 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSJD-VP: Speculative Jacobi Decoding with Verification Prediction for Autoregressive Image Generation
Mar 28, 2026Speculative Jacobi Decoding (SJD) has emerged as a promising method for accelerating autoregressive image generation. Despite its potential, existing SJD approaches often suffer from the low acceptance rate issue of speculative tokens due to token selection ambiguity. Recent works attempt to mitigate this issue primarily from the relaxed token verification perspective but fail to fully exploit the iterative dynamics of decoding. In this paper, we conduct an in-depth analysis and make a novel observation that tokens whose probabilities increase are more likely to match the verification-accepted and correct token. Based on this, we propose a novel Speculative Jacobi Decoding with Verification Prediction (SJD-VP). The key idea is to leverage the change in token probabilities across iterations to guide sampling, favoring tokens whose probabilities increase. This effectively predicts which tokens are likely to pass subsequent verification, boosting the acceptance rate. In particular, our SJD-VP is plug-and-play and can be seamlessly integrated into existing SJD methods. Extensive experiments on standard benchmarks demonstrate that our SJD-VP method consistently accelerates autoregressive decoding while improving image generation quality.
AsyncDSB: Schedule-Asynchronous Diffusion Schrödinger Bridge for Image Inpainting
Dec 11, 2024

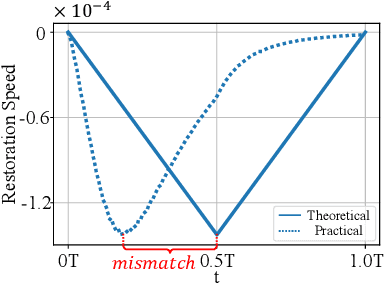
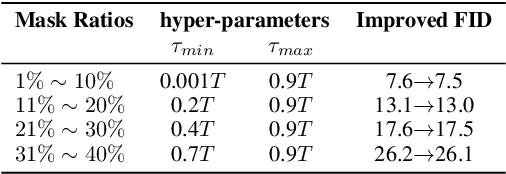
Image inpainting is an important image generation task, which aims to restore corrupted image from partial visible area. Recently, diffusion Schr\"odinger bridge methods effectively tackle this task by modeling the translation between corrupted and target images as a diffusion Schr\"odinger bridge process along a noising schedule path. Although these methods have shown superior performance, in this paper, we find that 1) existing methods suffer from a schedule-restoration mismatching issue, i.e., the theoretical schedule and practical restoration processes usually exist a large discrepancy, which theoretically results in the schedule not fully leveraged for restoring images; and 2) the key reason causing such issue is that the restoration process of all pixels are actually asynchronous but existing methods set a synchronous noise schedule to them, i.e., all pixels shares the same noise schedule. To this end, we propose a schedule-Asynchronous Diffusion Schr\"odinger Bridge (AsyncDSB) for image inpainting. Our insight is preferentially scheduling pixels with high frequency (i.e., large gradients) and then low frequency (i.e., small gradients). Based on this insight, given a corrupted image, we first train a network to predict its gradient map in corrupted area. Then, we regard the predicted image gradient as prior and design a simple yet effective pixel-asynchronous noise schedule strategy to enhance the diffusion Schr\"odinger bridge. Thanks to the asynchronous schedule at pixels, the temporal interdependence of restoration process between pixels can be fully characterized for high-quality image inpainting. Experiments on real-world datasets show that our AsyncDSB achieves superior performance, especially on FID with around 3% - 14% improvement over state-of-the-art baseline methods.
Codebook Transfer with Part-of-Speech for Vector-Quantized Image Modeling
Mar 15, 2024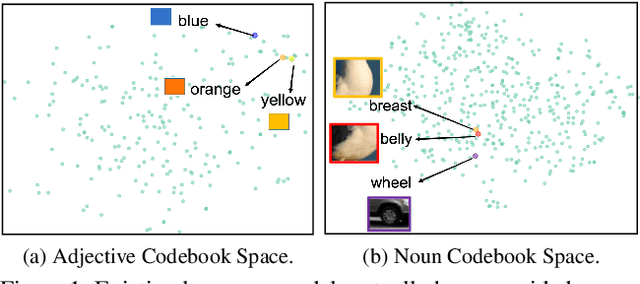

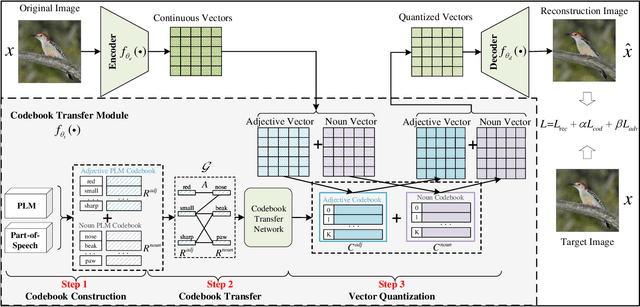
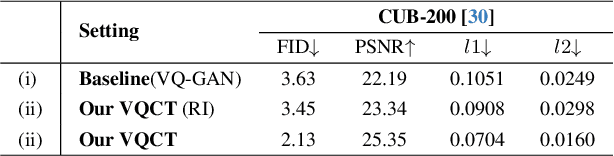
Vector-Quantized Image Modeling (VQIM) is a fundamental research problem in image synthesis, which aims to represent an image with a discrete token sequence. Existing studies effectively address this problem by learning a discrete codebook from scratch and in a code-independent manner to quantize continuous representations into discrete tokens. However, learning a codebook from scratch and in a code-independent manner is highly challenging, which may be a key reason causing codebook collapse, i.e., some code vectors can rarely be optimized without regard to the relationship between codes and good codebook priors such that die off finally. In this paper, inspired by pretrained language models, we find that these language models have actually pretrained a superior codebook via a large number of text corpus, but such information is rarely exploited in VQIM. To this end, we propose a novel codebook transfer framework with part-of-speech, called VQCT, which aims to transfer a well-trained codebook from pretrained language models to VQIM for robust codebook learning. Specifically, we first introduce a pretrained codebook from language models and part-of-speech knowledge as priors. Then, we construct a vision-related codebook with these priors for achieving codebook transfer. Finally, a novel codebook transfer network is designed to exploit abundant semantic relationships between codes contained in pretrained codebooks for robust VQIM codebook learning. Experimental results on four datasets show that our VQCT method achieves superior VQIM performance over previous state-of-the-art methods.