 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG-VQ: Language-Guided Codebook Learning
May 23, 2024



Vector quantization (VQ) is a key technique in high-resolution and high-fidelity image synthesis, which aims to learn a codebook to encode an image with a sequence of discrete codes and then generate an image in an auto-regression manner. Although existing methods have shown superior performance, most methods prefer to learn a single-modal codebook (\emph{e.g.}, image), resulting in suboptimal performance when the codebook is applied to multi-modal downstream tasks (\emph{e.g.}, text-to-image, image captioning) due to the existence of modal gaps. In this paper, we propose a novel language-guided codebook learning framework, called LG-VQ, which aims to learn a codebook that can be aligned with the text to improve the performance of multi-modal downstream tasks. Specifically, we first introduce pre-trained text semantics as prior knowledge, then design two novel alignment modules (\emph{i.e.}, Semantic Alignment Module, and Relationship Alignment Module) to transfer such prior knowledge into codes for achieving codebook text alignment. In particular, our LG-VQ method is model-agnostic, which can be easily integrated into existing VQ models. Experimental results show that our method achieves superior performance on reconstruction and various multi-modal downstream tasks.
Codebook Transfer with Part-of-Speech for Vector-Quantized Image Modeling
Mar 15, 2024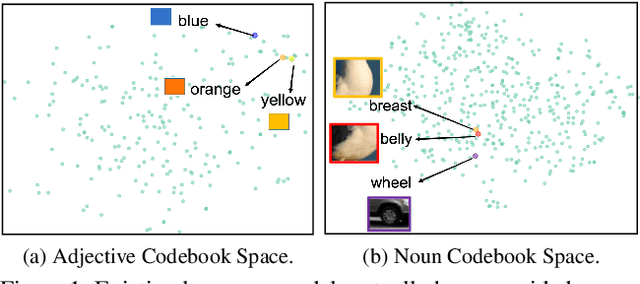

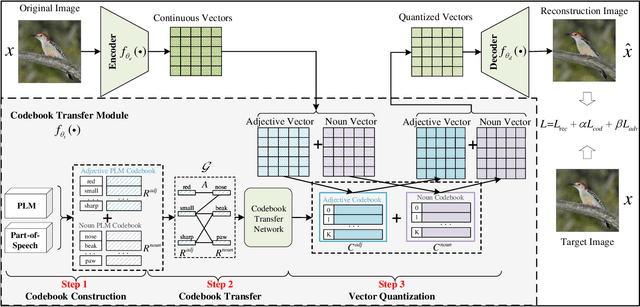
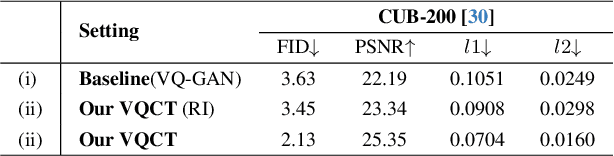
Vector-Quantized Image Modeling (VQIM) is a fundamental research problem in image synthesis, which aims to represent an image with a discrete token sequence. Existing studies effectively address this problem by learning a discrete codebook from scratch and in a code-independent manner to quantize continuous representations into discrete tokens. However, learning a codebook from scratch and in a code-independent manner is highly challenging, which may be a key reason causing codebook collapse, i.e., some code vectors can rarely be optimized without regard to the relationship between codes and good codebook priors such that die off finally. In this paper, inspired by pretrained language models, we find that these language models have actually pretrained a superior codebook via a large number of text corpus, but such information is rarely exploited in VQIM. To this end, we propose a novel codebook transfer framework with part-of-speech, called VQCT, which aims to transfer a well-trained codebook from pretrained language models to VQIM for robust codebook learning. Specifically, we first introduce a pretrained codebook from language models and part-of-speech knowledge as priors. Then, we construct a vision-related codebook with these priors for achieving codebook transfer. Finally, a novel codebook transfer network is designed to exploit abundant semantic relationships between codes contained in pretrained codebooks for robust VQIM codebook learning. Experimental results on four datasets show that our VQCT method achieves superior VQIM performance over previous state-of-the-art methods.
GaussianDiffusion: 3D Gaussian Splatting for Denoising Diffusion Probabilistic Models with Structured Noise
Nov 19, 2023Text-to-3D, known for its efficient generation methods and expansive creative potential, has garnered significant attention in the AIGC domain. However, the amalgamation of Nerf and 2D diffusion models frequently yields oversaturated images, posing severe limitations on downstream industrial applications due to the constraints of pixelwise rendering method. Gaussian splatting has recently superseded the traditional pointwise sampling technique prevalent in NeRF-based methodologies, revolutionizing various aspects of 3D reconstruction. This paper introduces a novel text to 3D content generation framework based on Gaussian splatting, enabling fine control over image saturation through individual Gaussian sphere transparencies, thereby producing more realistic images. The challenge of achieving multi-view consistency in 3D generation significantly impedes modeling complexity and accuracy. Taking inspiration from SJC, we explore employing multi-view noise distributions to perturb images generated by 3D Gaussian splatting, aiming to rectify inconsistencies in multi-view geometry. We ingeniously devise an efficient method to generate noise that produces Gaussian noise from diverse viewpoints, all originating from a shared noise source. Furthermore, vanilla 3D Gaussian-based generation tends to trap models in local minima, causing artifacts like floaters, burrs, or proliferative elements. To mitigate these issues, we propose the variational Gaussian splatting technique to enhance the quality and stability of 3D appearance. To our knowledge, our approach represents the first comprehensive utilization of Gaussian splatting across the entire spectrum of 3D content generation processes.