 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-Aware Key-Value Compression for Efficient Autoregressive Image Generation
May 20, 2026Autoregressive (AR) visual generation has achieved remarkable performance but suffers from high memory usage and low throughput, as it requires caching previously generated visual tokens. Recent research has shown that retaining only a few lines of cache tokens can maintain high-quality images while significantly reducing memory usage and improving throughput. However, these methods allocate a fixed budget to each attention head, overlooking the heterogeneity among attention heads, leading to suboptimal memory allocation. In this paper, we observe that attention heads across different layers exhibit diverse attention patterns, where some heads focus on local neighborhoods while others capture broader contextual dependencies. Based on this insight, we propose a novel head-aware key-value (KV) cache compression framework for autoregressive image generation, called HeadKV, which assigns smaller budgets to locality-biased heads and larger budgets to heads with broader attention. A key challenge lies in identifying the type of each attention head to guide cache compression. We further observe that, within the same layer, each head exhibits consistent attention patterns across token positions, \emph{i.e.}, a head's behavior for early tokens remains consistent with that for later tokens. This insight suggests that head types can be identified during the early stage and reused for KV compression throughout generation. Its advantage is that it requires no additional training or dataset-level statistics and generalizes seamlessly across different inputs. Moreover, we design a Stratified Token Eviction strategy to effectively preserve long-range information. Extensive experiments demonstrate its effectiveness across multiple autoregressive image generation models.
SJD-VP: Speculative Jacobi Decoding with Verification Prediction for Autoregressive Image Generation
Mar 28, 2026Speculative Jacobi Decoding (SJD) has emerged as a promising method for accelerating autoregressive image generation. Despite its potential, existing SJD approaches often suffer from the low acceptance rate issue of speculative tokens due to token selection ambiguity. Recent works attempt to mitigate this issue primarily from the relaxed token verification perspective but fail to fully exploit the iterative dynamics of decoding. In this paper, we conduct an in-depth analysis and make a novel observation that tokens whose probabilities increase are more likely to match the verification-accepted and correct token. Based on this, we propose a novel Speculative Jacobi Decoding with Verification Prediction (SJD-VP). The key idea is to leverage the change in token probabilities across iterations to guide sampling, favoring tokens whose probabilities increase. This effectively predicts which tokens are likely to pass subsequent verification, boosting the acceptance rate. In particular, our SJD-VP is plug-and-play and can be seamlessly integrated into existing SJD methods. Extensive experiments on standard benchmarks demonstrate that our SJD-VP method consistently accelerates autoregressive decoding while improving image generation quality.
Improved Masked Image Generation with Knowledge-Augmented Token Representations
Nov 15, 2025Masked image generation (MIG) has demonstrated remarkable efficiency and high-fidelity images by enabling parallel token prediction. Existing methods typically rely solely on the model itself to learn semantic dependencies among visual token sequences. However, directly learning such semantic dependencies from data is challenging because the individual tokens lack clear semantic meanings, and these sequences are usually long. To address this limitation, we propose a novel Knowledge-Augmented Masked Image Generation framework, named KA-MIG, which introduces explicit knowledge of token-level semantic dependencies (\emph{i.e.}, extracted from the training data) as priors to learn richer representations for improving performance. In particular, we explore and identify three types of advantageous token knowledge graphs, including two positive and one negative graphs (\emph{i.e.}, the co-occurrence graph, the semantic similarity graph, and the position-token incompatibility graph). Based on three prior knowledge graphs, we design a graph-aware encoder to learn token and position-aware representations. After that, a lightweight fusion mechanism is introduced to integrate these enriched representations into the existing MIG methods. Resorting to such prior knowledge, our method effectively enhances the model's ability to capture semantic dependencies, leading to improved generation quality. Experimental results demonstrate that our method improves upon existing MIG for class-conditional image generation on ImageNet.
Towards Improved Text-Aligned Codebook Learning: Multi-Hierarchical Codebook-Text Alignment with Long Text
Mar 03, 2025Image quantization is a crucial technique in image generation, aimed at learning a codebook that encodes an image into a discrete token sequence. Recent advancements have seen researchers exploring learning multi-modal codebook (i.e., text-aligned codebook) by utilizing image caption semantics, aiming to enhance codebook performance in cross-modal tasks. However, existing image-text paired datasets exhibit a notable flaw in that the text descriptions tend to be overly concise, failing to adequately describe the images and provide sufficient semantic knowledge, resulting in limited alignment of text and codebook at a fine-grained level. In this paper, we propose a novel Text-Augmented Codebook Learning framework, named TA-VQ, which generates longer text for each image using the visual-language model for improved text-aligned codebook learning. However, the long text presents two key challenges: how to encode text and how to align codebook and text. To tackle two challenges, we propose to split the long text into multiple granularities for encoding, i.e., word, phrase, and sentence, so that the long text can be fully encoded without losing any key semantic knowledge. Following this, a hierarchical encoder and novel sampling-based alignment strategy are designed to achieve fine-grained codebook-text alignment. Additionally, our method can be seamlessly integrated into existing VQ models. Extensive experiments in reconstruction and various downstream tasks demonstrate its effectiveness compared to previous state-of-the-art approaches.
AsyncDSB: Schedule-Asynchronous Diffusion Schrödinger Bridge for Image Inpainting
Dec 11, 2024

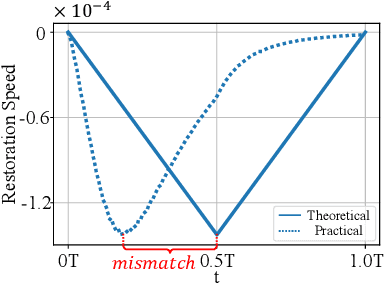
Image inpainting is an important image generation task, which aims to restore corrupted image from partial visible area. Recently, diffusion Schr\"odinger bridge methods effectively tackle this task by modeling the translation between corrupted and target images as a diffusion Schr\"odinger bridge process along a noising schedule path. Although these methods have shown superior performance, in this paper, we find that 1) existing methods suffer from a schedule-restoration mismatching issue, i.e., the theoretical schedule and practical restoration processes usually exist a large discrepancy, which theoretically results in the schedule not fully leveraged for restoring images; and 2) the key reason causing such issue is that the restoration process of all pixels are actually asynchronous but existing methods set a synchronous noise schedule to them, i.e., all pixels shares the same noise schedule. To this end, we propose a schedule-Asynchronous Diffusion Schr\"odinger Bridge (AsyncDSB) for image inpainting. Our insight is preferentially scheduling pixels with high frequency (i.e., large gradients) and then low frequency (i.e., small gradients). Based on this insight, given a corrupted image, we first train a network to predict its gradient map in corrupted area. Then, we regard the predicted image gradient as prior and design a simple yet effective pixel-asynchronous noise schedule strategy to enhance the diffusion Schr\"odinger bridge. Thanks to the asynchronous schedule at pixels, the temporal interdependence of restoration process between pixels can be fully characterized for high-quality image inpainting. Experiments on real-world datasets show that our AsyncDSB achieves superior performance, especially on FID with around 3% - 14% improvement over state-of-the-art baseline methods.
Prototype Optimization with Neural ODE for Few-Shot Learning
Nov 19, 2024Few-Shot Learning (FSL) is a challenging task, which aims to recognize novel classes with few examples. Pre-training based methods effectively tackle the problem by pre-training a feature extractor and then performing class prediction via a cosine classifier with mean-based prototypes. Nevertheless, due to the data scarcity, the mean-based prototypes are usually biased. In this paper, we attempt to diminish the prototype bias by regarding it as a prototype optimization problem. To this end, we propose a novel prototype optimization framework to rectify prototypes, i.e., introducing a meta-optimizer to optimize prototypes. Although the existing meta-optimizers can also be adapted to our framework, they all overlook a crucial gradient bias issue, i.e., the mean-based gradient estimation is also biased on sparse data. To address this issue, in this paper, we regard the gradient and its flow as meta-knowledge and then propose a novel Neural Ordinary Differential Equation (ODE)-based meta-optimizer to optimize prototypes, called MetaNODE. Although MetaNODE has shown superior performance, it suffers from a huge computational burden. To further improve its computation efficiency, we conduct a detailed analysis on MetaNODE and then design an effective and efficient MetaNODE extension version (called E2MetaNODE). It consists of two novel modules: E2GradNet and E2Solver, which aim to estimate accurate gradient flows and solve optimal prototypes in an effective and efficient manner, respectively. Extensive experiments show that 1) our methods achieve superior performance over previous FSL methods and 2) our E2MetaNODE significantly improves computation efficiency meanwhile without performance degradation.
LG-VQ: Language-Guided Codebook Learning
May 23, 2024



Vector quantization (VQ) is a key technique in high-resolution and high-fidelity image synthesis, which aims to learn a codebook to encode an image with a sequence of discrete codes and then generate an image in an auto-regression manner. Although existing methods have shown superior performance, most methods prefer to learn a single-modal codebook (\emph{e.g.}, image), resulting in suboptimal performance when the codebook is applied to multi-modal downstream tasks (\emph{e.g.}, text-to-image, image captioning) due to the existence of modal gaps. In this paper, we propose a novel language-guided codebook learning framework, called LG-VQ, which aims to learn a codebook that can be aligned with the text to improve the performance of multi-modal downstream tasks. Specifically, we first introduce pre-trained text semantics as prior knowledge, then design two novel alignment modules (\emph{i.e.}, Semantic Alignment Module, and Relationship Alignment Module) to transfer such prior knowledge into codes for achieving codebook text alignment. In particular, our LG-VQ method is model-agnostic, which can be easily integrated into existing VQ models. Experimental results show that our method achieves superior performance on reconstruction and various multi-modal downstream tasks.
MCSDNet: Mesoscale Convective System Detection Network via Multi-scale Spatiotemporal Information
Apr 26, 2024



The accurate detection of Mesoscale Convective Systems (MCS) is crucial for meteorological monitoring due to their potential to cause significant destruction through severe weather phenomena such as hail, thunderstorms, and heavy rainfall. However, the existing methods for MCS detection mostly targets on single-frame detection, which just considers the static characteristics and ignores the temporal evolution in the life cycle of MCS. In this paper, we propose a novel encoder-decoder neural network for MCS detection(MCSDNet). MCSDNet has a simple architecture and is easy to expand. Different from the previous models, MCSDNet targets on multi-frames detection and leverages multi-scale spatiotemporal information for the detection of MCS regions in remote sensing imagery(RSI). As far as we know, it is the first work to utilize multi-scale spatiotemporal information to detect MCS regions. Firstly, we design a multi-scale spatiotemporal information module to extract multi-level semantic from different encoder levels, which makes our models can extract more detail spatiotemporal features. Secondly, a Spatiotemporal Mix Unit(STMU) is introduced to MCSDNet to capture both intra-frame features and inter-frame correlations, which is a scalable module and can be replaced by other spatiotemporal module, e.g., CNN, RNN, Transformer and our proposed Dual Spatiotemporal Attention(DSTA). This means that the future works about spatiotemporal modules can be easily integrated to our model. Finally, we present MCSRSI, the first publicly available dataset for multi-frames MCS detection based on visible channel images from the FY-4A satellite. We also conduct several experiments on MCSRSI and find that our proposed MCSDNet achieve the best performance on MCS detection task when comparing to other baseline methods.
A Challenge Dataset and Effective Models for Conversational Stance Detection
Mar 21, 2024



Previous stance detection studies typically concentrate on evaluating stances within individual instances, thereby exhibiting limitations in effectively modeling multi-party discussions concerning the same specific topic, as naturally transpire in authentic social media interactions. This constraint arises primarily due to the scarcity of datasets that authentically replicate real social media contexts, hindering the research progress of conversational stance detection. In this paper, we introduce a new multi-turn conversation stance detection dataset (called \textbf{MT-CSD}), which encompasses multiple targets for conversational stance detection. To derive stances from this challenging dataset, we propose a global-local attention network (\textbf{GLAN}) to address both long and short-range dependencies inherent in conversational data. Notably, even state-of-the-art stance detection methods, exemplified by GLAN, exhibit an accuracy of only 50.47\%, highlighting the persistent challenges in conversational stance detection. Furthermore, our MT-CSD dataset serves as a valuable resource to catalyze advancements in cross-domain stance detection, where a classifier is adapted from a different yet related target. We believe that MT-CSD will contribute to advancing real-world applications of stance detection research. Our source code, data, and models are available at \url{https://github.com/nfq729/MT-CSD}.
Codebook Transfer with Part-of-Speech for Vector-Quantized Image Modeling
Mar 15, 2024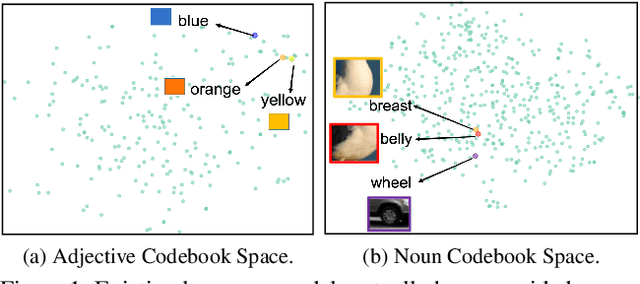

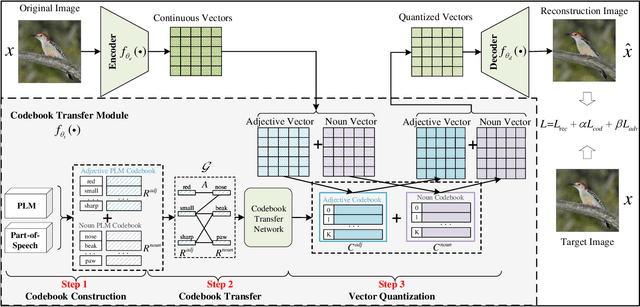
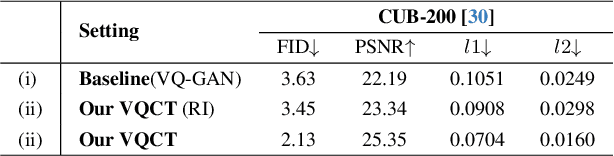
Vector-Quantized Image Modeling (VQIM) is a fundamental research problem in image synthesis, which aims to represent an image with a discrete token sequence. Existing studies effectively address this problem by learning a discrete codebook from scratch and in a code-independent manner to quantize continuous representations into discrete tokens. However, learning a codebook from scratch and in a code-independent manner is highly challenging, which may be a key reason causing codebook collapse, i.e., some code vectors can rarely be optimized without regard to the relationship between codes and good codebook priors such that die off finally. In this paper, inspired by pretrained language models, we find that these language models have actually pretrained a superior codebook via a large number of text corpus, but such information is rarely exploited in VQIM. To this end, we propose a novel codebook transfer framework with part-of-speech, called VQCT, which aims to transfer a well-trained codebook from pretrained language models to VQIM for robust codebook learning. Specifically, we first introduce a pretrained codebook from language models and part-of-speech knowledge as priors. Then, we construct a vision-related codebook with these priors for achieving codebook transfer. Finally, a novel codebook transfer network is designed to exploit abundant semantic relationships between codes contained in pretrained codebooks for robust VQIM codebook learning. Experimental results on four datasets show that our VQCT method achieves superior VQIM performance over previous state-of-the-art methods.