 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSJD-VP: Speculative Jacobi Decoding with Verification Prediction for Autoregressive Image Generation
Mar 28, 2026Speculative Jacobi Decoding (SJD) has emerged as a promising method for accelerating autoregressive image generation. Despite its potential, existing SJD approaches often suffer from the low acceptance rate issue of speculative tokens due to token selection ambiguity. Recent works attempt to mitigate this issue primarily from the relaxed token verification perspective but fail to fully exploit the iterative dynamics of decoding. In this paper, we conduct an in-depth analysis and make a novel observation that tokens whose probabilities increase are more likely to match the verification-accepted and correct token. Based on this, we propose a novel Speculative Jacobi Decoding with Verification Prediction (SJD-VP). The key idea is to leverage the change in token probabilities across iterations to guide sampling, favoring tokens whose probabilities increase. This effectively predicts which tokens are likely to pass subsequent verification, boosting the acceptance rate. In particular, our SJD-VP is plug-and-play and can be seamlessly integrated into existing SJD methods. Extensive experiments on standard benchmarks demonstrate that our SJD-VP method consistently accelerates autoregressive decoding while improving image generation quality.
PointLAMA: Latent Attention meets Mamba for Efficient Point Cloud Pretraining
Jul 23, 2025Mamba has recently gained widespread attention as a backbone model for point cloud modeling, leveraging a state-space architecture that enables efficient global sequence modeling with linear complexity. However, its lack of local inductive bias limits its capacity to capture fine-grained geometric structures in 3D data. To address this limitation, we propose \textbf{PointLAMA}, a point cloud pretraining framework that combines task-aware point cloud serialization, a hybrid encoder with integrated Latent Attention and Mamba blocks, and a conditional diffusion mechanism built upon the Mamba backbone. Specifically, the task-aware point cloud serialization employs Hilbert/Trans-Hilbert space-filling curves and axis-wise sorting to structurally align point tokens for classification and segmentation tasks, respectively. Our lightweight Latent Attention block features a Point-wise Multi-head Latent Attention (PMLA) module, which is specifically designed to align with the Mamba architecture by leveraging the shared latent space characteristics of PMLA and Mamba. This enables enhanced local context modeling while preserving overall efficiency. To further enhance representation learning, we incorporate a conditional diffusion mechanism during pretraining, which denoises perturbed feature sequences without relying on explicit point-wise reconstruction. Experimental results demonstrate that PointLAMA achieves competitive performance on multiple benchmark datasets with minimal parameter count and FLOPs, validating its effectiveness for efficient point cloud pretraining.
From Text to Time? Rethinking the Effectiveness of the Large Language Model for Time Series Forecasting
Apr 09, 2025Using pre-trained large language models (LLMs) as the backbone for time series prediction has recently gained significant research interest. However, the effectiveness of LLM backbones in this domain remains a topic of debate. Based on thorough empirical analyses, we observe that training and testing LLM-based models on small datasets often leads to the Encoder and Decoder becoming overly adapted to the dataset, thereby obscuring the true predictive capabilities of the LLM backbone. To investigate the genuine potential of LLMs in time series prediction, we introduce three pre-training models with identical architectures but different pre-training strategies. Thereby, large-scale pre-training allows us to create unbiased Encoder and Decoder components tailored to the LLM backbone. Through controlled experiments, we evaluate the zero-shot and few-shot prediction performance of the LLM, offering insights into its capabilities. Extensive experiments reveal that although the LLM backbone demonstrates some promise, its forecasting performance is limited. Our source code is publicly available in the anonymous repository: https://anonymous.4open.science/r/LLM4TS-0B5C.
Prototype Optimization with Neural ODE for Few-Shot Learning
Nov 19, 2024Few-Shot Learning (FSL) is a challenging task, which aims to recognize novel classes with few examples. Pre-training based methods effectively tackle the problem by pre-training a feature extractor and then performing class prediction via a cosine classifier with mean-based prototypes. Nevertheless, due to the data scarcity, the mean-based prototypes are usually biased. In this paper, we attempt to diminish the prototype bias by regarding it as a prototype optimization problem. To this end, we propose a novel prototype optimization framework to rectify prototypes, i.e., introducing a meta-optimizer to optimize prototypes. Although the existing meta-optimizers can also be adapted to our framework, they all overlook a crucial gradient bias issue, i.e., the mean-based gradient estimation is also biased on sparse data. To address this issue, in this paper, we regard the gradient and its flow as meta-knowledge and then propose a novel Neural Ordinary Differential Equation (ODE)-based meta-optimizer to optimize prototypes, called MetaNODE. Although MetaNODE has shown superior performance, it suffers from a huge computational burden. To further improve its computation efficiency, we conduct a detailed analysis on MetaNODE and then design an effective and efficient MetaNODE extension version (called E2MetaNODE). It consists of two novel modules: E2GradNet and E2Solver, which aim to estimate accurate gradient flows and solve optimal prototypes in an effective and efficient manner, respectively. Extensive experiments show that 1) our methods achieve superior performance over previous FSL methods and 2) our E2MetaNODE significantly improves computation efficiency meanwhile without performance degradation.
LG-VQ: Language-Guided Codebook Learning
May 23, 2024



Vector quantization (VQ) is a key technique in high-resolution and high-fidelity image synthesis, which aims to learn a codebook to encode an image with a sequence of discrete codes and then generate an image in an auto-regression manner. Although existing methods have shown superior performance, most methods prefer to learn a single-modal codebook (\emph{e.g.}, image), resulting in suboptimal performance when the codebook is applied to multi-modal downstream tasks (\emph{e.g.}, text-to-image, image captioning) due to the existence of modal gaps. In this paper, we propose a novel language-guided codebook learning framework, called LG-VQ, which aims to learn a codebook that can be aligned with the text to improve the performance of multi-modal downstream tasks. Specifically, we first introduce pre-trained text semantics as prior knowledge, then design two novel alignment modules (\emph{i.e.}, Semantic Alignment Module, and Relationship Alignment Module) to transfer such prior knowledge into codes for achieving codebook text alignment. In particular, our LG-VQ method is model-agnostic, which can be easily integrated into existing VQ models. Experimental results show that our method achieves superior performance on reconstruction and various multi-modal downstream tasks.
MCSDNet: Mesoscale Convective System Detection Network via Multi-scale Spatiotemporal Information
Apr 26, 2024



The accurate detection of Mesoscale Convective Systems (MCS) is crucial for meteorological monitoring due to their potential to cause significant destruction through severe weather phenomena such as hail, thunderstorms, and heavy rainfall. However, the existing methods for MCS detection mostly targets on single-frame detection, which just considers the static characteristics and ignores the temporal evolution in the life cycle of MCS. In this paper, we propose a novel encoder-decoder neural network for MCS detection(MCSDNet). MCSDNet has a simple architecture and is easy to expand. Different from the previous models, MCSDNet targets on multi-frames detection and leverages multi-scale spatiotemporal information for the detection of MCS regions in remote sensing imagery(RSI). As far as we know, it is the first work to utilize multi-scale spatiotemporal information to detect MCS regions. Firstly, we design a multi-scale spatiotemporal information module to extract multi-level semantic from different encoder levels, which makes our models can extract more detail spatiotemporal features. Secondly, a Spatiotemporal Mix Unit(STMU) is introduced to MCSDNet to capture both intra-frame features and inter-frame correlations, which is a scalable module and can be replaced by other spatiotemporal module, e.g., CNN, RNN, Transformer and our proposed Dual Spatiotemporal Attention(DSTA). This means that the future works about spatiotemporal modules can be easily integrated to our model. Finally, we present MCSRSI, the first publicly available dataset for multi-frames MCS detection based on visible channel images from the FY-4A satellite. We also conduct several experiments on MCSRSI and find that our proposed MCSDNet achieve the best performance on MCS detection task when comparing to other baseline methods.
Four-hour thunderstorm nowcasting using deep diffusion models of satellite
Apr 16, 2024



Convection (thunderstorm) develops rapidly within hours and is highly destructive, posing a significant challenge for nowcasting and resulting in substantial losses to nature and society. After the emergence of artificial intelligence (AI)-based methods, convection nowcasting has experienced rapid advancements, with its performance surpassing that of physics-based numerical weather prediction and other conventional approaches. However, the lead time and coverage of it still leave much to be desired and hardly meet the needs of disaster emergency response. Here, we propose a deep diffusion model of satellite (DDMS) to establish an AI-based convection nowcasting system. On one hand, it employs diffusion processes to effectively simulate complicated spatiotemporal evolution patterns of convective clouds, significantly improving the forecast lead time. On the other hand, it utilizes geostationary satellite brightness temperature data, thereby achieving planetary-scale forecast coverage. During long-term tests and objective validation based on the FengYun-4A satellite, our system achieves, for the first time, effective convection nowcasting up to 4 hours, with broad coverage (about 20,000,000 km2), remarkable accuracy, and high resolution (15 minutes; 4 km). Its performance reaches a new height in convection nowcasting compared to the existing models. In terms of application, our system operates efficiently (forecasting 4 hours of convection in 8 minutes), and is highly transferable with the potential to collaborate with multiple satellites for global convection nowcasting. Furthermore, our results highlight the remarkable capabilities of diffusion models in convective clouds forecasting, as well as the significant value of geostationary satellite data when empowered by AI technologies.
Codebook Transfer with Part-of-Speech for Vector-Quantized Image Modeling
Mar 15, 2024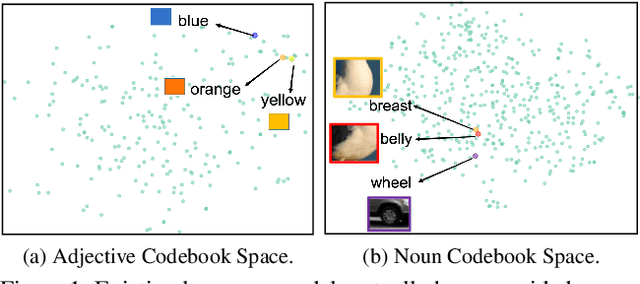

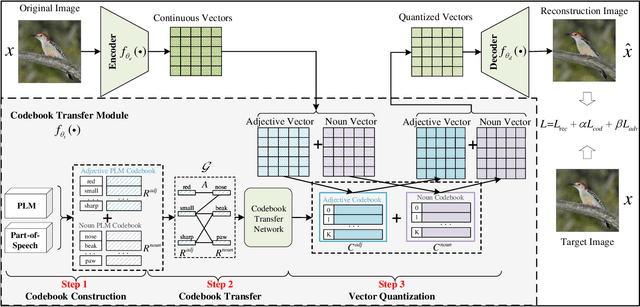
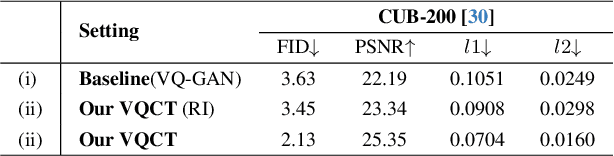
Vector-Quantized Image Modeling (VQIM) is a fundamental research problem in image synthesis, which aims to represent an image with a discrete token sequence. Existing studies effectively address this problem by learning a discrete codebook from scratch and in a code-independent manner to quantize continuous representations into discrete tokens. However, learning a codebook from scratch and in a code-independent manner is highly challenging, which may be a key reason causing codebook collapse, i.e., some code vectors can rarely be optimized without regard to the relationship between codes and good codebook priors such that die off finally. In this paper, inspired by pretrained language models, we find that these language models have actually pretrained a superior codebook via a large number of text corpus, but such information is rarely exploited in VQIM. To this end, we propose a novel codebook transfer framework with part-of-speech, called VQCT, which aims to transfer a well-trained codebook from pretrained language models to VQIM for robust codebook learning. Specifically, we first introduce a pretrained codebook from language models and part-of-speech knowledge as priors. Then, we construct a vision-related codebook with these priors for achieving codebook transfer. Finally, a novel codebook transfer network is designed to exploit abundant semantic relationships between codes contained in pretrained codebooks for robust VQIM codebook learning. Experimental results on four datasets show that our VQCT method achieves superior VQIM performance over previous state-of-the-art methods.
DiffCast: A Unified Framework via Residual Diffusion for Precipitation Nowcasting
Dec 11, 2023



Precipitation nowcasting is an important spatio-temporal prediction task to predict the radar echoes sequences based on current observations, which can serve both meteorological science and smart city applications. Due to the chaotic evolution nature of the precipitation systems, it is a very challenging problem. Previous studies address the problem either from the perspectives of deterministic modeling or probabilistic modeling. However, their predictions suffer from the blurry, high-value echoes fading away and position inaccurate issues. The root reason of these issues is that the chaotic evolutionary precipitation systems are not appropriately modeled. Inspired by the nature of the systems, we propose to decompose and model them from the perspective of global deterministic motion and local stochastic variations with residual mechanism. A unified and flexible framework that can equip any type of spatio-temporal models is proposed based on residual diffusion, which effectively tackles the shortcomings of previous methods. Extensive experimental results on four publicly available radar datasets demonstrate the effectiveness and superiority of the proposed framework, compared to state-of-the-art techniques. Our code will be made publicly available soon.
HPCR: Holistic Proxy-based Contrastive Replay for Online Continual Learning
Sep 26, 2023Online continual learning (OCL) aims to continuously learn new data from a single pass over the online data stream. It generally suffers from the catastrophic forgetting issue. Existing replay-based methods effectively alleviate this issue by replaying part of old data in a proxy-based or contrastive-based replay manner. In this paper, we conduct a comprehensive analysis of these two replay manners and find they can be complementary. Inspired by this finding, we propose a novel replay-based method called proxy-based contrastive replay (PCR), which replaces anchor-to-sample pairs with anchor-to-proxy pairs in the contrastive-based loss to alleviate the phenomenon of forgetting. Based on PCR, we further develop a more advanced method named holistic proxy-based contrastive replay (HPCR), which consists of three components. The contrastive component conditionally incorporates anchor-to-sample pairs to PCR, learning more fine-grained semantic information with a large training batch. The second is a temperature component that decouples the temperature coefficient into two parts based on their impacts on the gradient and sets different values for them to learn more novel knowledge. The third is a distillation component that constrains the learning process to keep more historical knowledge. Experiments on four datasets consistently demonstrate the superiority of HPCR over various state-of-the-art methods.