 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceVLN: A Zero-Shot Vision-and-Language Navigation Agent with Online Spatial Cognitive Memory and Reasoning
Jun 08, 2026Vision-and-Language Navigation in continuous environments requires agents to understand the spatial structure of previously unseen environments in order to follow language instructions. Although foundation models have opened a promising path toward zero-shot navigation without task-specific policy training, many navigators still rely on local visual cues and linear history-based reasoning, overlooking the spatial nature of navigation across explored regions, traversed paths, landmarks, and their spatial relations. In this paper, we propose SpaceVLN, a navigation agent built around Spatial Cognitive Memory and Task-Guided Spatial Reasoning. Specifically, SpaceVLN introduces an efficient stagewise closed-loop framework where planning and execution are organized around verifiable space--landmark stages. During navigation, the agent progressively abstracts explored regions into Spatial Waypoints and dynamically maintains subtask-grounded landmark evidence, forming a hierarchical Spatial Cognitive Memory for progress localization and spatial-relation understanding. Built on this memory, Spatial-CoT integrates task-progress reasoning with spatial perception, analysis, and prediction, enabling Task-Guided Spatial Reasoning for embodied navigation. The unified stage interface enables SpaceVLN to address both Vision-and-Language Navigation and Object-Goal Navigation under a unified zero-shot setting, without task-specific policy training. Across R2R-CE, RxR-CE, GN-Bench, and HM3D-OVON, SpaceVLN achieves state-of-the-art zero-shot performance, and real-robot deployment further validates its applicability. These results highlight Spatial Cognitive Memory and Task-Guided Spatial Reasoning as a practical foundation for stronger embodied navigation agents.
GN0: Toward a Unified Paradigm for Generation, Evaluation, and Policy Learning in Visual-Language Navigation
Jun 02, 2026Embodied navigation connects intelligent agents with the physical world and is fundamental for general robotic intelligence. Limited availability and quality of navigation data have constrained Vision-and-Language Navigation (VLN) systems' generalization and long-horizon capabilities. To address this, we curate diverse 3D scenes and develop an automated pipeline for large-scale navigation data, resulting in the GN-Matrix dataset. Building on a 3D Gaussian Splatting (3DGS) engine, we introduce a high-fidelity simulation platform supporting interactive roaming and collision-aware navigation. We further propose GN-Bench, the first BEV-based benchmark incorporating dynamic 3DGS avatars for human-robot interaction evaluation. To leverage the simulator, we develop an RL-driven navigation foundation model, Break and Establish (BAE). After supervised learning, DAgger exposes the model to rollout-induced states, breaking narrow expert-centric distributions and enabling downstream RL exploration. This unified VLN paradigm integrates map-based and map-free tasks, including instruction following, human following, and goal navigation. GN-BAE formalizes high-fidelity 3DGS-rendered Bird's Eye View representations as compact memory, unlocking latent spatial reasoning in VLMs. Extensive evaluations on GN-Bench and VLN-CE show that GN0 outperforms state-of-the-art VLN methods. Overall, GN-Matrix offers a unified framework spanning data, simulation, and learning, advancing embodied navigation in research and industrial applications.
DeCoNav: Dialog enhanced Long-Horizon Collaborative Vision-Language Navigation
Apr 14, 2026Long-horizon collaborative vision-language navigation (VLN) is critical for multi-robot systems to accomplish complex tasks beyond the capability of a single agent. CoNavBench takes a first step by introducing the first collaborative long-horizon VLN benchmark with relay-style multi-robot tasks, a collaboration taxonomy, along with graph-grounded generation and evaluation to model handoffs and rendezvous in shared environments. However, existing benchmarks and evaluations often do not enforce strictly synchronized dual-robot rollout on a shared world timeline, and they typically rely on static coordination policies that cannot adapt when new cross-agent evidence emerges. We present Dialog enhanced Long-Horizon Collaborative Vision-Language Navigation (DeCoNav), a decentralized framework that couples event-triggered dialogue with dynamic task allocation and replanning for real-time, adaptive coordination. In DeCoNav, robots exchange compact semantic states via dialogue without a central controller. When informative events such as new evidence, uncertainty, or conflicts arise, dialogue is triggered to dynamically reassign subgoals and replan under synchronized execution. Implemented in DeCoNavBench with 1,213 tasks across 176 HM3D scenes, DeCoNav improves the both-success rate (BSR) by 69.2%, demonstrating the effectiveness of dialogue-driven, dynamically reallocated planning for multi-robot collaboration.
RoboGSim: A Real2Sim2Real Robotic Gaussian Splatting Simulator
Nov 18, 2024
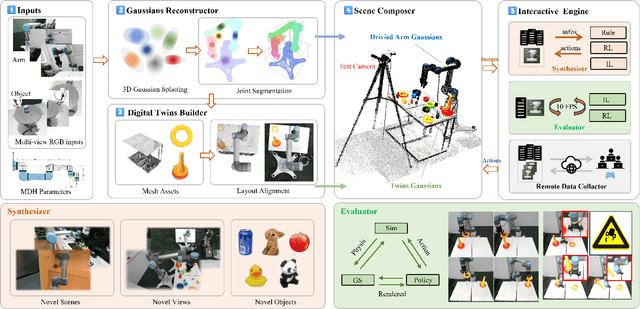


Efficient acquisition of real-world embodied data has been increasingly critical. However, large-scale demonstrations captured by remote operation tend to take extremely high costs and fail to scale up the data size in an efficient manner. Sampling the episodes under a simulated environment is a promising way for large-scale collection while existing simulators fail to high-fidelity modeling on texture and physics. To address these limitations, we introduce the RoboGSim, a real2sim2real robotic simulator, powered by 3D Gaussian Splatting and the physics engine. RoboGSim mainly includes four parts: Gaussian Reconstructor, Digital Twins Builder, Scene Composer, and Interactive Engine. It can synthesize the simulated data with novel views, objects, trajectories, and scenes. RoboGSim also provides an online, reproducible, and safe evaluation for different manipulation policies. The real2sim and sim2real transfer experiments show a high consistency in the texture and physics. Moreover, the effectiveness of synthetic data is validated under the real-world manipulated tasks. We hope RoboGSim serves as a closed-loop simulator for fair comparison on policy learning. More information can be found on our project page https://robogsim.github.io/ .
GaussianDiffusion: 3D Gaussian Splatting for Denoising Diffusion Probabilistic Models with Structured Noise
Nov 19, 2023Text-to-3D, known for its efficient generation methods and expansive creative potential, has garnered significant attention in the AIGC domain. However, the amalgamation of Nerf and 2D diffusion models frequently yields oversaturated images, posing severe limitations on downstream industrial applications due to the constraints of pixelwise rendering method. Gaussian splatting has recently superseded the traditional pointwise sampling technique prevalent in NeRF-based methodologies, revolutionizing various aspects of 3D reconstruction. This paper introduces a novel text to 3D content generation framework based on Gaussian splatting, enabling fine control over image saturation through individual Gaussian sphere transparencies, thereby producing more realistic images. The challenge of achieving multi-view consistency in 3D generation significantly impedes modeling complexity and accuracy. Taking inspiration from SJC, we explore employing multi-view noise distributions to perturb images generated by 3D Gaussian splatting, aiming to rectify inconsistencies in multi-view geometry. We ingeniously devise an efficient method to generate noise that produces Gaussian noise from diverse viewpoints, all originating from a shared noise source. Furthermore, vanilla 3D Gaussian-based generation tends to trap models in local minima, causing artifacts like floaters, burrs, or proliferative elements. To mitigate these issues, we propose the variational Gaussian splatting technique to enhance the quality and stability of 3D appearance. To our knowledge, our approach represents the first comprehensive utilization of Gaussian splatting across the entire spectrum of 3D content generation processes.
S3CNet: A Sparse Semantic Scene Completion Network for LiDAR Point Clouds
Dec 16, 2020

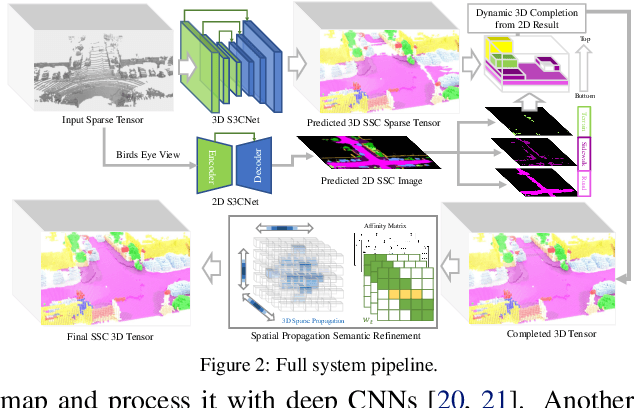
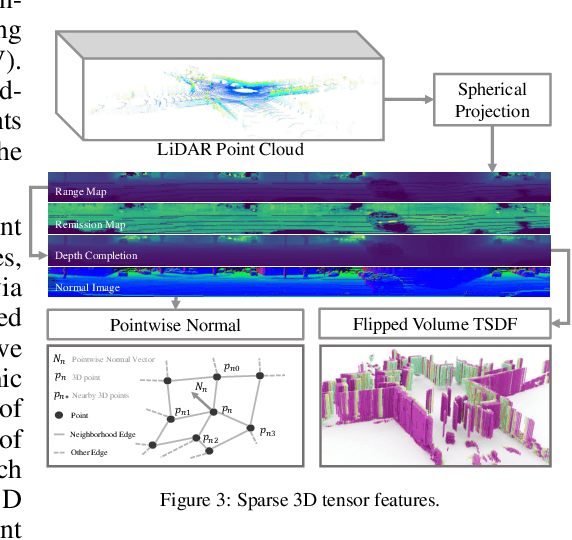
With the increasing reliance of self-driving and similar robotic systems on robust 3D vision, the processing of LiDAR scans with deep convolutional neural networks has become a trend in academia and industry alike. Prior attempts on the challenging Semantic Scene Completion task - which entails the inference of dense 3D structure and associated semantic labels from "sparse" representations - have been, to a degree, successful in small indoor scenes when provided with dense point clouds or dense depth maps often fused with semantic segmentation maps from RGB images. However, the performance of these systems drop drastically when applied to large outdoor scenes characterized by dynamic and exponentially sparser conditions. Likewise, processing of the entire sparse volume becomes infeasible due to memory limitations and workarounds introduce computational inefficiency as practitioners are forced to divide the overall volume into multiple equal segments and infer on each individually, rendering real-time performance impossible. In this work, we formulate a method that subsumes the sparsity of large-scale environments and present S3CNet, a sparse convolution based neural network that predicts the semantically completed scene from a single, unified LiDAR point cloud. We show that our proposed method outperforms all counterparts on the 3D task, achieving state-of-the art results on the SemanticKITTI benchmark. Furthermore, we propose a 2D variant of S3CNet with a multi-view fusion strategy to complement our 3D network, providing robustness to occlusions and extreme sparsity in distant regions. We conduct experiments for the 2D semantic scene completion task and compare the results of our sparse 2D network against several leading LiDAR segmentation models adapted for bird's eye view segmentation on two open-source datasets.