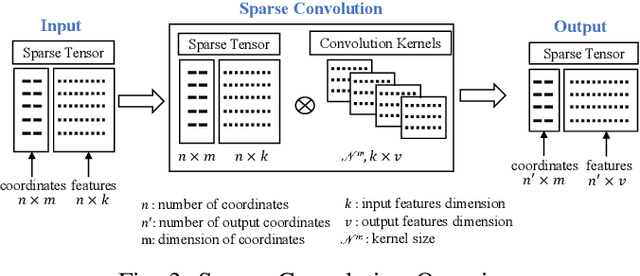
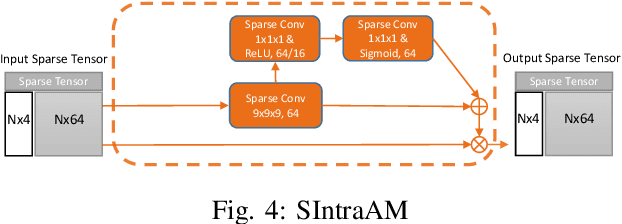
Semantic Segmentation is a crucial component in the perception systems of many applications, such as robotics and autonomous driving that rely on accurate environmental perception and understanding. In literature, several approaches are introduced to attempt LiDAR semantic segmentation task, such as projection-based (range-view or birds-eye-view), and voxel-based approaches. However, they either abandon the valuable 3D topology and geometric relations and suffer from information loss introduced in the projection process or are inefficient. Therefore, there is a need for accurate models capable of processing the 3D driving-scene point cloud in 3D space. In this paper, we propose S3Net, a novel convolutional neural network for LiDAR point cloud semantic segmentation. It adopts an encoder-decoder backbone that consists of Sparse Intra-channel Attention Module (SIntraAM), and Sparse Inter-channel Attention Module (SInterAM) to emphasize the fine details of both within each feature map and among nearby feature maps. To extract the global contexts in deeper layers, we introduce Sparse Residual Tower based upon sparse convolution that suits varying sparsity of LiDAR point cloud. In addition, geo-aware anisotrophic loss is leveraged to emphasize the semantic boundaries and penalize the noise within each predicted regions, leading to a robust prediction. Our experimental results show that the proposed method leads to a large improvement (12\%) compared to its baseline counterpart (MinkNet42 \cite{choy20194d}) on SemanticKITTI \cite{DBLP:conf/iccv/BehleyGMQBSG19} test set and achieves state-of-the-art mIoU accuracy of semantic segmentation approaches.
S3CNet: A Sparse Semantic Scene Completion Network for LiDAR Point Clouds
Dec 16, 2020

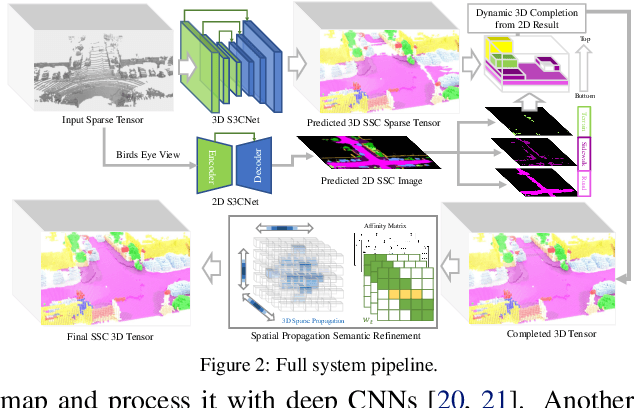
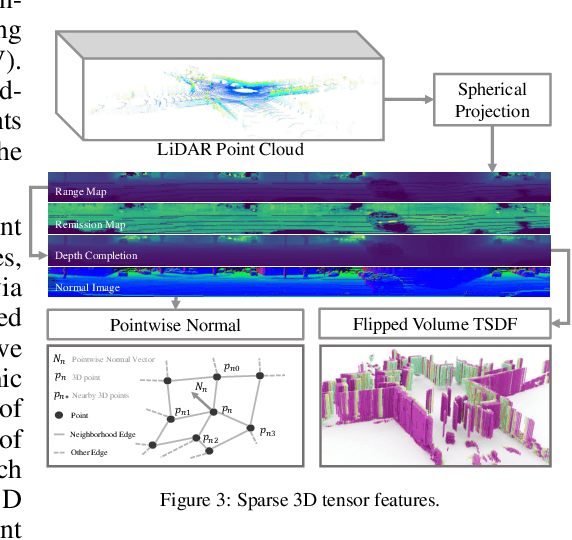
With the increasing reliance of self-driving and similar robotic systems on robust 3D vision, the processing of LiDAR scans with deep convolutional neural networks has become a trend in academia and industry alike. Prior attempts on the challenging Semantic Scene Completion task - which entails the inference of dense 3D structure and associated semantic labels from "sparse" representations - have been, to a degree, successful in small indoor scenes when provided with dense point clouds or dense depth maps often fused with semantic segmentation maps from RGB images. However, the performance of these systems drop drastically when applied to large outdoor scenes characterized by dynamic and exponentially sparser conditions. Likewise, processing of the entire sparse volume becomes infeasible due to memory limitations and workarounds introduce computational inefficiency as practitioners are forced to divide the overall volume into multiple equal segments and infer on each individually, rendering real-time performance impossible. In this work, we formulate a method that subsumes the sparsity of large-scale environments and present S3CNet, a sparse convolution based neural network that predicts the semantically completed scene from a single, unified LiDAR point cloud. We show that our proposed method outperforms all counterparts on the 3D task, achieving state-of-the art results on the SemanticKITTI benchmark. Furthermore, we propose a 2D variant of S3CNet with a multi-view fusion strategy to complement our 3D network, providing robustness to occlusions and extreme sparsity in distant regions. We conduct experiments for the 2D semantic scene completion task and compare the results of our sparse 2D network against several leading LiDAR segmentation models adapted for bird's eye view segmentation on two open-source datasets.