 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCast: A Unified Framework via Residual Diffusion for Precipitation Nowcasting
Dec 11, 2023



Precipitation nowcasting is an important spatio-temporal prediction task to predict the radar echoes sequences based on current observations, which can serve both meteorological science and smart city applications. Due to the chaotic evolution nature of the precipitation systems, it is a very challenging problem. Previous studies address the problem either from the perspectives of deterministic modeling or probabilistic modeling. However, their predictions suffer from the blurry, high-value echoes fading away and position inaccurate issues. The root reason of these issues is that the chaotic evolutionary precipitation systems are not appropriately modeled. Inspired by the nature of the systems, we propose to decompose and model them from the perspective of global deterministic motion and local stochastic variations with residual mechanism. A unified and flexible framework that can equip any type of spatio-temporal models is proposed based on residual diffusion, which effectively tackles the shortcomings of previous methods. Extensive experimental results on four publicly available radar datasets demonstrate the effectiveness and superiority of the proposed framework, compared to state-of-the-art techniques. Our code will be made publicly available soon.
TempEE: Temporal-Spatial Parallel Transformer for Radar Echo Extrapolation Beyond Auto-Regression
Apr 27, 2023



The meteorological radar reflectivity data, also known as echo, plays a crucial role in predicting precipitation and enabling accurate and fast forecasting of short-term heavy rainfall without the need for complex Numerical Weather Prediction (NWP) model. Compared to conventional model, Deep Learning (DL)-based radar echo extrapolation algorithms are more effective and efficient. However, the development of highly reliable and generalized algorithms is hindered by three main bottlenecks: cumulative error spreading, imprecise representation of sparse echo distribution, and inaccurate description of non-stationary motion process. To address these issues, this paper presents a novel radar echo extrapolation algorithm that utilizes temporal-spatial correlation features and the Transformer technology. The algorithm extracts features from multi-frame echo images that accurately represent non-stationary motion processes for precipitation prediction. The proposed algorithm uses a novel parallel encoder based on Transformer technology to effectively and automatically extract echoes' temporal-spatial features. Furthermore, a Multi-level Temporal-Spatial attention mechanism is adopted to enhance the ability to perceive global-local information and highlight the task-related feature regions in a lightweight way. The proposed method's effectiveness has been valided on the classic radar echo extrapolation task using the real-world dataset. Numerous experiments have further demonstrated the effectiveness and necessity of various components of the proposed method.
MIMO Is All You Need : A Strong Multi-In-Multi-Out Baseline for Video Prediction
Dec 09, 2022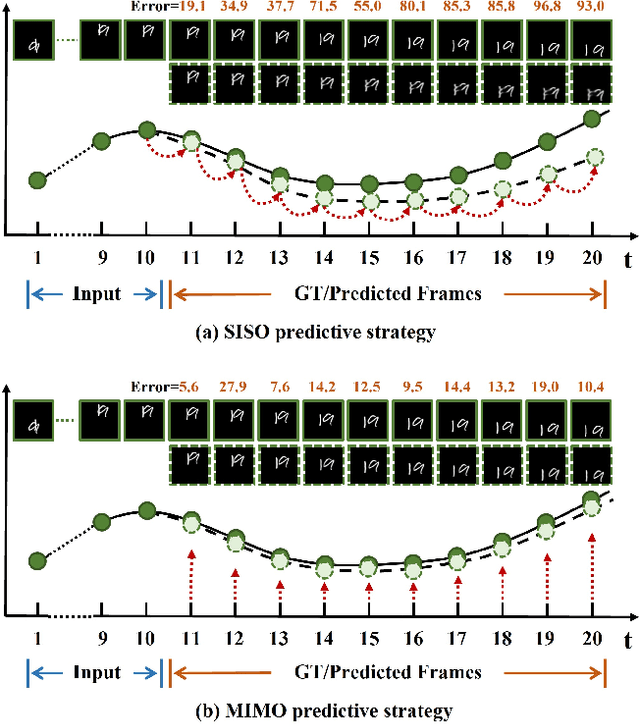
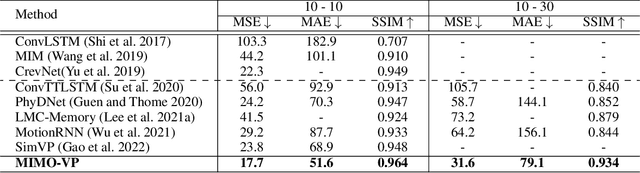
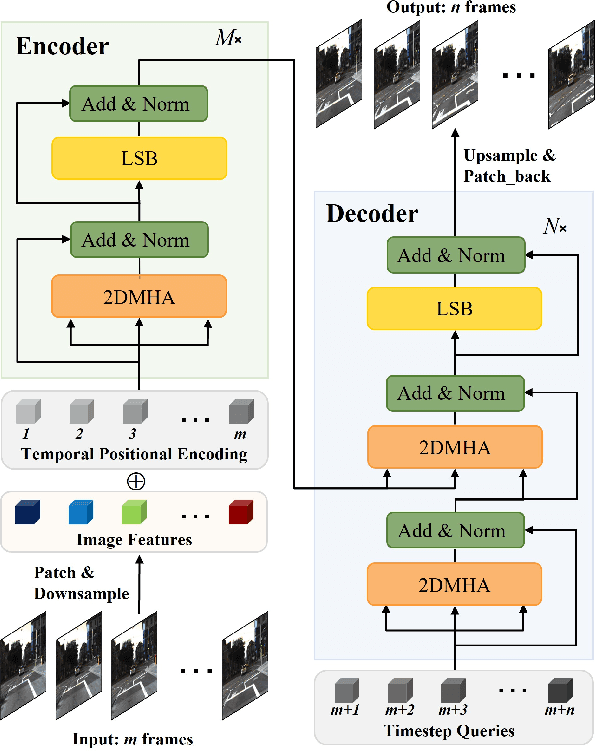

The mainstream of the existing approaches for video prediction builds up their models based on a Single-In-Single-Out (SISO) architecture, which takes the current frame as input to predict the next frame in a recursive manner. This way often leads to severe performance degradation when they try to extrapolate a longer period of future, thus limiting the practical use of the prediction model. Alternatively, a Multi-In-Multi-Out (MIMO) architecture that outputs all the future frames at one shot naturally breaks the recursive manner and therefore prevents error accumulation. However, only a few MIMO models for video prediction are proposed and they only achieve inferior performance due to the date. The real strength of the MIMO model in this area is not well noticed and is largely under-explored. Motivated by that, we conduct a comprehensive investigation in this paper to thoroughly exploit how far a simple MIMO architecture can go. Surprisingly, our empirical studies reveal that a simple MIMO model can outperform the state-of-the-art work with a large margin much more than expected, especially in dealing with longterm error accumulation. After exploring a number of ways and designs, we propose a new MIMO architecture based on extending the pure Transformer with local spatio-temporal blocks and a new multi-output decoder, namely MIMO-VP, to establish a new standard in video prediction. We evaluate our model in four highly competitive benchmarks (Moving MNIST, Human3.6M, Weather, KITTI). Extensive experiments show that our model wins 1st place on all the benchmarks with remarkable performance gains and surpasses the best SISO model in all aspects including efficiency, quantity, and quality. We believe our model can serve as a new baseline to facilitate the future research of video prediction tasks. The code will be released.
From Single to Multiple: Leveraging Multi-level Prediction Spaces for Video Forecasting
Jul 21, 2021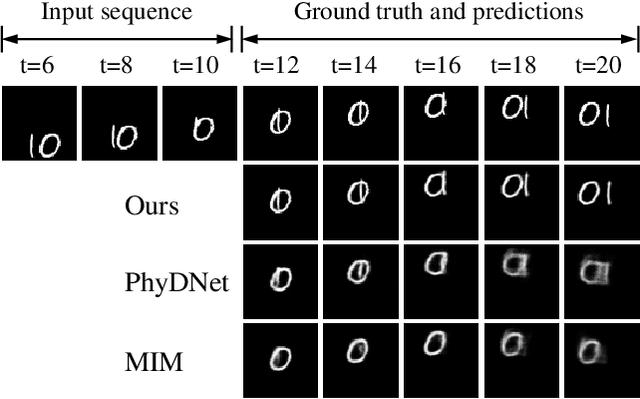
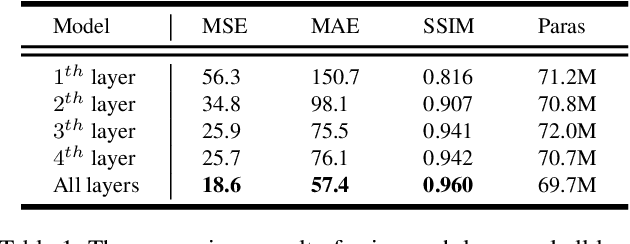
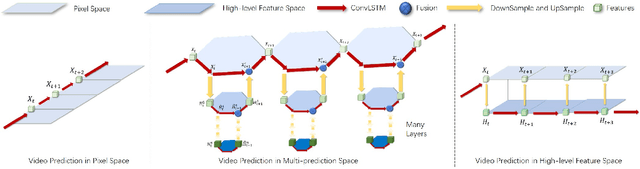
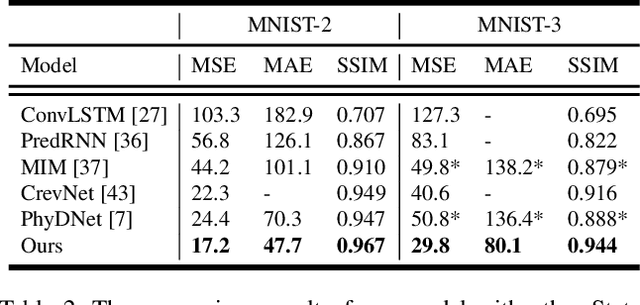
Despite video forecasting has been a widely explored topic in recent years, the mainstream of the existing work still limits their models with a single prediction space but completely neglects the way to leverage their model with multi-prediction spaces. This work fills this gap. For the first time, we deeply study numerous strategies to perform video forecasting in multi-prediction spaces and fuse their results together to boost performance. The prediction in the pixel space usually lacks the ability to preserve the semantic and structure content of the video however the prediction in the high-level feature space is prone to generate errors in the reduction and recovering process. Therefore, we build a recurrent connection between different feature spaces and incorporate their generations in the upsampling process. Rather surprisingly, this simple idea yields a much more significant performance boost than PhyDNet (performance improved by 32.1% MAE on MNIST-2 dataset, and 21.4% MAE on KTH dataset). Both qualitative and quantitative evaluations on four datasets demonstrate the generalization ability and effectiveness of our approach. We show that our model significantly reduces the troublesome distortions and blurry artifacts and brings remarkable improvements to the accuracy in long term video prediction. The code will be released soon.