 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-MoE: Mixture of Experts for Remote Sensing Image Captioning and Visual Question Answering
Nov 03, 2024Remote Sensing Image Captioning (RSIC) presents unique challenges and plays a critical role in applications. Traditional RSIC methods often struggle to produce rich and diverse descriptions. Recently, with advancements in VLMs, efforts have emerged to integrate these models into the remote sensing domain and to introduce descriptive datasets specifically designed to enhance VLM training. This paper proposes RS-MoE, a first Mixture of Expert based VLM specifically customized for remote sensing domain. Unlike traditional MoE models, the core of RS-MoE is the MoE Block, which incorporates a novel Instruction Router and multiple lightweight Large Language Models (LLMs) as expert models. The Instruction Router is designed to generate specific prompts tailored for each corresponding LLM, guiding them to focus on distinct aspects of the RSIC task. This design not only allows each expert LLM to concentrate on a specific subset of the task, thereby enhancing the specificity and accuracy of the generated captions, but also improves the scalability of the model by facilitating parallel processing of sub-tasks. Additionally, we present a two-stage training strategy for tuning our RS-MoE model to prevent performance degradation due to sparsity. We fine-tuned our model on the RSICap dataset using our proposed training strategy. Experimental results on the RSICap dataset, along with evaluations on other traditional datasets where no additional fine-tuning was applied, demonstrate that our model achieves state-of-the-art performance in generating precise and contextually relevant captions. Notably, our RS-MoE-1B variant achieves performance comparable to 13B VLMs, demonstrating the efficiency of our model design. Moreover, our model demonstrates promising generalization capabilities by consistently achieving state-of-the-art performance on the Remote Sensing Visual Question Answering (RSVQA) task.
LG-VQ: Language-Guided Codebook Learning
May 23, 2024Vector quantization (VQ) is a key technique in high-resolution and high-fidelity image synthesis, which aims to learn a codebook to encode an image with a sequence of discrete codes and then generate an image in an auto-regression manner. Although existing methods have shown superior performance, most methods prefer to learn a single-modal codebook (\emph{e.g.}, image), resulting in suboptimal performance when the codebook is applied to multi-modal downstream tasks (\emph{e.g.}, text-to-image, image captioning) due to the existence of modal gaps. In this paper, we propose a novel language-guided codebook learning framework, called LG-VQ, which aims to learn a codebook that can be aligned with the text to improve the performance of multi-modal downstream tasks. Specifically, we first introduce pre-trained text semantics as prior knowledge, then design two novel alignment modules (\emph{i.e.}, Semantic Alignment Module, and Relationship Alignment Module) to transfer such prior knowledge into codes for achieving codebook text alignment. In particular, our LG-VQ method is model-agnostic, which can be easily integrated into existing VQ models. Experimental results show that our method achieves superior performance on reconstruction and various multi-modal downstream tasks.
MCSDNet: Mesoscale Convective System Detection Network via Multi-scale Spatiotemporal Information
Apr 26, 2024



The accurate detection of Mesoscale Convective Systems (MCS) is crucial for meteorological monitoring due to their potential to cause significant destruction through severe weather phenomena such as hail, thunderstorms, and heavy rainfall. However, the existing methods for MCS detection mostly targets on single-frame detection, which just considers the static characteristics and ignores the temporal evolution in the life cycle of MCS. In this paper, we propose a novel encoder-decoder neural network for MCS detection(MCSDNet). MCSDNet has a simple architecture and is easy to expand. Different from the previous models, MCSDNet targets on multi-frames detection and leverages multi-scale spatiotemporal information for the detection of MCS regions in remote sensing imagery(RSI). As far as we know, it is the first work to utilize multi-scale spatiotemporal information to detect MCS regions. Firstly, we design a multi-scale spatiotemporal information module to extract multi-level semantic from different encoder levels, which makes our models can extract more detail spatiotemporal features. Secondly, a Spatiotemporal Mix Unit(STMU) is introduced to MCSDNet to capture both intra-frame features and inter-frame correlations, which is a scalable module and can be replaced by other spatiotemporal module, e.g., CNN, RNN, Transformer and our proposed Dual Spatiotemporal Attention(DSTA). This means that the future works about spatiotemporal modules can be easily integrated to our model. Finally, we present MCSRSI, the first publicly available dataset for multi-frames MCS detection based on visible channel images from the FY-4A satellite. We also conduct several experiments on MCSRSI and find that our proposed MCSDNet achieve the best performance on MCS detection task when comparing to other baseline methods.
DiffCast: A Unified Framework via Residual Diffusion for Precipitation Nowcasting
Dec 11, 2023



Precipitation nowcasting is an important spatio-temporal prediction task to predict the radar echoes sequences based on current observations, which can serve both meteorological science and smart city applications. Due to the chaotic evolution nature of the precipitation systems, it is a very challenging problem. Previous studies address the problem either from the perspectives of deterministic modeling or probabilistic modeling. However, their predictions suffer from the blurry, high-value echoes fading away and position inaccurate issues. The root reason of these issues is that the chaotic evolutionary precipitation systems are not appropriately modeled. Inspired by the nature of the systems, we propose to decompose and model them from the perspective of global deterministic motion and local stochastic variations with residual mechanism. A unified and flexible framework that can equip any type of spatio-temporal models is proposed based on residual diffusion, which effectively tackles the shortcomings of previous methods. Extensive experimental results on four publicly available radar datasets demonstrate the effectiveness and superiority of the proposed framework, compared to state-of-the-art techniques. Our code will be made publicly available soon.
RAP-Net: Region Attention Predictive Network for Precipitation Nowcasting
Oct 03, 2021

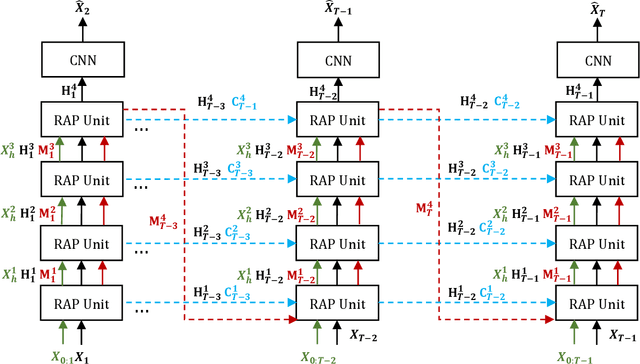

Natural disasters caused by heavy rainfall often cost huge loss of life and property. To avoid it, the task of precipitation nowcasting is imminent. To solve the problem, increasingly deep learning methods are proposed to forecast future radar echo images and then the predicted maps have converted the distribution of rainfall. The prevailing spatiotemporal sequence prediction methods apply ConvRNN structure which combines the Convolution and Recurrent neural network. Although improvements based on ConvRNN achieve remarkable success, these methods ignore capturing both local and global spatial features simultaneously, which degrades the nowcasting in the region of heavy rainfall. To address this issue, we proposed the Region Attention Block (RAB) and embed it into ConvRNN to enhance the forecast in the area with strong rainfall. Besides, the ConvRNN models are hard to memory longer history representations with limited parameters. Considering it, we propose Recall Attention Mechanism (RAM) to improve the prediction. By preserving longer temporal information, RAM contributes to the forecasting, especially in the middle rainfall intensity. The experiments show that the proposed model Region Attention Predictive Network (RAP-Net) has outperformed the state-of-art method.